Practical Applications of Chatbot
Knowledge Graph-Data Preparation
Last Updated: 2025/05/06
王柳鋐

RAG Graph vs Vector
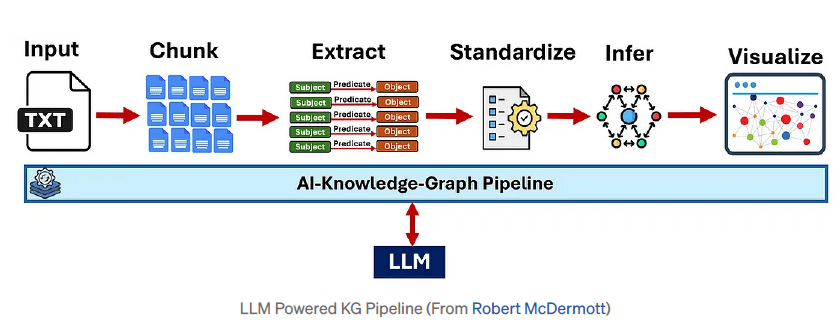
Knowledge Graph end-to-end pipeline
擷取什麼? Ontology!
Knowledge Graph Ontology
Hendler , 2001 (資訊科學領域的定義)
- 知識本體:特定領域「知識術語」組成的集合
- 用途: 分享、溝通
Hendler, J. (2001). Agents and the semantic web. IEEE Intelligent systems, 16(2), 30-37.

主觀
專業
建議上層共用知識本體
專業概念
展開



Knowledge Graph Ontology

Knowledge Graph SPO
Subject-Predicate-Object (SPO) Triples
Knowledge Graph Information Extraction
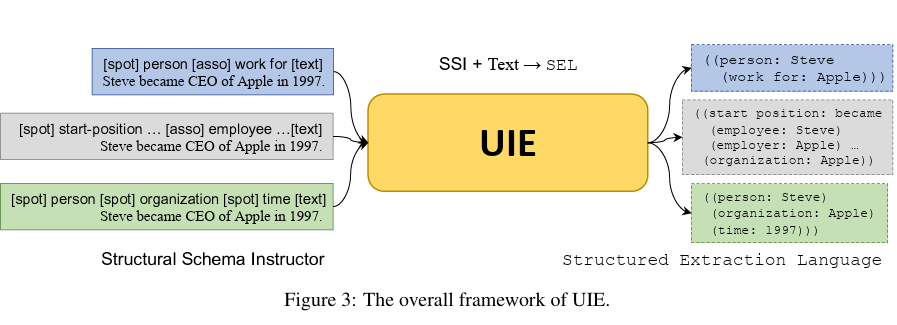
Yaojie Lu, etc, from CAS, Baidu and BAAI. Unified Structure Generation for Universal Information Extraction., ACL 2022.
網路爬蟲
簡介
關於網路爬蟲(1/3)
爬取網頁(連結) ➠ 製作網頁索引
Web crawling
應用:搜尋引擎

關於網路爬蟲(2/3)
爬取網頁內容 ➠ 轉成結構化資料
Web scraping

目的:Make smarter decisions
價格追蹤
商品評價
潛在客戶
關於網路爬蟲(3/3)
圖片來源1


圖片來源2
實作Web Scraper?(1/5)
2.1 遍訪連結
建立待訪堆疊
1. 從一個網頁開始
2.2 擷取內容
3. 輸出結果(至檔案)
圖片來源1
圖片來源2
取得HTML回應碼
解析超連結
解析其他HTML元素
資料輸出
資料清理
實作Web Scraper?(2/5)
能力1: 取得HTML回應碼?了解HTTP協定

網址(http request)
瀏覽器
Web 伺服器
HTML回應碼(http response)
實作Web Scraper?(3/5)
能力2: 解析超連結、其他HTML元素、網頁內容 ➠
HTML Parser(解析器)

符號化
建立DOM樹
關於HTML元素(1/3)

以p元素為例
元素
內容
開始標籤
結束標籤
屬性名稱
屬性值
找出超連結元素A,屬性href的值 ➠ 待訪網址
關於HTML元素(2/3)
【任務】建立待訪網址串列:
1.找到所有超連結元素A,讀取屬性href的值
2.讀取該A元素的內容(顯示於網頁的文字)
<div id="mw-pages">
<h2>類別”台灣球員“中的頁面</h2>
<p>這個分類中有以下的 200 個頁面,共有 15,436 個頁面。</p>(先前200) (
<a href="/wiki/index.php?title=%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1"
title="分類:台灣球員">之後200</a>)
<div lang="zh-tw" dir="ltr" class="mw-content-ltr">
<table style="width: 100%;">
<tr style="vertical-align: top;">
<td style="width: 33.3%;">
<h3>丁</h3>
<ul>
<li><a href="/wiki/index.php/%E4%B8%81%E4%B8%96%E5%81%89" title="丁世偉">丁世偉</a>
</li>
<li><a href="/wiki/index.php/%E4%B8%81%E4%B8%96%E6%9D%B0" title="丁世杰">丁世杰</a>
</li>
</ul>
<h3>丘</h3>
<ul>
<li><a href="/wiki/index.php/%E4%B8%98%E6%98%8C%E6%A6%AE" title="丘昌榮">丘昌榮</a>
</li>
</ul>
<h3>中</h3>
</td>
</tr>
</table>
</div>
</div>關於HTML元素(3/3)
內文:之後200 網址:http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:....
球員:丁世偉 網址:http://twbsball.dils.tku.edu.tw/wiki/index.php/%E4%B8%81%E4%B8%96%E5%81%89
球員:丁世杰 網址:http://twbsball.dils.tku.edu.tw/wiki/index.php/%E4%B8%81%E4%B8%96%E6%9D%B0
球員:丘昌榮 網址:http://twbsball.dils.tku.edu.tw/wiki/index.php/%E4%B8%98%E6%98%8C%E6%A6%AE【任務】建立待訪網址串列:
1.找到所有超連結元素A,讀取屬性href的值
2.讀取該A元素的內容(顯示於網頁的文字)
...
<a href="/wiki/index.php/%E4%B8%98%E6%98%8C%E6%A6%AE" title="丘昌榮">丘昌榮</a>
...球員:丘昌榮 網址:http://twbsball.dils.tku.edu.tw/wiki/index.php/%E4%B8%98%E6%98%8C%E6%A6%AE【問題】
1. 超連結內文:語意不同
2. href有「絕對」、「相對」路徑之分
相對路徑, 不完整
補成絕對路徑
實作Web Scraper?(4/5)
能力2: 解析超連結、其他HTML元素、網頁內容
Parser(解析器)
能力1: 取得HTML回應碼?了解HTTP協定
http連線功能
➠

圖片來源1



實作Web Scraper?(5/5)
能力3: 資料清理、資料輸出 ➠
資料處理工具
2.1 遍訪連結
建立待訪堆疊
1. 從一個網頁開始
2.2 擷取內容
3. 輸出結果(至檔案)
圖片來源1
圖片來源2
取得HTML回應碼
解析超連結
解析其他HTML元素
資料輸出
資料清理

網路爬蟲實作
☛ 單一頁面版:使用 Requests + BeautilfulSoup4
無限循環版:使用Scraper
Web Scraping範例(單一頁面版)
pip install requests
pip install beautifulsoup4
pip install lxml安裝Requests, BeautilfulSoup套件(使用pip 或 pip3)
parser部分使用lxml(速度快,也可解析XML檔)
若系統找不到pip,改用pip3
Web Scraping範例單一頁面版
import requests
from bs4 import BeautifulSoup
# Step 1: 發出Http Request, 解析(parse)Http Response
## url: 要擷取的網址
base_url = "http://twbsball.dils.tku.edu.tw" # 網站基礎網址,補絕對網址用
url = "http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1"
resp = requests.get(url) # 發出HTTP request
if resp.status_code == 200: # 代碼200表示連線正常
soup = BeautifulSoup(resp.content, "lxml") # parsing網頁內容
else:
exit(1) # 非200代碼,程式直接結束
### 維基百科頁面標題特徵: id="firstHeading"
title = soup.find(id="firstHeading") # 根據id值進行搜尋
print(f'頁面標題{title.text}')
### 維基百科頁面內容:假設只對包含在id="mw-pages"內的超連結感興趣
### 注意!!!每個網頁內容的id可能都不一樣!!!必須先詳細了解網頁格式
all_links = soup.find(id="mw-pages").find_all("a") # 找出所有<A>標籤
print(f"超連結數量:{len(all_links):10}")
# 走訪過濾後的<A>標籤:
#### 1. 只對此Wiki站內連結感興趣
#### 2. 只處理球員連結
num_of_link = 0
for link in all_links:
if link['href'].find("/wiki/") == -1: # 站外連結跳過不處理
continue
if link.text == '之後200': # 網頁特定內容,跳過不處理
print(f'type of link:{type(link)}')
continue
print(f"球員:{link.text} 網址:{base_url + link['href']}")
num_of_link += 1
print(f'球員總數{num_of_link:10}')webscraping-link.py
重要:必須先了解該網頁的HTML結構
重點觀察
- 屬性值(id, class),
- 特定標籤<div>, <h>系列, <SPAN>

前往目標網址後,開啟「開發人員工具」(F12)
任務 1: 爬取「球員連結」
但不是「所有超連結」都是球員

移動游標尋找目標區域
div標籤, id值 "mw-pages"
# 以'lxml' parser解析 resp.content的內容
soup = BeautifulSoup(resp.content, "lxml")
...
# 找出mw-pages段落裡面所有<A>標籤
all_links = soup.find(id="mw-pages").find_all("a") 任務 2: 擷取「頁面內容」

有興趣的段落沒有 id, class等屬性值可用
dl, dd, ul, li等標籤無法區分是否為感興趣的段落
url = "擷取的網址"
resp = requests.get(url) # (1)連線
if resp.status_code == 200: # 代碼200表示連線正常
soup = BeautifulSoup(resp.content, "lxml") # (2)分析
else:
exit(1) # 非200代碼,程式直接結束import requests
from bs4 import BeautifulSoupimport需要的模組
連線與分析(parsing)
### 維基百科頁面標題特徵: id="firstHeading"
title = soup.find(id="firstHeading") # 根據id值進行搜尋
print(f'頁面標題{title.text}')擷取任務1: 取得標題
### 維基百科頁面內容:假設只對包含在id="mw-pages"內的超連結感興趣
### 注意!!!每個網頁內容的id可能都不一樣!!!必須先詳細了解網頁格式
all_links = soup.find(id="mw-pages").find_all("a") #找出所有<A>標籤
# 走訪過濾後的<A>標籤:
for link in all_links:
if link['href'].find("/wiki/") == -1: # 站外連結跳過不處理
continue
if link.text == '之後200': # 網頁特定內容,跳過不處理
continue
print(f"球員:{link.text} 網址:{link['href']}") # 印出網址擷取任務2: 取出段落中的超連結
Web Scraping範例單一頁面版#2




Web Scraping範例單一頁面版#2
webscraping-player.py
from bs4 import BeautifulSoup
import requests
import pandas
sections = [ # data frame的column name,共9個
'簡介', # 同義詞段落'生平簡介'
'基本資料',
'經歷',
'個人年表',
'特殊事蹟',
'職棒生涯成績',
'備註',
'註釋或參考文獻',
'外部連結',
]
sid = { # 台灣棒球維基館的section id
'基本資料': '.E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99',
'經歷': '.E7.B6.93.E6.AD.B7',
'個人年表': '.E5.80.8B.E4.BA.BA.E5.B9.B4.E8.A1.A8',
'特殊事蹟': '.E7.89.B9.E6.AE.8A.E4.BA.8B.E8.B9.9F',
'職棒生涯成績':'.E8.81.B7.E6.A3.92.E7.94.9F.E6.B6.AF.E6.88.90.E7.B8.BE',
'備註':'.E5.82.99.E8.A8.BB',
'註釋或參考文獻': '.E8.A8.BB.E9.87.8B.E6.88.96.E5.8F.83.E8.80.83.E6.96.87.E7.8D.BB',
'外部連結': '.E5.A4.96.E9.83.A8.E9.80.A3.E7.B5.90',
'結尾': 'stub'
}
intro = {
'簡介': '.E7.B0.A1.E4.BB.8B',
'生平簡介': '.E7.94.9F.E5.B9.B3.E7.B0.A1.E4.BB.8B'
}
def extract_introduction(content, key, value):
pos = str(content).find(f'id="{value}"') # 簡介 / 生平簡介
if pos == -1:
return None
else:
next_pos = str(content).find('<span class="mw-headline" id=".E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99">基本資料</span>')
intro_str = str(content)[pos:next_pos] # 擷取 「簡介/生平簡介」 段落
# print('*****',key, len(key))
intro_str = intro_str[intro_str.find(key):] # 去掉最前面未切乾淨的html碼
# print(intro_str)
intro_soup = BeautifulSoup(intro_str, 'lxml') # parsing
texts = intro_soup.find_all(text=True) # 取出所有元素的文字,不含標籤屬性
# 資料格式為串列
return u"".join(t.strip() for t in texts) # 將串列元素接在一起形單一字串,u""為unicode
####使用字串.find()和取得子字串的功能,切出每個段落大致的內容
# 參數:
# content: http response回應的內容部份
# start: 開始字串(不含),要裁切內容的開始位置
# end: 結尾字串(不含), 裁切內容的結束位置
# 回傳:
# 裁切好的子字串
def get_sub_content(content, start, end):
start_pos = str(content).find(f'id="{start}"')
print(f'sp:{start_pos}')
if start_pos == -1: # 找不到start字串
return None
else: # 找到 start字串
end_pos = str(content).find(f'id="{end}"') # 尋找end字串
if end_pos == -1:
return None # 找不到end字串
else:
print(f'ep:{end_pos}')
return str(content)[start_pos: end_pos] # 回傳裁切子字串
#### 使用BeatuifulSoup的功能,取出以<dd></dd>包起來的段落內容
# 參數:
# html_str: 要分析的段落內容字串
# 回傳:
# 段落內容串列,每一個li為一個串列元素
def extract_dlist(html_str):
soup = BeautifulSoup(html_str, 'lxml') # parsing
li = soup.find_all('li') # 找到<li>
li_texts = [] # 空字串, 將存入所有li的文字
for item in li:
item_text = item.find_all(text=True)
if u"".join(item_text).strip() != '':
li_texts.append(u"".join(item_text).strip())
return li_texts
# Step 1: 發出Http Request, 解析(parse)Http Response
## url: 要擷取的網址
base_url = "http://twbsball.dils.tku.edu.tw"
url = "http://twbsball.dils.tku.edu.tw/wiki/index.php/%E4%BD%95%E9%9C%87%E7%83%8A"
url = "http://twbsball.dils.tku.edu.tw/wiki/index.php/%E7%8E%8B%E5%BB%BA%E6%B0%91(1980)"
resp = requests.get(url) # 發出HTTP request
if resp.status_code == 200:
soup = BeautifulSoup(resp.content, "lxml") # parsing網頁內容
else:
exit(1)
final_result = {} # 最後擷取的全文結果
all_content = soup.find(id="bodyContent") # 取得全部HTML內文
for key, value in intro.items():
pp = extract_introduction(all_content, key, value) # 取得 簡介
if pp != None:
print(f'找到{key}')
final_result[key] = pp # 簡介
break
else:
print(f'找不到{key}')
start_str = '' # 擷取段落用的開始字串
end_str = '' # 擷取段落用的結束字串
title = '' # 目前擷取的段落名稱:對應至sid的key
next_title = '' # 下一個擷取的段落名稱:對應至sid的key
for key, value in sid.items(): # 遍訪sid串列,取出定位字串
if start_str == '': # 1. 設定開始字串
start_str = value # 1.1開始字串
title = key # 1.2段落名稱
continue
else:
if end_str == '': # 2. 設定結束字串
end_str = value # 2.1 結束字串
next_title = key # 2.2 下一個段落名稱
print(title)
# 使用開始字串,結束字串取得中間的html內容
sub_content_str = get_sub_content(all_content, start_str, end_str)
if sub_content_str == None: # 如果擷取回來沒有內容
end_str = '' # 清除結束字串,繼續處理下一個sid項目
continue
# 處理擷取回來的段落內容
li_list = extract_dlist(sub_content_str) # 取出當中的li
final_result[title] = ''.join(li_list) # 紀錄起來
start_str = end_str # 設定下一段的開始字串
end_str = '' # 清除結束字串
title =next_title # 設定下一段的段落名稱
# print(final_result) # 印出擷取的資料
fr_array = [] # 準備空白表格資料
fr_array.append(final_result) # 加入一筆資料至表格
index=[i for i in range(len(fr_array))] # data frame的索引
### 建立dataframe
# 1. fr_array: 表格資料(目前只有一筆)
# 2. index=index: 前者是參數名稱,後者是第9行建立的索引串列
# 3. columns=sections: 前者是參數名稱, 後者是先前定義的欄位串列
df = pandas.DataFrame(fr_array,index=index, columns=sections)
df.to_csv('out_file.csv') # 寫出檔案(utf-8編碼)裁切子字串的函式:指定開始、結束字串,切出中間的內容
####使用字串.find()和取得子字串的功能,切出每個段落大致的內容
# 參數:
# content: http response回應的內容部份
# start: 開始字串(不含),要裁切內容的開始位置
# end: 結尾字串(不含), 裁切內容的結束位置
# 回傳:
# 裁切好的子字串
def get_sub_content(content, start, end):
start_pos = str(content).find(f'id="{start}"')
print(f'sp:{start_pos}')
if start_pos == -1: # 找不到start字串
return None
else: # 找到 start字串
end_pos = str(content).find(f'id="{end}"') # 尋找end字串
if end_pos == -1:
return None # 找不到end字串
else:
print(f'ep:{end_pos}')
return str(content)[start_pos: end_pos] # 回傳裁切子字串開始字串、結束字串包括:
sid = { # 台灣棒球維基館的section id
'基本資料': '.E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99',
'經歷': '.E7.B6.93.E6.AD.B7',
'個人年表': '.E5.80.8B.E4.BA.BA.E5.B9.B4.E8.A1.A8',
'特殊事蹟': '.E7.89.B9.E6.AE.8A.E4.BA.8B.E8.B9.9F',
'職棒生涯成績':'.E8.81.B7.E6.A3.92.E7.94.9F.E6.B6.AF.E6.88.90.E7.B8.BE',
'備註':'.E5.82.99.E8.A8.BB',
'註釋或參考文獻': '.E8.A8.BB.E9.87.8B.E6.88.96.E5.8F.83.E8.80.83.E6.96.87.E7.8D.BB',
'外部連結': '.E5.A4.96.E9.83.A8.E9.80.A3.E7.B5.90',
'結尾': 'stub'
}
開始字串、結束字串段落內都是<dd></dd>, 找出當中的<li>
#### 使用BeatuifulSoup的功能,取出以<dd></dd>包起來的段落內容
# 參數:
# html_str: 要分析的段落內容字串
# 回傳:
# 段落內容串列,每一個li為一個串列元素
def extract_dlist(html_str):
soup = BeautifulSoup(html_str, 'lxml') # parsing
li = soup.find_all('li') # 找到<li>
li_texts = [] # 空字串, 將存入所有li的文字
for item in li:
item_text = item.find_all(text=True) # 只要內文
if u"".join(item_text).strip() != '':
li_texts.append(u"".join(item_text).strip())
return li_textsli的內文才是要擷取的主體內容
球員簡介段落的格式與其他段落不同
def extract_introduction(content, value):
pos = str(content).find(f'id="{value}"') # 簡介 / 生平簡介
if pos == -1:
return None
else:
next_pos = str(content).find('<span class="mw-headline" id=".E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99">基本資料</span>')
intro_str = str(content)[pos:next_pos] # 擷取 「簡介/生平簡介」 段落
# print('*****',key, len(key))
intro_str = intro_str[intro_str.find(key):] # 去掉最前面未切乾淨的html碼
# print(intro_str)
intro_soup = BeautifulSoup(intro_str, 'lxml') # parsing
texts = intro_soup.find_all(text=True) # 取出所有元素的文字,不含標籤屬性
# 資料格式為串列
return u"".join(t.strip() for t in texts) # 將串列元素接在一起形單一字串,u""為unicodeintro = {
'簡介': '.E7.B0.A1.E4.BB.8B',
'生平簡介': '.E7.94.9F.E5.B9.B3.E7.B0.A1.E4.BB.8B'
}簡介段落有下列兩種網頁格式
soup = BeautifulSoup(resp.content, "lxml")
all_content = soup.find(id="bodyContent") # 取得全部HTML內文start_str = '' # 擷取段落用的開始字串
end_str = '' # 擷取段落用的結束字串
title = '' # 目前擷取的段落名稱:對應至sid的key
next_title = '' # 下一個擷取的段落名稱:對應至sid的key
final_result = {}
for key, value in sid.items(): # 遍訪sid串列,取出定位字串
if start_str == '': # 1. 設定開始字串
start_str = value # 1.1開始字串
title = key # 1.2段落名稱
continue
else:
if end_str == '': # 2. 設定結束字串
end_str = value # 2.1 結束字串
next_title = key # 2.2 下一個段落名稱
print(title)
# 使用開始字串,結束字串取得中間的html內容
sub_content_str = get_sub_content(all_content, start_str, end_str)
if sub_content_str == None: # 如果擷取回來沒有內容
end_str = '' # 清除結束字串,繼續處理下一個sid項目
continue
# 處理擷取回來的段落內容
li_list = extract_dlist(sub_content_str) # 取出當中的li
final_result[title] = li_list # 紀錄起來
start_str = end_str # 設定下一段的開始字串
end_str = '' # 清除結束字串
title =next_title # 設定下一段的段落名稱
print(final_result) # 印出擷取的資料取得各段落內文
網路爬蟲實作
單一頁面版:使用 Requests + BeautilfulSoup4
☛ 無限循環版:使用Scrapy
Web Scraping範例安裝所需套件
安裝Scrapy, BeautilfulSoup套件(使用pip 或 pip3)
parser部分使用lxml(速度快,也可解析XML檔)
pip install scrapy
pip install beautifulsoup4
pip install lxml若系統找不到pip,改用pip3
此範例使用
效能較佳!
Web Scraping範例建立Scrapy專案
建立Scrapy專案,例如:
scrapy startproject tutorial
你的程式加在這個資料夾內
Web Scraping範例建立爬蟲主程式
scrapy startproject mycrawler在這個資料夾內新增
twbaseball_spider.py(任何檔名皆可)

爬蟲主程式#1
資料夾內可以手動新增多隻爬蟲主程式
Web Scraping範例簡單範例
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
爬取兩個網頁,將網頁內容寫入檔案
Web Scraping範例(1) 繼承scrapy.Spider
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
class名稱自取
Web Scraping範例(2) 為spider取名
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
為spider取名
執行程式時,會指定此名稱
Web Scraping範例(3) 設定開始爬取的網址串列
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
執行時,依序爬取網頁
但不限於只爬取串列中指定的
網頁
可遞迴呼叫「回呼函式」parse()
達成無限循環
Web Scraping範例(4) 撰寫回呼函式parse()
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')twbaseball_spider.py
回呼函式
透過response參數解析內容
繼續跟進處理其他網址
回傳擷取的資料、儲存...
Web Scraping範例執行
cd mycrawler從「終端機」執行
1. 切換到專案資料最上層!
scrapy crawl quotesscrapy crawl twbaseball2. 執行scrapy crawl指令
spider名稱,自訂於程式碼中
import scrapy
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "quotes" # 2. 為spider取名
start_urls = [ # 3. 頁面擷取串列: 數量不限
'https://quotes.toscrape.com/page/1/', # 爬取網址1
'https://quotes.toscrape.com/page/2/', # 爬取網址2
]
def parse(self, response): # 4. 頁面解析
page = response.url.split("/")[-2] # 4-1 內容解析
# 4-2 資料儲存
filename = f'quotes-{page}.html' # 設定檔名
with open(filename, 'wb') as f:
f.write(response.body) # 寫入網頁<body>內容
self.log(f'Saved file {filename}')Web Scraping範例無限循環版:部份結果
import scrapy
from bs4 import BeautifulSoup
import random
import mycrawler.items as items
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "twbaseball" # 2. 為spider命名
allowed_domains = ['dils.tku.edu.tw']
start_urls = [ # 3. 頁面擷取串列
'http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1'
]
total_page = len(start_urls) # 分頁總數
num_of_player = 0 # 抓取的球員總數
player = items.Player() # 球員資料欄位->自行定義在items.py
sid = { # 台灣棒球維基館的section id
'簡介': '.E7.B0.A1.E4.BB.8B',
'基本資料': '.E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99',
'經歷': '.E7.B6.93.E6.AD.B7',
'個人年表': '.E5.80.8B.E4.BA.BA.E5.B9.B4.E8.A1.A8',
'特殊事蹟': '.E7.89.B9.E6.AE.8A.E4.BA.8B.E8.B9.9F',
'職棒生涯成績': '.E8.81.B7.E6.A3.92.E7.94.9F.E6.B6.AF.E6.88.90.E7.B8.BE',
'外部連結': '.E5.A4.96.E9.83.A8.E9.80.A3.E7.B5.90'
}
def parse(self, response): # 4. 頁面解析
next200 = False # pagination link processing flag
player_links = [] # 球員超連結串列
for link in response.css('#mw-pages').css("a"):
text = link.css('a::text').get() # 超連結的文字部分
if text == '先前200': # 先前200已經處理過了
continue
if text == '之後200': # 之後200 下一頁球員
if next200: # 已經處理過了
continue
else: # 尚未處理
next200 = True # 標示為已處理
self.total_page += 1
# yield response.follow(link, self.parse) # 連續循環版
print(f"^^^current total pages:{self.total_page}")
if random.randint(1,100)<=2:
player_links.append(link)
self.num_of_player += len(player_links)
yield from response.follow_all(player_links, self.parse_player)
print(f"***current total number of players:{self.num_of_player}")
def parse_player(self, response):
player = items.Player() # 新球員資料
soup = BeautifulSoup(response.body, 'lxml')
# 0. 球員姓名
player['name'] = soup.find(id="firstHeading").text
yield {
'title': player['name'],
}
twbaseball_spider.py
items.py:可以定義「想要擷取的欄位」
Web Scraping範例items.py
# Define here the models for your scraped items
from re import S
import scrapy
class MycrawlerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class Player(scrapy.Item): # 球員資料
url = scrapy.Field() # 網址
name = scrapy.Field() # 球員姓名
nickname = scrapy.Field() # 綽號
birthday = scrapy.Field() # 生日
height = scrapy.Field() # 身高
weight = scrapy.Field() # 體重
position = scrapy.Field() # 守備位置
intro = scrapy.Field() # 簡介全文
experience = scrapy.Field() # 經歷
event = scrapy.Field() # 年表
performance = scrapy.Field() # 特殊事蹟
record = scrapy.Field() # 成績紀錄
links = scrapy.Field() # 外部連結items.py
參考這邊的寫法
Web Scraping範例無限循環版
import scrapy
from bs4 import BeautifulSoup
import random
import mycrawler.items as items
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
name = "twbaseball" # 2. 為spider命名
allowed_domains = ['dils.tku.edu.tw']
start_urls = [ # 3. 頁面擷取串列
'http://twbsball.dils.tku.edu.tw/wiki/index.php/%E5%88%86%E9%A1%9E:%E5%8F%B0%E7%81%A3%E7%90%83%E5%93%A1'
]
....twbaseball_spider.py(部份)
所有spider都需要這三部份
Web Scraping範例無限循環版
twbaseball_spider.py(部份)
...
class TwBaseballSpider(scrapy.Spider): # 1. 繼承scrapy.Spider
...
def parse(self, response): # 4. 頁面解析
next200 = False # pagination link processing flag
player_links = [] # 球員超連結串列
for link in response.css('#mw-pages').css("a"):
text = link.css('a::text').get() # 超連結的文字部分
if text == '先前200': # 先前200已經處理過了
continue
if text == '之後200': # 之後200 下一頁球員
if next200: # 已經處理過了
continue
else: # 尚未處理
next200 = True # 標示為已處理
self.total_page += 1
# yield response.follow(link, self.parse) # 連續循環版
print(f"^^^current total pages:{self.total_page}")
if random.randint(1,100)<=2:
player_links.append(link)
self.num_of_player += len(player_links)
yield from response.follow_all(player_links, self.parse_player)
print(f"***current total number of players:{self.num_of_player}")
...主要的回呼函式
無限循環? 透過遞迴達成!
如何辦到無限循環?特殊的遞迴呼叫(產生器):yield, yield from
...
yield from response.follow_all(player_links, self.parse_player)
.......
yield response.follow(link, self.parse) # 連續循環版
....連往下一個超連結link,並呼叫parse()回呼函式
yield: 生成器,類似return,但可節省許多記憶體
連往player_links內所有超連結,並呼叫parse_player()回呼函式
yield from:產生許多生成器
資料清理與I/O
➊ 用不到、不相關
➋ 資料闕漏
刪除一筆、刪除一欄、補遺
刪除欄位
➌ 資料型別錯誤
重填正確型別資料
資料清理使用pandas DataFrame與Numpy
讀取檔案

Web

●●●

建立資料結構

資料清理
輸出
●●●
資料庫

Data Frame

一張表格

Data Frame
欄位名稱
有無索引
資料闕漏
資料清理
1. 讀寫檔案
2. 資料清理

pip install pandas
pip install numpy
Pandas安裝
Pandas範例1:寫出csv檔
from bs4 import BeautifulSoup
import requests
import pandas
sections = [ # data frame的column name,共9個
'簡介', # 同義詞段落'生平簡介'
'基本資料',
'經歷',
'個人年表',
'特殊事蹟',
'職棒生涯成績',
'備註',
'註釋或參考文獻',
'外部連結',
]
sid = { # 台灣棒球維基館的section id
'基本資料': '.E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99',
'經歷': '.E7.B6.93.E6.AD.B7',
'個人年表': '.E5.80.8B.E4.BA.BA.E5.B9.B4.E8.A1.A8',
'特殊事蹟': '.E7.89.B9.E6.AE.8A.E4.BA.8B.E8.B9.9F',
'職棒生涯成績':'.E8.81.B7.E6.A3.92.E7.94.9F.E6.B6.AF.E6.88.90.E7.B8.BE',
'備註':'.E5.82.99.E8.A8.BB',
'註釋或參考文獻': '.E8.A8.BB.E9.87.8B.E6.88.96.E5.8F.83.E8.80.83.E6.96.87.E7.8D.BB',
'外部連結': '.E5.A4.96.E9.83.A8.E9.80.A3.E7.B5.90',
'結尾': 'stub'
}
intro = {
'簡介': '.E7.B0.A1.E4.BB.8B',
'生平簡介': '.E7.94.9F.E5.B9.B3.E7.B0.A1.E4.BB.8B'
}
def extract_introduction(content, key, value):
pos = str(content).find(f'id="{value}"') # 簡介 / 生平簡介
if pos == -1:
return None
else:
next_pos = str(content).find('<span class="mw-headline" id=".E5.9F.BA.E6.9C.AC.E8.B3.87.E6.96.99">基本資料</span>')
intro_str = str(content)[pos:next_pos] # 擷取 「簡介/生平簡介」 段落
# print('*****',key, len(key))
intro_str = intro_str[intro_str.find(key):] # 去掉最前面未切乾淨的html碼
# print(intro_str)
intro_soup = BeautifulSoup(intro_str, 'lxml') # parsing
texts = intro_soup.find_all(text=True) # 取出所有元素的文字,不含標籤屬性
# 資料格式為串列
return u"".join(t.strip() for t in texts) # 將串列元素接在一起形單一字串,u""為unicode
####使用字串.find()和取得子字串的功能,切出每個段落大致的內容
# 參數:
# content: http response回應的內容部份
# start: 開始字串(不含),要裁切內容的開始位置
# end: 結尾字串(不含), 裁切內容的結束位置
# 回傳:
# 裁切好的子字串
def get_sub_content(content, start, end):
start_pos = str(content).find(f'id="{start}"')
print(f'sp:{start_pos}')
if start_pos == -1: # 找不到start字串
return None
else: # 找到 start字串
end_pos = str(content).find(f'id="{end}"') # 尋找end字串
if end_pos == -1:
return None # 找不到end字串
else:
print(f'ep:{end_pos}')
return str(content)[start_pos: end_pos] # 回傳裁切子字串
#### 使用BeatuifulSoup的功能,取出以<dd></dd>包起來的段落內容
# 參數:
# html_str: 要分析的段落內容字串
# 回傳:
# 段落內容串列,每一個li為一個串列元素
def extract_dlist(html_str):
soup = BeautifulSoup(html_str, 'lxml') # parsing
li = soup.find_all('li') # 找到<li>
li_texts = [] # 空字串, 將存入所有li的文字
for item in li:
item_text = item.find_all(text=True)
if u"".join(item_text).strip() != '':
li_texts.append(u"".join(item_text).strip())
return li_texts
# Step 1: 發出Http Request, 解析(parse)Http Response
## url: 要擷取的網址
base_url = "http://twbsball.dils.tku.edu.tw"
url = "http://twbsball.dils.tku.edu.tw/wiki/index.php/%E4%BD%95%E9%9C%87%E7%83%8A"
url = "http://twbsball.dils.tku.edu.tw/wiki/index.php/%E7%8E%8B%E5%BB%BA%E6%B0%91(1980)"
resp = requests.get(url) # 發出HTTP request
if resp.status_code == 200:
soup = BeautifulSoup(resp.content, "lxml") # parsing網頁內容
else:
exit(1)
final_result = {} # 最後擷取的全文結果
all_content = soup.find(id="bodyContent") # 取得全部HTML內文
for key, value in intro.items():
pp = extract_introduction(all_content, key, value) # 取得 簡介
if pp != None:
print(f'找到{key}')
final_result[key] = pp # 簡介
break
else:
print(f'找不到{key}')
start_str = '' # 擷取段落用的開始字串
end_str = '' # 擷取段落用的結束字串
title = '' # 目前擷取的段落名稱:對應至sid的key
next_title = '' # 下一個擷取的段落名稱:對應至sid的key
for key, value in sid.items(): # 遍訪sid串列,取出定位字串
if start_str == '': # 1. 設定開始字串
start_str = value # 1.1開始字串
title = key # 1.2段落名稱
continue
else:
if end_str == '': # 2. 設定結束字串
end_str = value # 2.1 結束字串
next_title = key # 2.2 下一個段落名稱
print(title)
# 使用開始字串,結束字串取得中間的html內容
sub_content_str = get_sub_content(all_content, start_str, end_str)
if sub_content_str == None: # 如果擷取回來沒有內容
end_str = '' # 清除結束字串,繼續處理下一個sid項目
continue
# 處理擷取回來的段落內容
li_list = extract_dlist(sub_content_str) # 取出當中的li
final_result[title] = ''.join(li_list) # 紀錄起來
start_str = end_str # 設定下一段的開始字串
end_str = '' # 清除結束字串
title =next_title # 設定下一段的段落名稱
# print(final_result) # 印出擷取的資料
fr_array = [] # 準備空白表格資料
fr_array.append(final_result) # 加入一筆資料至表格
index=[i for i in range(len(fr_array))] # data frame的索引
### 建立dataframe
# 1. fr_array: 表格資料(目前只有一筆)
# 2. index=index: 前者是參數名稱,後者是第9行建立的索引串列
# 3. columns=sections: 前者是參數名稱, 後者是先前定義的欄位串列
df = pandas.DataFrame(fr_array,index=index, columns=sections)
df.to_csv('out_file.csv') # 寫出檔案(utf-8編碼)webscraping-player.py
Pandas範例1:寫出csv檔
from bs4 import BeautifulSoup
import requests
import pandas
....
# print(final_result) # 印出擷取的資料
fr_array = [] # 準備空白表格資料
fr_array.append(final_result) # 加入一筆資料至表格
index=[i for i in range(len(fr_array))] # data frame的索引
### 建立dataframe
# 1. fr_array: 表格資料(目前只有一筆)
# 2. index=index: 前者是參數名稱,後者是第9行建立的索引串列
# 3. columns=sections: 前者是參數名稱, 後者是先前定義的欄位串列
df = pandas.DataFrame(fr_array,index=index, columns=sections)
df.to_csv('out_file.csv') # 寫出檔案(utf-8編碼)webscraping-player.py(部份)
Pandas範例2:讀寫csv檔
#-*-coding:UTF-8 -*-
# 讀取馬偕日記csv檔,使用CKIP斷詞、實體辨識進行處理, 並作統計
# Import Ckip Transformers module
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
import pandas as pd
def read_file(fn):
df = pd.read_csv(fn,names=['date','content']) # 日記無header,自訂header為'date','content'
df['content'] = df['content'].str.strip() # 去除日記內容頭尾的空白字元
print(df.info())
return df
# 步驟一: 讀取馬偕日記
data_file = './data/MackayFull-202209-utf8.csv'
out_file = './data/MackayFull-202209-Output-utf8.csv'
df = read_file(data_file)
# print(df)
# 步驟二: load models
ws_driver = CkipWordSegmenter(model="bert-base")
print('word segmenter loaded...')
pos_driver = CkipPosTagger(model="bert-base")
print('Pos Tagger loaded...')
ner_driver = CkipNerChunker(model="bert-base")
df['word_segment'] = ws_driver(df['content']) # 斷詞
df['part_of_speech'] = pos_driver(df['content']) # 詞性標記
df['ner_chunker'] = ner_driver(df['content']) # 實體辨識
# 合併 斷詞 於 詞性標記 的結果
sub_df = df[['word_segment','part_of_speech']] # 取出斷詞、詞性標記
word_with_pos = list()
for index in range(sub_df.shape[0]): # 每一筆
print('處理第 %d 筆' % index)
ws = sub_df['word_segment'][index] # 斷詞結果
pos = sub_df['part_of_speech'][index] # 詞性標記結果
count = 0 # 指標 for part_of_speech
words = list()
for word in ws: # 每一筆
# print(word, pos[count], sep=' ')
words.append([word, pos[count]])
count += len(word)
word_with_pos.append(words)
df['word_with_pos'] = word_with_pos
print(df['word_with_pos'])
print(df['ner_chunker'])
'''
# 版本1: 只取部分欄位
out_field = ['date','content','word_with_pos','ner_chunker']
out_df=df[out_field]
out_df.to_csv(out_file, sep='\t', encoding='utf-8')
'''
# 版本2: 輸出所有欄位
df.to_csv(out_file, sep='\t', encoding='utf-8')
02Mackay.py
有使用BERT處理文字(需另外安裝)
pip install -U transformersPandas範例2:讀寫csv檔
...
import pandas as pd
def read_file(fn):
# 日記無header,自訂header為'date','content'
df = pd.read_csv(fn,names=['date','content'])
df['content'] = df['content'].str.strip() # 去除頭尾空白字元
print(df.info())
return df
# 步驟一: 讀取馬偕日記
data_file = './data/MackayFull-202209-utf8.csv'
out_file = './data/MackayFull-202209-Output-utf8.csv'
df = read_file(data_file)
# print(df)
...02Mackay.py(部份)
Pandas範例2:讀寫csv檔
02Mackay.py(部份)
...
out_file = './data/MackayFull-202209-Output-utf8.csv'
df = read_file(data_file)
...
#...處理日記內容...
...
# 版本1: 只取部分欄位
out_field = ['date','content','word_with_pos','ner_chunker']
out_df=df[out_field]
out_df.to_csv(out_file, sep='\t', encoding='utf-8')
# 版本2: 輸出所有欄位
df.to_csv(out_file, sep='\t', encoding='utf-8')
資料清理
1. 讀寫檔案
2. 資料清理
移除不相關欄位
columns_to_drop = ['PassengerId', 'SibSp',
'Parch', 'WikiId',
'Name_wiki', 'Age_wiki']
df.drop(columns_to_drop, inplace=True, axis=1)
df.head()移除這些欄位
.drop() 移除, axis=1 代表columns
.head() 印出前面5筆
取代空白值
import pandas as pd
df = pd.read_csv('data.csv')
df.fillna(130, inplace = True)
print(df.to_string())以130取代空白值
Q. 該以什麼值取代空白值?
import pandas as pd
df = pd.read_csv('data.csv')
df["Calories"].fillna(130, inplace = True)更改錯誤格式
import pandas as pd
df = pd.read_csv('data.csv')
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())更改錯誤資料
import pandas as pd
df = pd.read_csv('data.csv')
df.loc[7,'Duration'] = 45
print(df.to_string())
import pandas as pd
df = pd.read_csv('data.csv')
for x in df.index:
if df.loc[x, "Duration"] > 120:
df.loc[x, "Duration"] = 120
print(df.to_string())
Practical Application of Chatbot
By Leuo-Hong Wang



