Practical Applications of Chatbot
Knowledge Graph Part 2: Information Extraction
Last Updated: 2025/05/06
王柳鋐
文本分析
Basis of Knowledge Graph: Text Analysis
文本分析基本任務: 斷詞、詞性標記、實體辨識
"我和順仔早上5點登上「福建號」"
我和<person>順仔</person>早上5點登上「<ship>福建號</ship>」
斷詞(tagger)
(命名)實體辨識NER
name-entity-recognition
原文
我 和 順仔 早上 5點 登上 福建號
r c nr t t v nr
詞性標記PoS
part-of-speech
專業術語 + 分類
應用:索引、Hyperlink
中文文本分析開發工具

中文文本分析開發工具2018之後


BERT
Bidirectional Encoder Representations from Transformers
中文文本分析開發工具2018之後


文本分析的困難之處(1/3)
拜訪 我 普林斯 頓 神學院 的 老同 學麥克 切斯 尼 先生 和 幾位 宣教 師 。 晚上 介紹 加拿大 , 哈巴 安德 醫師 翻譯
斷詞
困難: 斷詞錯誤 雜訊
"拜訪我普林斯頓(Princeton)神學院的老同學麥克切斯尼(McChesney)先生和幾位宣教師。晚上介紹加拿大,哈巴安德醫師翻譯。"
Icons made by Freepik from www.flaticon.com
Icons made by Eucalyp from www.flaticon.com

自訂辭典

停用字列表
普林斯頓
老同學
麥克切斯尼先生
哈巴安德醫師
宣教師
我
的
和
晚上
幾位
拜訪 普林斯頓 神學院 老同學 麥克切斯尼先生 宣教師 。 介紹 加拿大 , 哈巴安德醫師 翻譯
困難: 錯別字、同義詞(不同稱呼/不同翻譯)
Icons made by Eucalyp from www.flaticon.com

拜訪南勢番(南方的原住民),在包干、李流(Li-lau),薄薄、斗蘭(Tau-lan)和七腳川拍了一些照片。

台灣堡圖
1904
我們拜訪流流、薄薄、里腦,又回到大社
問題:究竟是里腦,李流還是流流?
不同翻譯
回到五股坑,蔥仔在前往領事館費里德(A.Frater)先生那裡後和我們一起。
和偕師母及閏虔益一起到五股坑,然後去洲裡,在晚上回來。
同義詞
專家
修正與建議
里漏社
自訂辭典
停用字列表
文本分析的困難之處(2/3)
訓練資料很難取得


文本分析的困難之處(3/3)
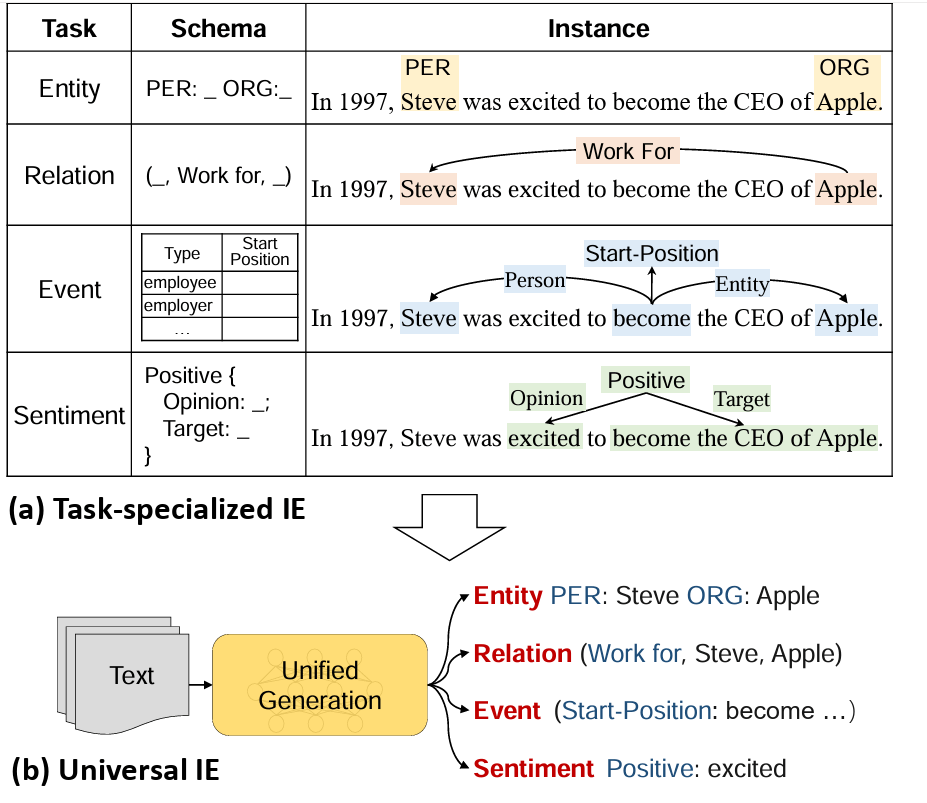
通用資訊擷取
Universal Information Extraction (UIE)
Universal IE
Universal Information Extraction(UIE,通用資訊擷取)
適用於多種任務、與多樣資料格式的統一模型或框架。
這些任務可能包括:
-
命名實體辨識(Named Entity Recognition, NER)
-
關係擷取(Relation Extraction, RE)
-
事件擷取(Event Extraction)
-
屬性擷取(Attribute Extraction)
-
情感/意圖識別(Sentiment/Intent Extraction)
-
半結構化資料的擷取(semi-structured sources like tables, forms)
「2024年,台積電在美國亞利桑那州設立了新晶圓廠。」
例句:
🟩 命名實體辨識(NER)
有意義的「實體」類別,例如人名、地名、組織名、時間等。
🔍 結果:
台積電 → ORG(組織)
美國亞利桑那州 → LOC(地點)
2024年 → DATE(時間)
NER 是基礎任務,通常其他任務都會依賴它的結果。
NER/關係擷取/事件擷取/屬性擷取
「2024年,台積電在美國亞利桑那州設立了新晶圓廠。」
例句:
🟦 關係擷取(Relation Extraction, RE)
在實體之間建立語意關係,如誰屬於誰、誰在何處、誰做了什麼
🔍 結果:
(台積電, 設廠地點, 美國亞利桑那州)
(事件時間, 設廠, 2024年)
系統需理解哪些實體之間存在特定語義上的「關聯」
NER/關係擷取/事件擷取/屬性擷取
🟨 事件擷取(Event Extraction, EE)
辨識事件的觸發詞(trigger)與其相關角色(arguments)
像是誰做了什麼、在什麼時間、在哪裡等。
🔍 結果:
- 事件類型:設廠(建設/擴張型事件)
- 觸發詞:設立
- 角色參數:
- 主體(Agent):台積電
- 地點(Place):美國亞利桑那州
- 時間(Time):2024年
- 設施(Facility):新晶圓廠
這類任務通常會搭配「事件結構模板」,較接近語意理解。
NER/關係擷取/事件擷取/屬性擷取
🟧 屬性擷取(Attribute Extraction)
擷取產品資訊、知識圖譜、評論分析中的特定屬性或描述
例句:
「這間晶圓廠的產能為每月4萬片,專門生產3奈米晶片。」
🔍 結果:
產能:每月4萬片
製程技術:3奈米
用途:生產晶片
對象(主體):這間晶圓廠
NER/關係擷取/事件擷取/屬性擷取
📌 總結比較
任務類型 問題定義 結果範例
| NER | 實體是誰?在哪?是什麼? | 台積電:ORG、亞利桑那州:LOC |
| RE | 實體之間有什麼關係? | 台積電 → 設廠地點 → 美國亞利桑那州 |
| EE | 發生了什麼事件?誰參與? | 設立事件,主體:台積電,地點:亞利桑那 |
| 屬性擷取 | 對象有哪些屬性? | 晶圓廠 → 產能:4萬片/月,製程:3奈米 |
NER/關係擷取/事件擷取/屬性擷取
Ckip Transformers安裝與使用

Ckip Transformers安裝與使用
使用方法ㄧ: 透過HuggingFace Transformers
圖片來源:Transformers, PyTorch, TensorFlow
pip install -U transformers❶ 安裝transformers套件
❷ 安裝深度學習套件(擇一)
pip install -U torchpip install -U tensorflow


* 後續以PyTorch為例
Ckip Transformers安裝與使用
使用方法二: CKIP_Transformers
圖片來源:Transformers, PyTorch, TensorFlow
pip install -U ckip-transformerspip install -U torch* 後續以PyTorch為例
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
## 將斷詞結果words與 part-of-speech結果pos打包在一起
def pack_ws_pos_sentece(words, pos):
assert len(words) == len(pos), f'words{len(words)}和pos{len(pos)}長度必須一樣'
result = [] # 最終結果串列
for word, p in zip(words, pos): # zip將words,pos對應位置鏈在一起
result.append(f"{word}({p})")
return "\u3000".join(result) #\u3000是全形空白字元
# Input text
text = [
"華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。",
"相當涼爽舒適,與阿華出去鄉間拜訪他的一位老朋友,是一位農人。我們被看見,認出來,且受排斥。遭到兩隻大黑狗攻擊,孩童吼叫,狂暴的辱罵。 我們回家,在吃過飯之後,我們比過去更勤奮的研讀各自的功課。",
"華氏84度,陰天,氣壓30-10。上午七點離開大里簡,大部分都用走的,上午時點三十分來到頭城,拔了一些牙。十一點到打馬煙,我們剛到雨就來了。禮德醫師在路上幫一個傢伙縫手指。新漆好的禮拜堂到處都是用藍色和紅色漆,全部由他們自費花了十二元。禮德醫師拍團體照。我們照顧了十四名病人,還拔了一些牙。主持聖餐禮,聆聽十七個人背誦。大家都做得很好,我們發禮物給他們。"
]
ws_driver = CkipWordSegmenter(model="bert-base") # 載入 斷詞模型
pos_driver = CkipPosTagger(model="bert-base") # 載入 POS模型
ner_driver = CkipNerChunker(model="bert-base") # 載入 實體辨識模型
print('all loaded...')
# 執行pipeline 產生結果
ws = ws_driver(text) # 斷詞
pos = pos_driver(ws) # 詞性: 注意斷詞-詞性是依序完成
ner = ner_driver(text) # 實體辨識
##列印結果
for sentence, word, p, n in zip(text, ws, pos, ner):
print(sentence)
print(pack_ws_pos_sentece(word, p))
for token in n:
print(f"({token.idx[0]}, {token.idx[1]}, '{token.ner}', '{token.word}')")
print()華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。
華氏(Na) 80(Neu) 度(Nf) ,(COMMACATEGORY) 氣壓(Na) 30-6(Neu) ,(COMMACATEGORY) 整(Neqa) 天(Nf) 下雨(VA) 。(PERIODCATEGORY) 前進(VA) 到(P) 奇武荖(Nc) ,(COMMACATEGORY) 聆聽(VC) 朗誦(VC) 。(PERIODCATEGORY) 然後(D) 珍珠里簡(Na) 和(Caa) 冬瓜山(Nc) ,(COMMACATEGORY) 晚間(Nd) 在(P) 珍珠里簡(Nc) 的(DE) 禮拜(Na) 有(V_2) 一百五十(Neu) 人(Na) ,(COMMACATEGORY) 拔(VC) 了(Di) 七十六(Neu) 顆(Nf) 牙(Na) 。(PERIODCATEGORY)
(0, 5, 'QUANTITY', '華氏80度')
(8, 12, 'QUANTITY', '30-6')
(37, 40, 'LOC', '冬瓜山')
(41, 43, 'TIME', '晚間')
(52, 56, 'CARDINAL', '一百五十')
(60, 63, 'CARDINAL', '七十六')
實體辨識
11類專有名詞
7類數量詞
Part-of-Speech(POS)
61種詞性

華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。
華氏(Na) 80(Neu) 度(Nf) ,(COMMACATEGORY) 氣壓(Na) 30-6(Neu) ,(COMMACATEGORY) 整(Neqa) 天(Nf) 下雨(VA) 。(PERIODCATEGORY) 前進(VA) 到(P) 奇武荖(Nc) ,(COMMACATEGORY) 聆聽(VC) 朗誦(VC) 。(PERIODCATEGORY) 然後(D) 珍珠里簡(Na) 和(Caa) 冬瓜山(Nc) ,(COMMACATEGORY) 晚間(Nd) 在(P) 珍珠里簡(Nc) 的(DE) 禮拜(Na) 有(V_2) 一百五十(Neu) 人(Na) ,(COMMACATEGORY) 拔(VC) 了(Di) 七十六(Neu) 顆(Nf) 牙(Na) 。(PERIODCATEGORY)
(0, 5, 'QUANTITY', '華氏80度')
(8, 12, 'QUANTITY', '30-6')
(37, 40, 'LOC', '冬瓜山')
(41, 43, 'TIME', '晚間')
(52, 56, 'CARDINAL', '一百五十')
(60, 63, 'CARDINAL', '七十六')
只辨識出1個實體
且分類錯誤
應為GPE
3個地名,共出現四次
珍珠里簡: 不同詞性?
Na:普通名詞,Nc: 地方詞
Universal IE continue
🧠 核心概念
UIE 的目標是建構一個不同任務和領域的通用模型
UIE 強調:
-
任務無關性:不需為不同任務設計不同模型
-
資料格式通用性:能處理文本、表格、HTML 等格式。
-
少樣本學習能力(few-shot / zero-shot learning)
-
即使在新任務或新資料上也能快速適應。
-
Universal IE methodology
🔧 方法與技術
-
序列到序列(Seq2Seq)框架
-
轉換成文字生成任務。例如,把「從句子中取出人名」變成「輸入:句子 + 指令,輸出:人名」。
-
代表模型:T5, BART 等。
-
-
Prompt-based Learning(提示學習)
-
使用自然語言提示引導模型完成不同的抽取任務,常結合大型語言模型(如 GPT 系列、ChatGPT、T5、FLAN-T5)。
-
-
Unified Schema/Framework
-
如 OneIE、UIE、SpERT(Span-based Entity and Relation Transformer)等,把所有任務轉化為統一的「標註問題」。
-
-
多任務學習(Multi-task Learning)
-
訓練一個模型解決多種任務,有助於學到更一般化的表示。
-
Universal IE methodology
🔬 代表性研究與模型
名稱 發表單位 年份 特點
|
Alibaba |
2022 |
提出 prompt-based 的 unified schema,支援多種任務(NER、RE、Event)。 |
|
|
OneIE |
Columbia University |
2020 |
將多任務建模視為 span-based sequence labeling 任務。 |
|
SpERT |
IBM Research |
2020 |
使用 transformer 擷取實體與關係,統一架構下進行 span prediction。 |
|
Text2Event |
THU(清華) |
2021 |
將事件擷取建模為序列生成任務。 |
|
TIE (Text-in-Text) |
Facebook AI |
2021 |
將所有任務統一成「子文字擷取」的問題。 |
Universal IE methodology
Universal IE Implementation

pip install paddlepaddle==2.6.1非GPU版本
pip install -U paddlenlpfrom paddlenlp.transformers import AutoTokenizer, AutoModelForTokenClassification
import paddle
# 使用 ERNIE 3.0 模型進行中文NER, 以7類為例(num_classes)
model_name = "ernie-3.0-base-zh"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name, num_classes=7)
# 自定義一段中文文本
text = "華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。"
# 將文本轉換為模型輸入格式
inputs = tokenizer(text, return_tensors="pd", padding=True, truncation=True, max_length=128)
# 模型預測
with paddle.no_grad():
logits = model(**inputs)
preds = paddle.argmax(logits, axis=-1).numpy()[0]
# 取出詞元與標籤
tokens = tokenizer.convert_ids_to_tokens(inputs['input_ids'][0].numpy())
label_map = {
0: "O", # 非實體
1: "B-PER", # 人名開頭
2: "I-PER", # 人名內部
3: "B-ORG", # 組織開頭
4: "I-ORG", # 組織內部
5: "B-LOC", # 地名開頭
6: "I-LOC", # 地名內部
}
# 顯示結果(只顯示非 'O' 的實體)
print("命名實體識別結果:")
for token, pred in zip(tokens, preds):
label = label_map.get(pred, "O")
if label != "O":
print(f"{token}: {label}")NER
from paddlenlp import Taskflow
# 醫療實體識別:診斷、症狀、藥物
schema = ['疾病', '症狀', '藥物']
ie_medical = Taskflow('information_extraction', model='uie-medical-base', schema=schema)
text = "患者出現高燒、咳嗽等症狀,診斷為流感,建議服用達菲。"
result = ie_medical(text)
print(result)
NER-醫療類
from paddlenlp import Taskflow
# 自訂實體類別
schema = ['學校名稱', '創辦人', '總部城市']
ie_custom = Taskflow('information_extraction', model='uie-base', schema=schema)
text = "真理大學是由牛津學堂發展而來,創辦人是馬偕,位於淡水。"
result = ie_custom(text)
print(result)
NER-自訂
from paddlenlp import Taskflow
# 自訂 schema(可根據任務調整)
schema = ['人物', '組織', '地點']
ie = Taskflow('information_extraction', model='uie-base', schema=schema)
# 多筆資料(List of strings)
texts = [
"馬雲是阿里巴巴的創始人,總部位於杭州。",
"劉德華出生於香港,是華語影壇的重要人物。",
"鴻海總部在新北市,創辦人是郭台銘。"
]
# 批次預測
results = ie(texts)
# 顯示結果
for idx, res in enumerate(results):
print(f"\n【第 {idx + 1} 筆輸入】")
print(res)
NER-批次處理
PaddleNLP finetune
pip install paddlepaddle==2.6.1非GPU版本
pip install -U paddlenlpgit clone https://github.com/PaddlePaddle/PaddleNLP.git
cd PaddleNLP/slm/model_zoo_uie下載微調專案,前往微調樣板資料夾

PaddleNLP finetune
建議資料夾結構
uie/
訓練檔
驗證檔
{"content": "蔡英文是台灣的總統,住在台北。", "prompt": "人物", "result_list": [{"start": 0, "end": 3, "text": "蔡英文"}]}
{"content": "蔡英文是台灣的總統,住在台北。", "prompt": "地點", "result_list": [{"start": 9, "end": 11, "text": "台灣"}]}
{"content": "蔡英文是台灣的總統,住在台北。", "prompt": "地點", "result_list": [{"start": 16, "end": 18, "text": "台北"}]}
train.jsonl
{"content": "侯友宜是新北市市長,住在新北。", "prompt": "人物", "result_list": [{"start": 0, "end": 3, "text": "侯友宜"}]}
{"content": "侯友宜是新北市市長,住在新北。", "prompt": "地點", "result_list": [{"start": 6, "end": 9, "text": "新北市"}]}
{"content": "侯友宜是新北市市長,住在新北。", "prompt": "地點", "result_list": [{"start": 14, "end": 16, "text": "新北"}]}
{"content": "台灣大學是台灣最著名的高等教育機構之一,位於台北。", "prompt": "組織", "result_list": [{"start": 0, "end": 4, "text": "台灣大學"}]}
{"content": "台灣大學是台灣最著名的高等教育機構之一,位於台北。", "prompt": "地點", "result_list": [{"start": 21, "end": 23, "text": "台灣"}]}
{"content": "台灣大學是台灣最著名的高等教育機構之一,位於台北。", "prompt": "地點", "result_list": [{"start": 31, "end": 33, "text": "台北"}]}dev.jsonl
PaddleNLP finetune
python finetune.py \
--train_path train.jsonl \
--dev_path dev.jsonl \
--output_dir ./checkpoint/uie-taiwan-custom \
--model_name_or_path uie-base \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--learning_rate 1e-5 \
--num_train_epochs 10 \
--logging_steps 10 \
--eval_steps 50 \
--save_steps 50 \
--do_train \
--do_eval \
--overwrite_output_dir \
--device gpu
Knowledge Graph Extraction
從ColleGo! 科系介紹文本中,自動萃取:
- 科系名稱
- 學群/學類
- 培養目標
- 未來出路
- 相關能力
- 學測/指考科目要求
Knowledge Graph Extraction
{
"text": "本系培養學生具備邏輯思考與程式設計能力。",
"label": {
"科系": [{"text": "本系"}],
"能力": [{"text": "邏輯思考"}, {"text": "程式設計"}],
"關係": [{"text": "培養"}]
}
}
Approach Universal IE
Approach NER+RE
relation_templates = [
"專注於", "研究", "涵蓋", "涉及", # 專業方向
"設立於", "創立於", "成立於", # 設立資訊
"擁有", "提供", "配備", "具備", # 教學資源
"位居", "榮獲", "獲得", # 排名與成就
"合作", "聯合", "交流" # 合作與交流
]Approach NER+RE
使用 CKIP Transformers 的中文命名實體辨識(NER)模型,從一段描述大學各系所研究領域的文字中:
- 辨識出實體(如學系名稱與研究領域)
- 建立實體對(Entity Pairs)
- 根據簡單規則分類這些實體對之間的關係,輸出三元組(subject, predicate, object)表示的關係
Ckip Transformers recall
Ckip Transformers recall


Part-of-Speech, PoS: 詞性
Name Entity: 類別、結果
華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。
華氏(Na) 80(Neu) 度(Nf) ,(COMMACATEGORY) 氣壓(Na) 30-6(Neu) ,(COMMACATEGORY) 整(Neqa) 天(Nf) 下雨(VA) 。(PERIODCATEGORY) 前進(VA) 到(P) 奇武荖(Nc) ,(COMMACATEGORY) 聆聽(VC) 朗誦(VC) 。(PERIODCATEGORY) 然後(D) 珍珠里簡(Na) 和(Caa) 冬瓜山(Nc) ,(COMMACATEGORY) 晚間(Nd) 在(P) 珍珠里簡(Nc) 的(DE) 禮拜(Na) 有(V_2) 一百五十(Neu) 人(Na) ,(COMMACATEGORY) 拔(VC) 了(Di) 七十六(Neu) 顆(Nf) 牙(Na) 。(PERIODCATEGORY)
(0, 5, 'QUANTITY', '華氏80度')
(8, 12, 'QUANTITY', '30-6')
(37, 40, 'LOC', '冬瓜山')
(41, 43, 'TIME', '晚間')
(52, 56, 'CARDINAL', '一百五十')
(60, 63, 'CARDINAL', '七十六')
實體辨識
11類專有名詞
7類數量詞
Part-of-Speech(POS)
61種詞性
# NER → Entity Pair → Relationship Classification using CKIP Transformers
from ckip_transformers.nlp import CkipNerChunker
from itertools import permutations
# Initialize NER model
ner = CkipNerChunker(model="ckiplab/bert-base-chinese-ner")
# Input text
text = "國立台灣大學資訊工程學系以人工智慧、大數據分析、機器學習和自然語言處理為主要研究領域。\n國立台灣大學法律學系以憲法學、民法學和刑法學為主要研究領域。\n國立台灣大學經濟學系以國際貿易、計量經濟學和財務經濟學為主要研究領域。\n國立台灣大學企業管理學系以行銷管理、組織行為學和策略管理為主要研究領域。\n國立台灣大學觀光管理學系以觀光行銷、觀光規劃和觀光經營管理為主要研究領域。\n國立台灣大學運動管理學系以運動行銷、運動心理學和運動經濟學為主要研究領域。\n國立台灣大學應用日語學系以日本語言學、日本文學和日語教育為主要研究領域。"
# Run NER to extract entities
entities = ner([text])[0]
entity_list = [entity.word for entity in entities]
entity_types = {entity.word: entity.ner for entity in entities}
# Generate entity pairs (subject, object)
entity_pairs = list(permutations(entity_list, 2))
# Relationship classification (simple rule-based for demo)
def classify_relationship(subject, obj, entity_types):
# Extended professional domains for broader departments
professional_domains = [
"人工智慧", "大數據分析", "機器學習", "自然語言處理", "資訊安全", "電腦視覺", "演算法", "數據科學", # Computer Science
"行銷管理", "組織行為學", "策略管理", "財務管理", "人力資源管理", # Business Administration
"觀光行銷", "觀光規劃", "觀光經營管理", # Tourism
"運動行銷", "運動心理學", "運動經濟學", # Sports Management
"日本語言學", "日本文學", "日語教育" # Applied Japanese
]
if "學系" in subject and obj in professional_domains:
return "研究領域"
return None
# Extract triples
triples = []
for subject, obj in entity_pairs:
relation = classify_relationship(subject, obj, entity_types)
if relation:
triples.append({"subject": subject, "predicate": relation, "object": obj})
# Print results
print(triples)只使用Name Entity+排列組合
Approach NER+RE
使用 CKIP Transformers 的中文命名實體辨識(NER)模型與PoS標註,從一段描述大學各系所研究領域的文字中:
- 執行命名實體識別
- 執行詞性標註: 使用 pos_tagger
- 關係萃取
from ckip_transformers.nlp import CkipNerChunker, CkipPosTagger, CkipWordSegmenter
# 初始化 CKIP Transformers
segmenter = CkipWordSegmenter()
pos_tagger = CkipPosTagger()
ner = CkipNerChunker()
# 測試文本 - 台灣大學學系介紹範例
text = "國立臺灣大學電機工程學系專注..."
# 執行斷詞
word_segmentation_results = segmenter([text])
# 執行詞性標註 (需要分詞結果)
pos_results = pos_tagger(word_segmentation_results)
# 執行 NER
ner_results = ner([text])使用Name Entity+PoS
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
ws_driver = CkipWordSegmenter() # 初始化 CKIP 模型
pos_driver = CkipPosTagger()
ner_driver = CkipNerChunker()
text = ["2024年,台積電在美國亞利桑那州設立了新晶圓廠。"]
ws = ws_driver(text)
pos = pos_driver(ws)
ner = ner_driver(text)
print("🔎 命名實體:")
for sentence in ner:
for entity in sentence:
print(f"{entity.word} → {entity.ner}")
print("💥 事件擷取(簡易)")
trigger_words = ["設立", "成立", "開幕", "建設"]
for tokens, tags in zip(ws, pos):
for i, word in enumerate(tokens):
if word in trigger_words:
subject = tokens[i-2] if i >= 2 else ""
location = tokens[i-1] if i >= 1 else ""
obj = tokens[i+1] if i+1 < len(tokens) else ""
print(f"事件:{word}")
print(f" 主體:{subject}")
print(f" 地點:{location}")
print(f" 對象:{obj}")
print("🔗 關係擷取(主詞-動詞-受詞邏輯)")
for tokens, tags in zip(ws, pos):
for i in range(1, len(tokens)-1):
if tags[i].startswith("V"):
subj = tokens[i-1]
obj = tokens[i+1]
print(f"[主詞] {subj} —[動詞] {tokens[i]}→ [受詞] {obj}")NER/關係擷取/事件擷取 CKIP_Transformers
from ckip_transformers.nlp import CkipNerChunker, CkipPosTagger, CkipWordSegmenter
import re
# 初始化 CKIP Transformers
segmenter = CkipWordSegmenter()
pos_tagger = CkipPosTagger()
ner = CkipNerChunker()
# 定義常見學系介紹述詞 (這裡的判斷邏輯需要根據 CKIP POS 標籤進行調整)
relation_templates = [
"專注於", "研究", "涵蓋", "涉及", # 專業方向 (動詞)
"設立於", "創立於", "成立於", # 設立資訊 (動詞)
"擁有", "提供", "配備", "具備", # 教學資源 (動詞)
"位居", "榮獲", "獲得", # 排名與成就 (動詞)
"合作", "聯合", "交流" # 合作與交流 (動詞/名詞,需注意)
]
# 測試文本 - 台灣大學學系介紹範例
text = "國立臺灣大學電機工程學系專注於人工智慧、電力系統與通信工程,是台灣領先的工程學系之一,擁有優秀的師資與尖端的實驗設備,並設立於1948年,提供多樣化的課程與研究機會。"
# 執行分詞
word_segmentation_results = segmenter([text])
# 執行詞性標註 (需要分詞結果)
pos_results = pos_tagger(word_segmentation_results)
# 執行 NER
ner_results = ner([text])
entities = []
for entity in ner_results[0]:
entities.append({
"entity": entity.word,
"type": entity.ner
})
# --- 偵錯步驟 ---
print("word_segmentation_results 的類型:", type(word_segmentation_results))
print("word_segmentation_results 的內容:", word_segmentation_results)
print("pos_results 的類型:", type(pos_results))
print("pos_results 的長度:", len(pos_results))
print("pos_results 的內容:", pos_results) # 印出 pos_results 的完整內容,觀察其結構
if pos_results and isinstance(pos_results, list):
pos_tokens = list(zip(word_segmentation_results[0], pos_results[0]))
print("pos_tokens 的類型:", type(pos_tokens))
print("pos_tokens 的長度:", len(pos_tokens))
print("pos_tokens 的內容:", pos_tokens)
print("\nCKIP Transformers 詞性標註結果:")
for token, pos in pos_tokens:
print(f"{token:<12} {pos}")
# 抽取 S-P-O 關係 (需要根據 CKIP POS 標籤進行調整)
relations = []
subject = ""
predicate = ""
objects = []
for i, (token, pos) in enumerate(pos_tokens):
if "N" in pos and not subject: # 尋找名詞作為主語 (簡化處理)
subject = token
elif "V" in pos and token in relation_templates and subject: # 尋找謂語動詞
predicate = token
# 嘗試尋找後面的名詞作為賓語 (非常簡化的處理,實際情況更複雜)
potential_objects = [t for t, p in pos_tokens[i+1:] if "N" in p]
if potential_objects:
relations.append({
"主語": subject,
"謂語": predicate,
"賓語": potential_objects[0]
})
subject = "" # 重置主語以便尋找下一個關係
predicate = ""
objects = []
print("\n實體識別結果:")
print(entities)
print("\n關係抽取結果 (基於 CKIP POS):")
print(relations)
else:
print("Error: pos_results is not in the expected format.")
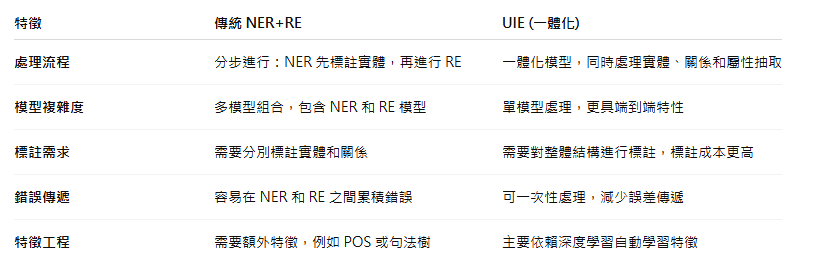
Comparison NER+RE vs UIE
架構差異
Comparison NER+RE vs UIE
效果差異
{
"entities": [
{"text": "資訊工程學系", "type": "系所"},
{"text": "人工智慧", "type": "領域"}
],
"relations": [
{"head": "資訊工程學系", "tail": "人工智慧", "type": "研究領域"}
]
}
{
"triples": [
{"subject": "資訊工程學系", "predicate": "研究領域", "object": "人工智慧"}
]
}NER+RE
UIE
CKIP Transformer finetune
辨識更多實體類別
假設原本 CKIP Transformers可以識別「人名」(PERSON)、「地點」(GPE)和「組織」(ORG)的 NER 模型。現在,希望能夠識別更多類別,例如:
- 產品名稱 (PRODUCT):例如:iPhone、PlayStation 5
- 事件名稱 (EVENT):例如:世界盃足球賽、跨年演唱會
- 日期時間 (DATE):例如:2023年10月26日、下週三下午三點
Finetune 情境
# (1) ✅ 安裝必要套件(第一次執行時取消註解)
# !pip install transformers datasets seqeval evaluate
from transformers import (
AutoModelForTokenClassification,
AutoTokenizer,
TrainingArguments,
Trainer,
DataCollatorForTokenClassification
)
from datasets import Dataset, DatasetDict
import numpy as np
import evaluate
Finetune 安裝套件
Finetune 擴展標註的訓練資料
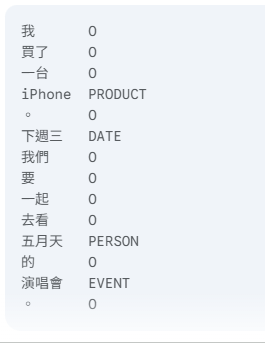
準備擴展標註的訓練資料:
準備訓練資料集,其中包含了您想要新增的 NER 類別的標註。資料格式通常會是 CoNLL 格式或其他類似的序列標註格式。
例如:
# (2)🏷️ 定義實體類別標籤
label_list = [
'O',
'B-PERSON', 'I-PERSON',
'B-GPE', 'I-GPE',
'B-ORG', 'I-ORG',
'B-PRODUCT', 'I-PRODUCT',
'B-EVENT', 'I-EVENT',
'B-DATE', 'I-DATE'
]
label_to_id = {label: i for i, label in enumerate(label_list)}
id_to_label = {i: label for label, i in label_to_id.items()}
num_labels = len(label_list)
label_all_tokens = False
Finetune 加入新的分類標記
修改標籤列表:
- 更新列表,使其包含新的 NER 類別。
例如:原始標籤是 ['O', 'B-PERSON', 'I-PERSON', 'B-GPE', 'I-GPE', 'B-ORG', 'I-ORG']。則需要擴展為包含新的類別: - 新的實體類別,您通常需要包含
B-(Beginning) 和I-(Inside) 標籤,以及O(Outside) 標籤表示非實體詞。
# (3)🧾 訓練樣本資料集(10 筆)
examples = [
{"tokens": ["林志玲", "出席", "了", "金馬獎", "活動"], "ner_tags": ["B-PERSON", "O", "O", "B-EVENT", "O"]},
{"tokens": ["台積電", "是", "台灣", "知名", "企業"], "ner_tags": ["B-ORG", "O", "B-GPE", "O", "O"]},
{"tokens": ["iPhone", "是", "蘋果", "公司", "的", "產品"], "ner_tags": ["B-PRODUCT", "O", "B-ORG", "I-ORG", "O", "O"]},
{"tokens": ["2024年", "總統大選", "將於", "1月", "舉行"], "ner_tags": ["B-DATE", "B-EVENT", "O", "I-DATE", "O"]},
{"tokens": ["蔡英文", "曾任", "中華民國", "總統"], "ner_tags": ["B-PERSON", "O", "B-GPE", "O"]},
{"tokens": ["五月天", "將舉辦", "演唱會"], "ner_tags": ["B-ORG", "O", "B-EVENT"]},
{"tokens": ["Google", "開發", "了", "Pixel", "手機"], "ner_tags": ["B-ORG", "O", "O", "B-PRODUCT", "O"]},
{"tokens": ["賴清德", "參觀", "台北", "故宮博物院"], "ner_tags": ["B-PERSON", "O", "B-GPE", "O"]},
{"tokens": ["微軟", "於", "2023年", "發布", "新產品"], "ner_tags": ["B-ORG", "O", "B-DATE", "O", "O"]},
{"tokens": ["奧運", "比賽", "在", "東京", "舉行"], "ner_tags": ["B-EVENT", "O", "O", "B-GPE", "O"]}
]
raw_dataset = Dataset.from_list(examples)
raw_datasets = DatasetDict({
"train": raw_dataset.select(range(6)),
"validation": raw_dataset.select(range(6, 10))
})
Finetune 載入訓練資料
載入訓練資料
# (4)🤖 載入 CKIP BERT 模型與 tokenizer
model_name = "ckiplab/bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name, num_labels=num_labels)Finetune 更新模型設定
更新模型設定:
- 確保模型輸出層能夠處理新的標籤數量。如果您直接使用 AutoModelForTokenClassification 載入模型,並在訓練時指定 num_labels,transformers 通常會自動調整輸出層的大小。
# (5)✂️ 對齊分詞與標籤(tokenize_and_align_labels)
def tokenize_and_align_labels(example):
tokenized = tokenizer(example["tokens"], is_split_into_words=True, truncation=True)
word_ids = tokenized.word_ids()
aligned_labels = []
prev_word_idx = None
for word_idx in word_ids:
if word_idx is None:
aligned_labels.append(-100)
elif word_idx != prev_word_idx:
aligned_labels.append(label_to_id[example["ner_tags"][word_idx]])
else:
aligned_labels.append(label_to_id[example["ner_tags"][word_idx]] if label_all_tokens else -100)
prev_word_idx = word_idx
tokenized["labels"] = aligned_labels
return tokenized
tokenized_datasets = raw_datasets.map(tokenize_and_align_labels)
Finetune 準備資料集
準備資料集:
- 將載入的訓練資料轉換成模型可以接受的格式,包括將文本tokenize,並將標籤轉換成對應的數字 ID。
# (6) 📊 計算 F1、Precision、Recall
seqeval = evaluate.load("seqeval")
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
true_labels = [
[id_to_label[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_predictions = [
[id_to_label[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = seqeval.compute(predictions=true_predictions, references=true_labels)
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}Finetune 計算F Score
計算F Score:
- 將載入的訓練資料轉換成模型可以接受的格式,包括將文本tokenize,並將標籤轉換成對應的數字 ID。
# (7) ⚙️ 訓練參數設定
training_args = TrainingArguments(
output_dir="./ner_ckip_model",
evaluation_strategy="epoch",
save_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
num_train_epochs=10,
weight_decay=0.01,
logging_dir="./logs",
load_best_model_at_end=True,
metric_for_best_model="f1",
greater_is_better=True
)Finetune 定義訓練參數
定義訓練參數:
- 設定您的訓練參數,例如學習率、epochs、batch size 等。
# (8) 🚀 開始訓練!
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
tokenizer=tokenizer,
data_collator=DataCollatorForTokenClassification(tokenizer),
compute_metrics=compute_metrics
)
trainer.train()
Finetune 訓練模型
訓練模型
...(前9輪)...
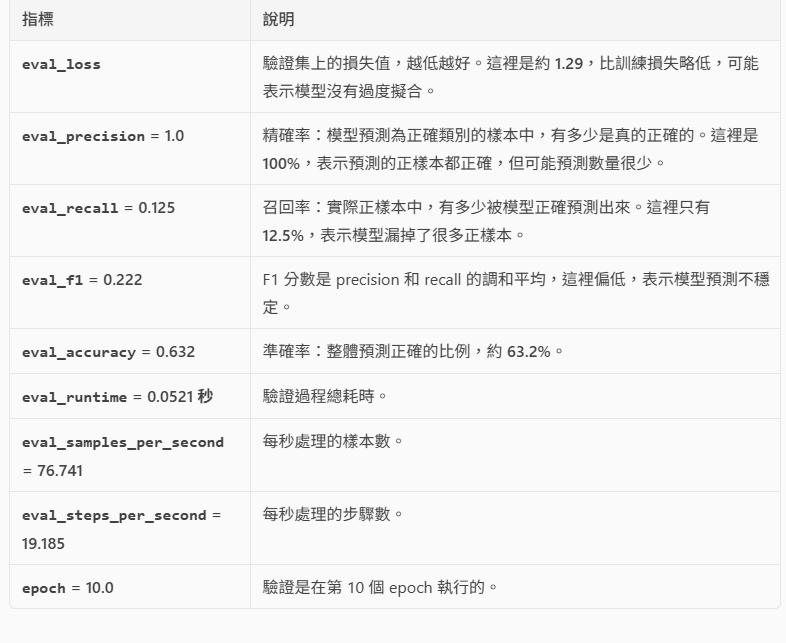
{'eval_loss': 1.290615200996399, 'eval_precision': 1.0, 'eval_recall': 0.125, 'eval_f1': 0.2222222222222222, 'eval_accuracy': 0.631578947368421, 'eval_runtime': 0.0521, 'eval_samples_per_second': 76.741, 'eval_steps_per_second': 19.185, 'epoch': 10.0}
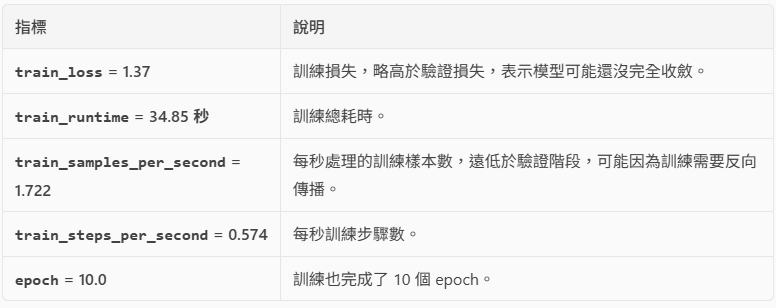
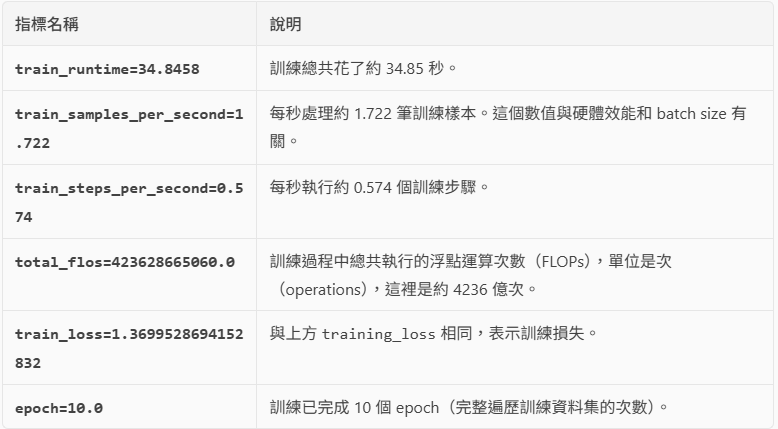
{'train_runtime': 34.8458, 'train_samples_per_second': 1.722, 'train_steps_per_second': 0.574, 'train_loss': 1.3699528694152832, 'epoch': 10.0}
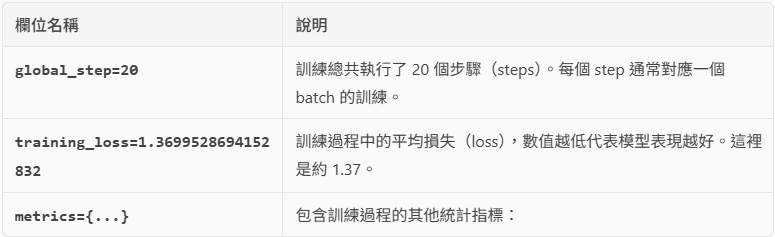
TrainOutput(global_step=20, training_loss=1.3699528694152832, metrics={'train_runtime': 34.8458, 'train_samples_per_second': 1.722, 'train_steps_per_second': 0.574, 'total_flos': 423628665060.0, 'train_loss': 1.3699528694152832, 'epoch': 10.0})
Finetune 訓練模型
{
'eval_loss': 1.290615200996399,
'eval_precision': 1.0,
'eval_recall': 0.125,
'eval_f1': 0.2222222222222222,
'eval_accuracy': 0.631578947368421,
'eval_runtime': 0.0521,
'eval_samples_per_second': 76.741,
'eval_steps_per_second': 19.185,
'epoch': 10.0
}
Finetune 訓練模型
{
'train_runtime': 34.8458,
'train_samples_per_second': 1.722,
'train_steps_per_second': 0.574,
'train_loss': 1.3699528694152832,
'epoch': 10.0
}
Finetune 訓練模型
# (9) 💾 儲存訓練完成的模型
trainer.save_model("./ner_ckip_model")
tokenizer.save_pretrained("./ner_ckip_model")Finetune 儲存模型與預測
儲存模型
# 載入微調後的模型
finetuned_model = AutoModelForTokenClassification.from_pretrained("./ner_ckip_model")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 進行預測
text = "蘋果公司在下週三發布了最新的iPhone 15。"
tokens = tokenizer(text, return_offsets_mapping=True, truncation=True, is_split_into_words=False)
# ... (進行模型預測並將 token 回應射到原始文本)用於新的文本中進行 NER 預測
Preparation: Information Extraction
By Leuo-Hong Wang



