Practical Applications of Chatbot
Knowledge Graph Part 3
Example
參考來源:Fareed Khan, Converting Unstructured Data into a Knowledge Graph Using an End-to-End Pipeline, Step by Step guide
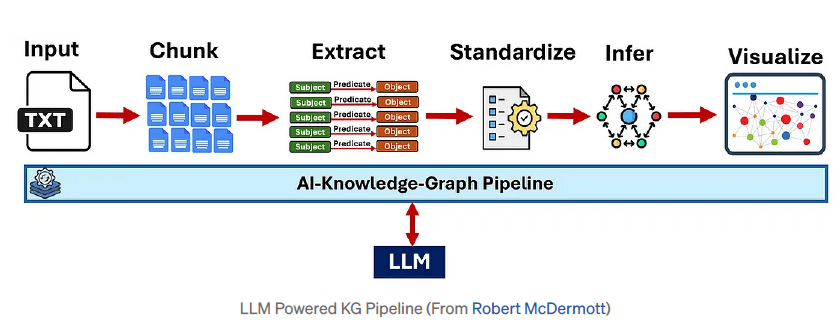
Knowledge Graph end-to-end pipeline
擷取什麼? Ontology!
Knowledge Graph 安裝所需套件
# Install libraries (run this cell once)
pip install openai networkx "ipycytoscape>=1.3.1" ipywidgets pandas# (1) import 所需套件
import openai # For LLM interaction
import json # For parsing LLM responses
import networkx as nx # For creating and managing the graph data structure
import ipycytoscape # For interactive in-notebook graph visualization
import ipywidgets # For interactive elements
import pandas as pd # For displaying data in tables
import os # For accessing environment variables (safer for API keys)
import math # For basic math operations
import re # For basic text cleaning (regular expressions)
import warnings # To suppress potential deprecation warningsKnowledge Graph 什麼是Knowledge graph
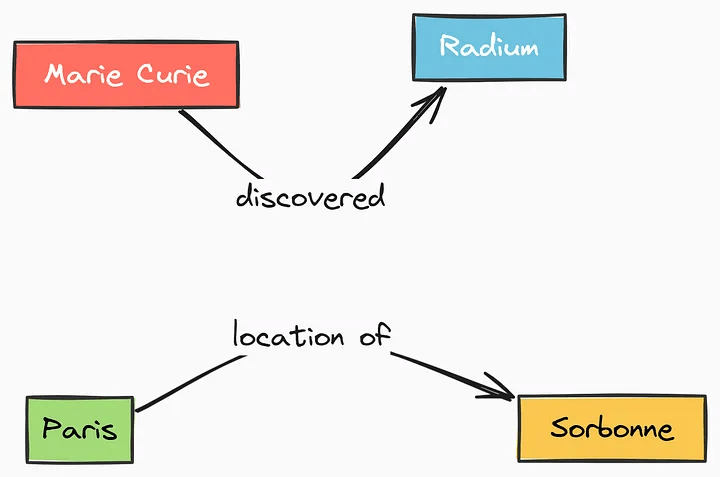
Subject-Predicate-Object (SPO) Triples
Knowledge Graph Configuring Our LLM Connection
# (2) 測試vLLM server連線
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="google/gemma-3-1b-it",
prompt="台北是怎樣的城市?")
print("Completion result:", completion)pip install vllm
vllm serve google/gemma-3-1b-it# (3) 範例程式碼:使用 OpenAI Chat Completions API 呼叫 vLLM
import openai
import os
# 設定 API URL 和金鑰
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
llm_model_name = "google/gemma-3-1b-it"
llm_temperature = 0.0 # Lower temperature for more deterministic, factual output. 0.0 is best for extraction.
llm_max_tokens = 4096 # Max tokens for the LLM response (adjust based on model limits)
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
# 發送 Chat Completions 請求
response = client.chat.completions.create(
model=llm_model_name,
messages=[
{"role": "system", "content": "你是聰明且專業的 AI 助手。"},
{"role": "user", "content": "你好!能介紹一下 gemma-3-1b-it 嗎?"}
],
max_tokens= llm_max_tokens,
temperature= llm_temperature
)
# 顯示回應
print(response.choices[0].message.content)Knowledge Graph 準備文本資料
# (4) 準備非結構化文本資料-居禮夫人維基百科
unstructured_text = """
Maria Salomea Skłodowska-Curie(7 November 1867 – 4 July 1934), known simply as Marie Curie, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.
She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields. Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes. She was, in 1906, the first woman to become a professor at the University of Paris.[2]
She was born in Warsaw, in what was then the Kingdom of Poland, part of the Russian Empire. She studied at Warsaw's clandestine Flying University and began her practical scientific training in Warsaw. In 1891, aged 24, she followed her elder sister Bronisława to study in Paris, where she earned her higher degrees and conducted her subsequent scientific work. In 1895, she married the French physicist Pierre Curie, and she shared the 1903 Nobel Prize in Physics with him and with the physicist Henri Becquerel for their pioneering work developing the theory of "radioactivity"—a term she coined.[3][4] In 1906, Pierre Curie died in a Paris street accident. Marie won the 1911 Nobel Prize in Chemistry for her discovery of the elements polonium and radium, using techniques she invented for isolating radioactive isotopes.
Under her direction, the world's first studies were conducted into the treatment of neoplasms by the use of radioactive isotopes. She founded the Curie Institute in Paris in 1920, and the Curie Institute in Warsaw in 1932; both remain major medical research centres. During World War I, she developed mobile radiography units to provide X-ray services to field hospitals.
While a French citizen, Marie Skłodowska Curie, who used both surnames, never lost her sense of Polish identity. She taught her daughters the Polish language and took them on visits to Poland. She named the first chemical element she discovered polonium, after her native country.
Marie Curie died in 1934, aged 66, at the Sancellemoz sanatorium in Passy (Haute-Savoie), France, of aplastic anaemia likely from exposure to radiation in the course of her scientific research and in the course of her radiological work at field hospitals during World War I.In addition to her Nobel Prizes, she received numerous other honours and tributes; in 1995 she became the first woman to be entombed on her own merits in the Paris Panthéon,[10] and Poland declared 2011 the Year of Marie Curie during the International Year of Chemistry. She is the subject of numerous biographies."""
print("--- Input Text Loaded ---")
print(unstructured_text)
print("-" * 25)
# Basic stats visualization
char_count = len(unstructured_text)
word_count = len(unstructured_text.split())
print(f"Total characters: {char_count}")
print(f"Approximate word count: {word_count}")
print("-" * 25)
Knowledge Graph Chunking
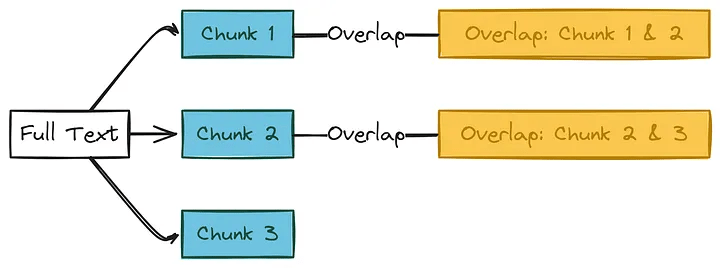
- Chunk Size: The maximum number of words in each chunk.
- Overlap: How many words should overlap
Knowledge Graph Chunking
# (5)--- Chunking Configuration ---
chunk_size = 150 # Number of words per chunk (adjust as needed)
overlap = 30 # Number of words to overlap (must be < chunk_size)
print(f"Chunk Size set to: {chunk_size} words")
print(f"Overlap set to: {overlap} words")
# --- Basic Validation ---
if overlap >= chunk_size and chunk_size > 0:
print(f"Error: Overlap ({overlap}) must be smaller than chunk size ({chunk_size}).")
raise SystemExit("Chunking configuration error.")
else:
print("Chunking configuration is valid.")
# (6) spliting text into individual words.
words = unstructured_text.split()
total_words = len(words)
print(f"Text split into {total_words} words.")
# Visualize the first 20 words
print(f"First 20 words: {words[:20]}")
# (8) chunking process
chunks = []
start_index = 0
chunk_number = 1
print(f"Starting chunking process...")
while start_index < total_words:
end_index = min(start_index + chunk_size, total_words)
chunk_text = " ".join(words[start_index:end_index])
chunks.append({"text": chunk_text, "chunk_number": chunk_number})
# Calculate the start of the next chunk
next_start_index = start_index + chunk_size - overlap
# Ensure progress is made
if next_start_index <= start_index:
if end_index == total_words:
break # Already processed the last part
next_start_index = start_index + 1
start_index = next_start_index
chunk_number += 1
# Safety break (optional)
if chunk_number > total_words: # Simple safety
print("Warning: Chunking loop exceeded total word count, breaking.")
break
print(f"\nText successfully split into {len(chunks)} chunks.")Knowledge Graph Chunking
# (9) Chunk details
print("--- Chunk Details ---")
if chunks:
# Create a DataFrame for better visualization
chunks_df = pd.DataFrame(chunks)
chunks_df['word_count'] = chunks_df['text'].apply(lambda x: len(x.split()))
display(chunks_df[['chunk_number', 'word_count', 'text']])
else:
print("No chunks were created (text might be shorter than chunk size).")
print("-" * 25)Knowledge Graph Chunking

Knowledge Graph LLM指令樣板
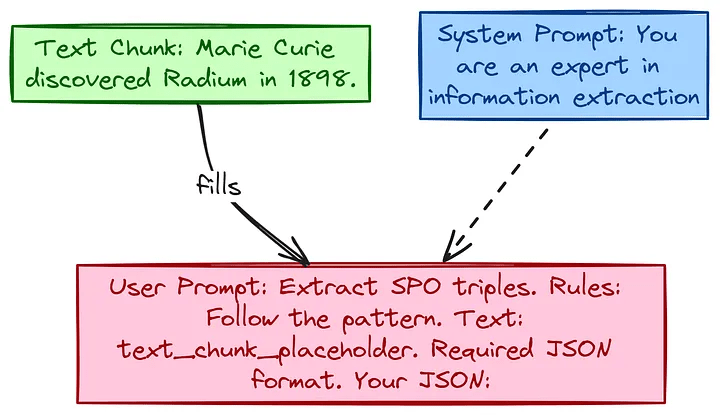
# (10)--- System Prompt: Sets the context/role for the LLM ---
extraction_system_prompt = """
You are an AI expert specialized in knowledge graph extraction.
Your task is to identify and extract factual Subject-Predicate-Object (SPO) triples from the given text.
Focus on accuracy and adhere strictly to the JSON output format requested in the user prompt.
Extract core entities and the most direct relationship.
"""
# --- User Prompt Template: Contains specific instructions and the text ---
extraction_user_prompt_template = """
Please extract Subject-Predicate-Object (S-P-O) triples from the text below.
**VERY IMPORTANT RULES:**
1. **Output Format:** Respond ONLY with a single, valid JSON array. Each element MUST be an object with keys "subject", "predicate", "object".
2. **JSON Only:** Do NOT include any text before or after the JSON array (e.g., no 'Here is the JSON:' or explanations). Do NOT use markdown ```json ... ``` tags.
3. **Concise Predicates:** Keep the 'predicate' value concise (1-3 words, ideally 1-2). Use verbs or short verb phrases (e.g., 'discovered', 'was born in', 'won').
4. **Lowercase:** ALL values for 'subject', 'predicate', and 'object' MUST be lowercase.
5. **Pronoun Resolution:** Replace pronouns (she, he, it, her, etc.) with the specific lowercase entity name they refer to based on the text context (e.g., 'marie curie').
6. **Specificity:** Capture specific details (e.g., 'nobel prize in physics' instead of just 'nobel prize' if specified).
7. **Completeness:** Extract all distinct factual relationships mentioned.
**Text to Process:**
```text
{text_chunk}"""Knowledge Graph LLM指令樣板
#(11) LLM樣板指令-印出來看看
print("--- System Prompt ---")
print(extraction_system_prompt)
print("\n" + "-" * 25 + "\n")
print("--- User Prompt Template (Structure) ---")
# Show structure, replacing the placeholder for clarity
print(extraction_user_prompt_template.replace("{text_chunk}", "[... text chunk goes here ...]"))
print("\n" + "-" * 25 + "\n")
# Show an example of the *actual* prompt that will be sent for the first chunk
print("--- Example Filled User Prompt (for Chunk 1) ---")
if chunks:
example_filled_prompt = extraction_user_prompt_template.format(text_chunk=chunks[0]['text'])
# Displaying a limited portion for brevity
print(example_filled_prompt[:600] + "\n[... rest of chunk text ...]\n" + example_filled_prompt[-200:])
else:
print("No chunks available to create an example filled prompt.")
print("\n" + "-" * 25)Knowledge Graph LLM指令樣板
# (12)Initialize lists to store results and failures
all_extracted_triples = []
failed_chunks = []
print(f"Starting triple extraction from {len(chunks)} chunks using model '{llm_model_name}'...")
# We will process chunks one by one in the following cells.Knowledge Graph Extraction Triples
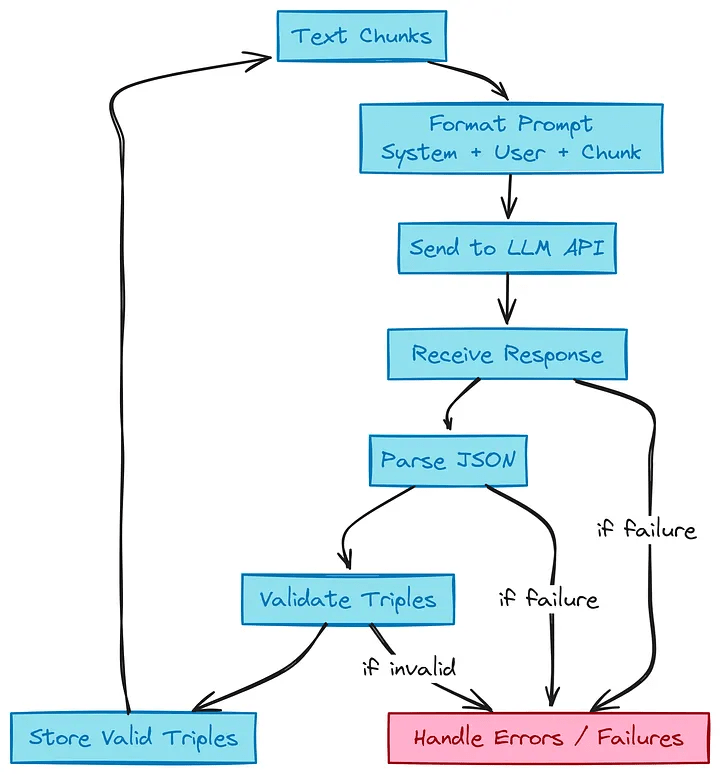
def extract_triples(raw, chunk, all_extracted_triples, failed_chunks):
# 初始化解析緩衝區
data_list = []
# 先嘗試直接解析 JSON
try:
data = json.loads(raw)
# 如果是 dict,檢查是否為單一 triple 或包含 triple 列表
if isinstance(data, dict):
# 單一 triple 直接轉為列表處理
if all(isinstance(data.get(k), str) for k in ['subject', 'predicate', 'object']):
data_list.append(data)
else:
# 找出第一個 list 型態的值
nested_list = next((v for v in data.values() if isinstance(v, list)), [])
print(f"Nested list found: {nested_list}")
data_list.extend(nested_list)
# 如果是 list,直接當作 triple 集合
elif isinstance(data, list):
data_list.extend(data)
else:
raise ValueError("Unexpected data type")
except (json.JSONDecodeError, ValueError) as e:
# 如果 JSON 解析失敗,嘗試從字串中擷取 list
match = re.search(r'\[.*?\]', raw, re.DOTALL)
if match:
try:
data_list.extend(json.loads(match.group(0)))
print(f"Recovered data==>{data_list}")
except json.JSONDecodeError as inner_e:
failed_chunks.append({
'chunk_number': chunk['chunk_number'],
'error': f'JSON parsing failed: {inner_e}',
'response': raw
})
return
else:
# 如果正則也找不到 list,記錄失敗
failed_chunks.append({
'chunk_number': chunk['chunk_number'],
'error': f'No valid JSON or list found: {e}',
'response': raw
})
return
# 開始處理 data_list
while data_list:
t = data_list.pop(0)
# 處理巢狀結構 (允許多層列表)
if isinstance(t, list):
data_list.extend(t)
continue
# 驗證是否為有效 triple
if isinstance(t, dict) and all(isinstance(t.get(k), str) for k in ['subject', 'predicate', 'object']):
all_extracted_triples.append({**t, 'chunk': chunk['chunk_number']})
else:
print(f"Invalid triple skipped: {t}")
# 如果沒有找到有效 triples,記錄失敗
if not all_extracted_triples:
failed_chunks.append({
'chunk_number': chunk['chunk_number'],
'error': 'No valid triples found',
'response': raw
})Knowledge Graph Extraction Triples
chunk_index = 0 # Process first chunk only
llm_temperature = 0.0
llm_max_tokens = 4096
while chunk_index < len(chunks):
chunk = chunks[chunk_index]
prompt = extraction_user_prompt_template.format(text_chunk=chunk['text'])
try:
# Call LLM with system + user prompt
res = client.chat.completions.create(
model=llm_model_name,
messages=[{"role": "system", "content": extraction_system_prompt},
{"role": "user", "content": prompt}],
temperature=llm_temperature,
max_tokens=llm_max_tokens,
response_format={"type": "json_object"},
)
raw = res.choices[0].message.content.strip()
print(f'raw:{raw}')
except Exception as e:
failed_chunks.append({'chunk_number': chunk['chunk_number'], 'error': str(e), 'response': ''})
print("LLM call failed."); exit()
# Try JSON parsing directly or via regex fallback
extract_triples(raw, chunk, all_extracted_triples, failed_chunks)
chunk_index += 1
print("Done.")Knowledge Graph Extraction Triples
# (13)--- Summary of Extraction (Reflecting state after the single chunk demo / or full run) ---
print(f"\n--- Overall Extraction Summary ---\n")
print(f"Total chunks defined: {len(chunks)}\")\n")
# Assuming full run for summary logic
processed_chunks = len(chunks) # Approximation if loop isn't run fully
print(f"Chunks processed (attempted): {processed_chunks}") # Chunks we looped through
print(f"Total valid triples extracted across all processed chunks: {len(all_extracted_triples)}")
print(f"Number of chunks that failed API call or parsing: {len(failed_chunks)}")
if failed_chunks:
print("\nDetails of Failed Chunks:")
failed_df = pd.DataFrame(failed_chunks)
display(failed_df[['chunk_number', 'error']]) # Display failed chunks neatly
# for failure in failed_chunks:
# print(f" Chunk {failure['chunk_number']}: Error: {failure['error']}")
print("-" * 25)
# Display all extracted triples using Pandas
print("\n--- All Extracted Triples (Before Normalization) ---")
if all_extracted_triples:
all_triples_df = pd.DataFrame(all_extracted_triples)
display(all_triples_df)
else:
print("No triples were successfully extracted.")
print("-" * 25)Knowledge Graph Extraction Triples
Knowledge Graph Normalization & De-duplication
- Normalize: Trim any extra spaces from the beginning or end of subjects, predicates, and objects.
- Filter: Remove any triples where one of the parts became empty after trimming (e.g., if the LLM returned “ “).
- De-duplicate: Remove exact copies of the same (subject, predicate, object) fact that might have been extracted from overlapping chunks or different phrasings in the text.
Knowledge Graph Normalization & De-duplication
# (14) Initialize lists and tracking variables
normalized_triples = []
seen_triples = set() # Tracks (subject, predicate, object) tuples
original_count = len(all_extracted_triples)
empty_removed_count = 0
duplicates_removed_count = 0
print(f"Starting normalization and de-duplication of {original_count} triples...")
Knowledge Graph Normalization & De-duplication
# (15)
print("Processing triples (showing first 5):")
for i, t in enumerate(all_extracted_triples):
s, p, o = [t.get(k, '').strip().lower() if isinstance(t.get(k), str) else '' for k in ['subject', 'predicate', 'object']]
p = re.sub(r'\s+', ' ', p)
if all([s, p, o]):
key = (s, p, o)
if key not in seen_triples:
normalized_triples.append({'subject': s, 'predicate': p, 'object': o, 'source_chunk': t.get('chunk', '?')})
seen_triples.add(key)
if i < 5:
print(f"\n#{i+1}: {key}\nStatus: Kept")
else:
duplicates_removed_count += 1
if i < 5: print(f"\n#{i+1}: Duplicate - Skipped")
else:
empty_removed_count += 1
if i < 5: print(f"\n#{i+1}: Invalid - Skipped")
print(f"\nDone. Total: {len(all_extracted_triples)}, Kept: {len(normalized_triples)}, Duplicates: {duplicates_removed_count}, Empty: {empty_removed_count}")
Knowledge Graph Normalization & De-duplication
# (16)--- Summary of Normalization ---
print(f"\n--- Normalization & De-duplication Summary ---\n")
print(f"Original extracted triple count: {original_count}\")\n")
print(f"Triples removed (empty/invalid components): {empty_removed_count}\")\n")
print(f"Duplicate triples removed: {duplicates_removed_count}\")\n")
final_count = len(normalized_triples)
print(f"Final unique, normalized triple count: {final_count}\")\n")
print("-" * 25)
# Display a sample of normalized triples using Pandas
print("\n--- Final Normalized Triples ---")
if normalized_triples:
normalized_df = pd.DataFrame(normalized_triples)
display(normalized_df)
else:
print("No valid triples remain after normalization.")
print("-" * 25)Knowledge Graph Creating the Graph with NetworkX
# (17)Create an empty directed graph
knowledge_graph = nx.DiGraph()
print("Initialized an empty NetworkX DiGraph.")
# Visualize the initial empty graph state
print("--- Initial Graph Info ---")
try:
# Try the newer method first
print(nx.info(knowledge_graph))
except AttributeError:
# Fallback for different NetworkX versions
print(f"Type: {type(knowledge_graph).__name__}")
print(f"Number of nodes: {knowledge_graph.number_of_nodes()}")
print(f"Number of edges: {knowledge_graph.number_of_edges()}")
print("-" * 25)Knowledge Graph Creating the Graph with NetworkX
# (18)
print("Adding triples to the NetworkX graph...")
added_edges_count = 0
update_interval = 10 # How often to print graph info update
if not normalized_triples:
print("Warning: No normalized triples to add to the graph.")
else:
for i, triple in enumerate(normalized_triples):
subject_node = triple['subject']
object_node = triple['object']
predicate_label = triple['predicate']
# Nodes are added automatically when adding edges, but explicit calls are fine too
# knowledge_graph.add_node(subject_node)
# knowledge_graph.add_node(object_node)
# Add the directed edge with the predicate as a 'label' attribute
knowledge_graph.add_edge(subject_node, object_node, label=predicate_label)
added_edges_count += 1
# --- Visualize Graph Growth ---
if (i + 1) % update_interval == 0 or (i + 1) == len(normalized_triples):
print(f"\n--- Graph Info after adding Triple #{i+1} --- ({subject_node} -> {object_node})")
try:
# Try the newer method first
print(nx.info(knowledge_graph))
except AttributeError:
# Fallback for different NetworkX versions
print(f"Type: {type(knowledge_graph).__name__}")
print(f"Number of nodes: {knowledge_graph.number_of_nodes()}")
print(f"Number of edges: {knowledge_graph.number_of_edges()}")
# For very large graphs, printing info too often can be slow. Adjust interval.
print(f"\nFinished adding triples. Processed {added_edges_count} edges.")Knowledge Graph Creating the Graph with NetworkX
# (19)--- Final Graph Statistics ---
num_nodes = knowledge_graph.number_of_nodes()
num_edges = knowledge_graph.number_of_edges()
print(f"\n--- Final NetworkX Graph Summary ---\n")
print(f"Total unique nodes (entities): {num_nodes}")
print(f"Total unique edges (relationships): {num_edges}")
if num_edges != added_edges_count and isinstance(knowledge_graph, nx.DiGraph):
print(f"Note: Added {added_edges_count} edges, but graph has {num_edges}. DiGraph overwrites edges with same source/target. Use MultiDiGraph if multiple edges needed.")
if num_nodes > 0:
try:
density = nx.density(knowledge_graph)
print(f"Graph density: {density:.4f}") # How connected the graph is
if nx.is_weakly_connected(knowledge_graph): # Can you reach any node from any other, ignoring edge direction?
print("The graph is weakly connected (all nodes reachable ignoring direction).")
else:
num_components = nx.number_weakly_connected_components(knowledge_graph)
print(f"The graph has {num_components} weakly connected components.")
except Exception as e:
print(f"Could not calculate some graph metrics: {e}") # Handle potential errors on empty/small graphs
else:
print("Graph is empty, cannot calculate metrics.")
print("-" * 25)
# --- Sample Nodes ---
print("\n--- Sample Nodes (First 10) ---")
if num_nodes > 0:
nodes_sample = list(knowledge_graph.nodes())[:10]
display(pd.DataFrame(nodes_sample, columns=['Node Sample']))
else:
print("Graph has no nodes.")
# --- Sample Edges ---
print("\n--- Sample Edges (First 10 with Labels) ---")
if num_edges > 0:
edges_sample = []
for u, v, data in list(knowledge_graph.edges(data=True))[:10]:
edges_sample.append({'Source': u, 'Target': v, 'Label': data.get('label', 'N/A')})
display(pd.DataFrame(edges_sample))
else:
print("Graph has no edges.")
print("-" * 25)Knowledge Graph Interactive Graph with ipycytoscape
print("Preparing interactive visualization...")
# (20)--- Check Graph Validity for Visualization ---
can_visualize = False
if 'knowledge_graph' not in locals() or not isinstance(knowledge_graph, nx.Graph):
print("Error: 'knowledge_graph' not found or is not a NetworkX graph.")
elif knowledge_graph.number_of_nodes() == 0:
print("NetworkX Graph is empty. Cannot visualize.")
else:
print(f"Graph seems valid for visualization ({knowledge_graph.number_of_nodes()} nodes, {knowledge_graph.number_of_edges()} edges).")
can_visualize = TrueKnowledge Graph Interactive Graph with ipycytoscape
cytoscape_nodes = []
cytoscape_edges = []
if can_visualize:
print("Converting nodes...")
# Calculate degrees for node sizing
node_degrees = dict(knowledge_graph.degree())
max_degree = max(node_degrees.values()) if node_degrees else 1
for node_id in knowledge_graph.nodes():
degree = node_degrees.get(node_id, 0)
# Simple scaling for node size (adjust logic as needed)
node_size = 15 + (degree / max_degree) * 50 if max_degree > 0 else 15
cytoscape_nodes.append({
'data': {
'id': str(node_id), # ID must be string
'label': str(node_id).replace(' ', '\n'), # Display label (wrap spaces)
'degree': degree,
'size': node_size, # Store size for styling
'tooltip_text': f"Entity: {str(node_id)}\nDegree: {degree}" # Tooltip on hover
}
})
print(f"Converted {len(cytoscape_nodes)} nodes.")
print("Converting edges...")
edge_count = 0
for u, v, data in knowledge_graph.edges(data=True):
edge_id = f"edge_{edge_count}" # Unique edge ID
predicate_label = data.get('label', '')
cytoscape_edges.append({
'data': {
'id': edge_id,
'source': str(u),
'target': str(v),
'label': predicate_label, # Label on edge
'tooltip_text': f"Relationship: {predicate_label}" # Tooltip on hover
}
})
edge_count += 1
print(f"Converted {len(cytoscape_edges)} edges.")
# Combine into the final structure
cytoscape_graph_data = {'nodes': cytoscape_nodes, 'edges': cytoscape_edges}
# Visualize the converted structure (first few nodes/edges)
print("\n--- Sample Cytoscape Node Data (First 2) ---")
print(json.dumps(cytoscape_graph_data['nodes'][:2], indent=2))
print("\n--- Sample Cytoscape Edge Data (First 2) ---")
print(json.dumps(cytoscape_graph_data['edges'][:2], indent=2))
print("-" * 25)
else:
print("Skipping data conversion as graph is not valid for visualization.")
cytoscape_graph_data = {'nodes': [], 'edges': []}Knowledge Graph Interactive Graph with ipycytoscape
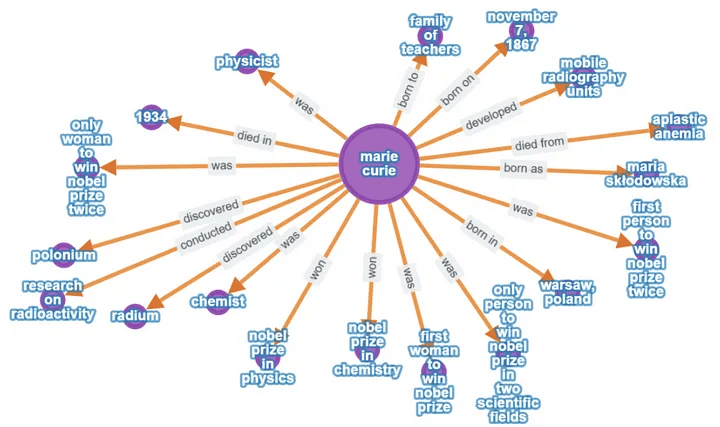
Example 2
參考來源:Steve Hedden, How to Implement Graph RAG UsingKnowledge Graphs and Vector Databases


Two Way to Implement RAG
Graph RAG: Knowledge Graph

Two Way to Implement RAG
Graph RAG: Supplying your prompt with the relevant information needed for the LLM to answer your prompt
RAG: 3 way to use KG
- Vector-based retrieval: Vectorize your KG and store it in a vector database
Baseline RAG: RAG without graph - Prompt-to-query retrieval: Use an LLM to write a SPARQL or Cypher query for you, use the query against your KG, and then use the returned results to augment your prompt.
- Hybrid (vector + SPARQL): combine two approaches above
Part I
Vectorize a dataset into a vector database to test semantic search, similarity search, and RAG (vector-based retrieval)
# (1) Install libraries (run this cell once)
pip install weaviate-client
pip install pandas# (1) Install libraries (run this cell once)
pip install weaviate-client
pip install pandasWeaviate 向量資料庫
Run under Docker with default settings(command prompt)
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.30.4The command sets the following default environment variables in the container:
- PERSISTENCE_DATA_PATH defaults to ./data
- AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED defaults to true.
- QUERY_DEFAULTS_LIMIT defaults to 10.
Weaviate 向量資料庫
Customize your Weaviate configuration: docker-compose.yml
docker run -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.30.4# (1) Install libraries (run this cell once)
pip install weaviate-client
pip install pandasKnowledge Graph
By Leuo-Hong Wang



