Graph RAG
Enhancing RAG with Knowledge Graphs
What is RAG?
- RAG = Retrieval Augmented Generation
- Combines LLM with external data via vector databases
- Used in AI chatbots, recommendation systems, etc.
Retrieval Augmented Generation
attention, 2014/09
seq2seq model, 2014/09
Transformer, 2017/06
GPT-2, 2019
BERT, 2018/10
Prompt Engineering, 2018/06
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
RAG, 2020/05

RAG for knowledge intensive tasks
1. parametric memory: a pre-trained seq2seq model
2. non-parametric memory: a dense vector index of Wikipedia
e.g. word embedding
embedding of x
向量搜尋
embedding of 文件zi
向量搜尋前n名
RAG for Knowledge Intensive Tasks
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
non-parametric memory: a dense vector index of Wikipedia
內部知識
外部知識

語言模型
vector embedding
或
graph embedding
問題
解答
parametric memory: a pre-trained seq2seq model
實作方式

RAG Research Framework
RAG Limitations
- Struggles with complex multi-hop reasoning
- Only retrieves semantically similar text
- Fails in answering specific or contextual queries
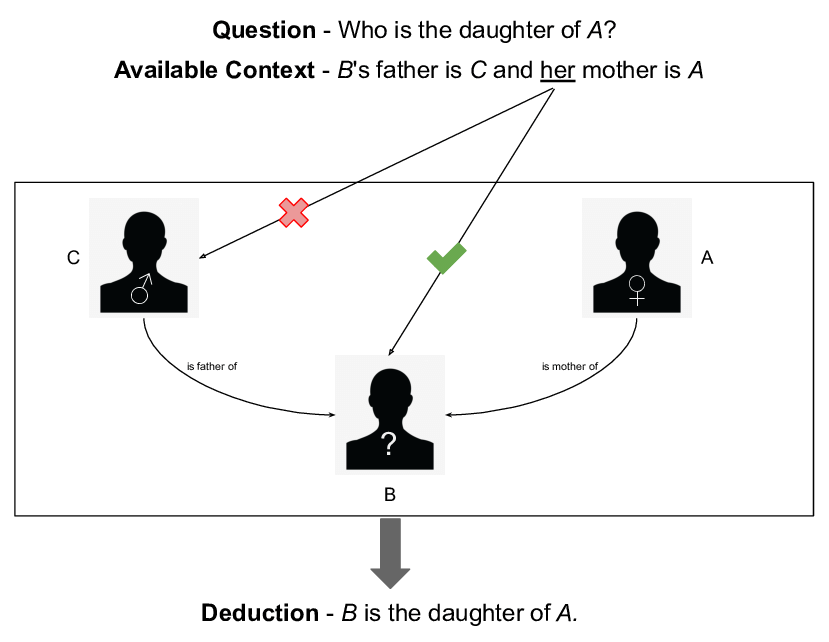
Multi-hop reasoning:模型能夠連結context中或跨不同來源的資訊片段,得出結論或解答。 這意味著模型能進行多個推理步驟,而非只根據單一訊息
Multi-hop reasoning
Vector Embeddings
Central to many NLP, recommendation, and search algorithms.

數值
物件、文字、圖像...
Vector Embeddings semantic similarity
Vector Space: semantic similarity
Barančíková, P., & Bojar, O. (2019). In search for linear relations in sentence embedding spaces.

傳統的 RAG 系統無法正確回答「特定或具上下文依賴」的問題。
Fail to answer some kind of questions
❌ 1. 特定問題(Specific Queries)
這類問題需要精準細節,例如:
「打敗篡位者 Allectus 的那個人的兒子叫什麼名字?」
傳統 RAG 可能找不到同一段文字同時提到「Allectus」、「打敗他的人」和「他兒子的名字」,因為它只能比對「語意相近」的段落。
❌ 2. 具上下文依賴的問題(Contextual Queries)
這類問題需要跨多段資料或多步推理才能得出答案,例如:
「誰在 VIINA (暴力事件資訊) 資料集中對抗了最多組織?」
這需要將多個段落的資訊匯整、統計,甚至推理。傳統 RAG 做不到這種跨段聚合與邏輯連結。
GraphRAG to the Rescue
- Enhances RAG using Knowledge Graphs
- Improves retrieval and generation quality
- Enables multi-hop and complex reasoning
One of the solutions: 知識圖譜 + 向量資料庫 + LLM 管道式運作
Knowledge Graph 什麼是Knowledge graph
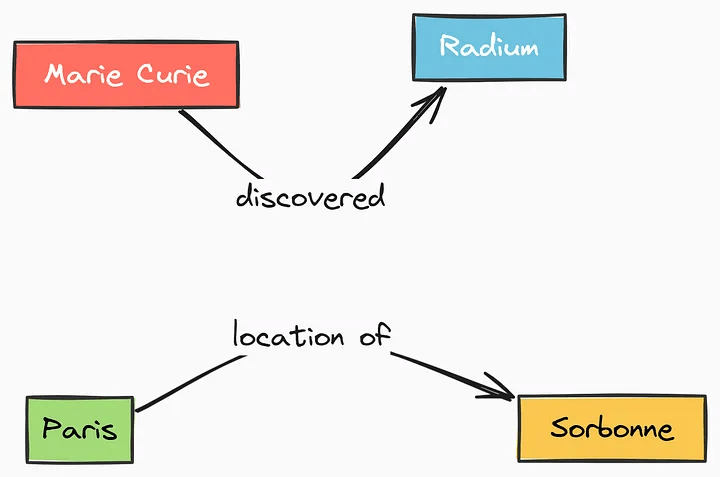
Subject-Predicate-Object (SPO) Triples
Graph RAG how to implement
1️⃣ 建構知識圖譜:整理事實與實體關係
透過 LLM 對文本做 Entity + Relation + Claim(Event/Fact) 抽取,構建出:
- 節點(Nodes):人名、地名、組織等實體
- 邊(Edges):關係,如「是父親」、「擊敗了」、「屬於組織」
🔗 這樣的圖譜讓系統知道:
「Constantius —是父親→ Constantine」、「Constantius —擊敗了→ Allectus」
Graph RAG how to implement
2️⃣ 問題轉換成查圖任務
使用者輸入複雜問題,GraphRAG 會:
- 將問題分解為數個子問題(使用 prompt 分析技巧)
- 每個子問題對應一段圖譜查詢路徑
- 如有需要,也會補充向量檢索結果
Graph RAG how to implement
3️⃣ 使用 Global + Local Search 提取資料
模式 用途
🌐 Global Search 查詢跨整體社群(用於摘要或概觀類問題)
🧩 Local Search 查詢特定實體及其關聯(如查某人或某機構的資料)
兩者都會根據圖譜社群結構、關聯程度等排序並構建上下文,提供給 LLM。
Graph RAG how to implement
4️⃣ 利用 LLM 推理並生成答案
LLM 不只是原始生成,而是根據:
- 多步查詢結果(各個子答案)
- 社群摘要(透過 GPT 模型預先整理)
- 關聯圖譜的語義路徑
來做出有結構的回答,例如:
「Constantius 擊敗了 Allectus。他的兒子是 Constantine。」
Graph RAG how to implement
📦 示意圖(可想像成)
問題 → 子問題1 → 子答案1
→ 子問題2(基於答案1) → 子答案2
→ 聚合推理 → 最終答案
Knowledge Graphs (KGs)
- Nodes: Entities (people, places, etc.)
- Edges: Relationships
- Built automatically via LLM-based extraction
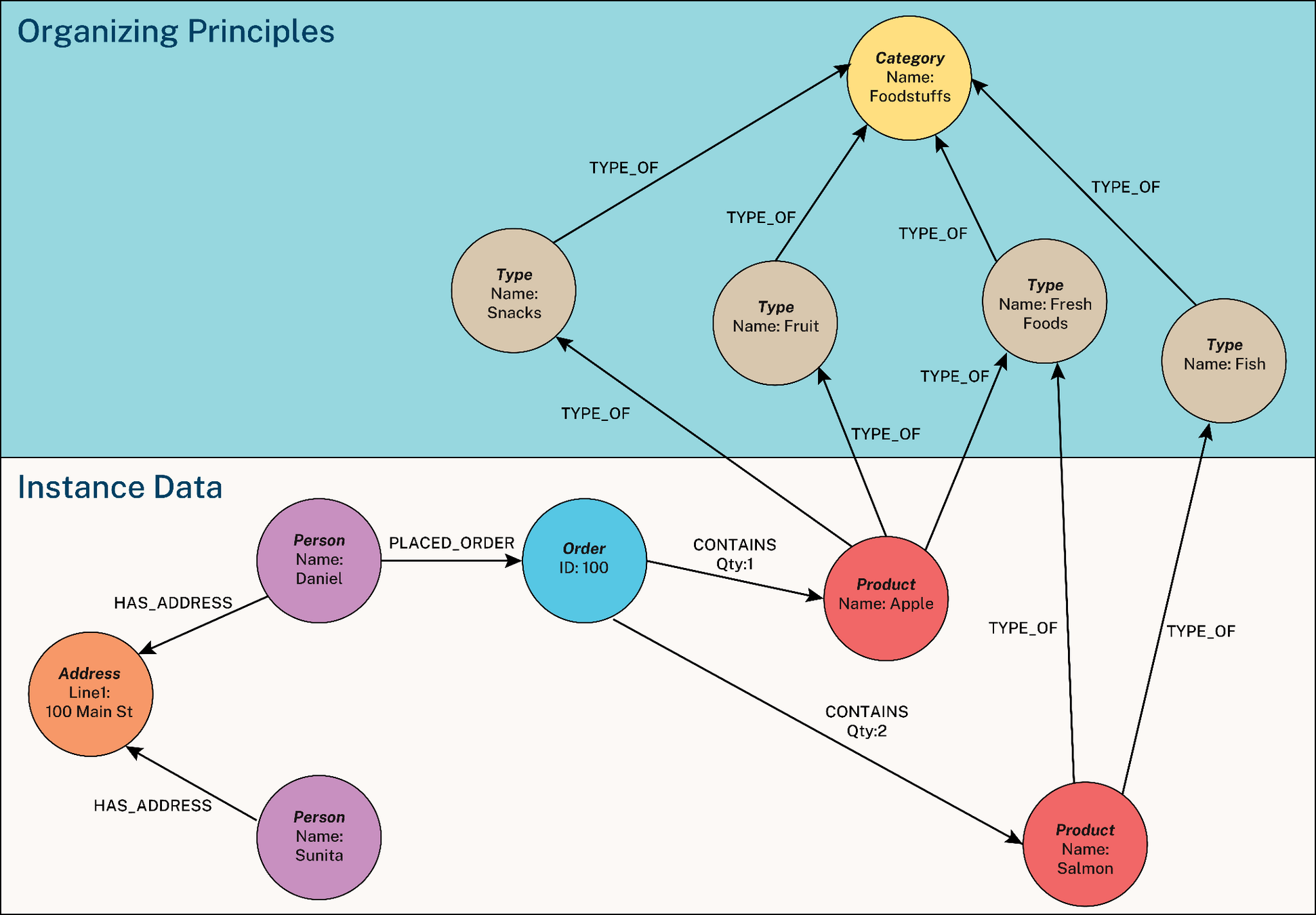
Knowledge Graph nodes, edges
🧱 1. 原始資料
例如一段文章:
「Steve Jobs 創辦了 Apple,並在矽谷科技圈具有重要影響力。」
Knowledge Graph auto-generation
🧠 2. 用 LLM 抽取資訊(SPO 三元組)
讓 LLM 處理這段文字,自動產生出三元組(triples):
Knowledge Graph auto-generation
[
{ "subject": "Steve Jobs", "predicate": "創辦了", "object": "Apple" },
{ "subject": "Steve Jobs", "predicate": "具有影響力於", "object": "矽谷科技圈" }
]
🌐 3. 組成 Knowledge Graph
把所有三元組變成節點(實體)與邊(關係):
Knowledge Graph auto-generation
[Steve Jobs] ——創辦了——> [Apple]
[Steve Jobs] ——影響——> [矽谷科技圈]也就是知識圖譜的基本結構
Knowledge Graph auto-generation
建議方案(供參考)
GraphRAG Pipeline: Indexing
- Text Segmentation (Chunking)
- Entity/Relation/Claim Extraction (IE)
- Hierarchical Clustering (Leiden)
- Community Summary Generation
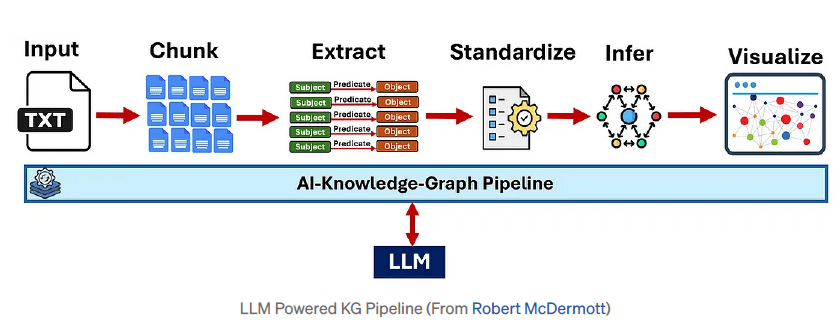
Knowledge Graph end-to-end pipeline
擷取什麼? Ontology!
Knowledge Graph Information Extraction
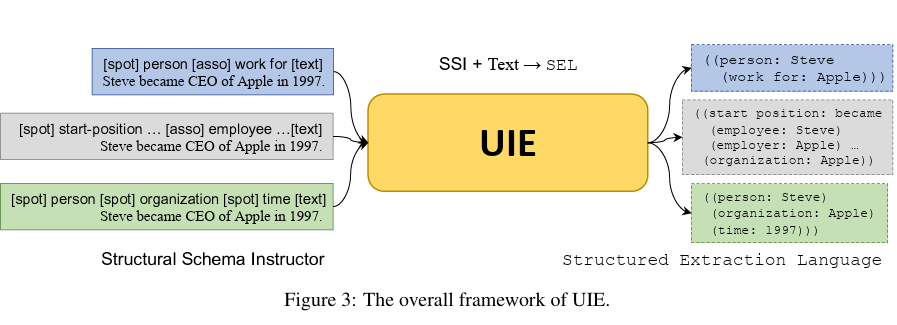
Yaojie Lu, etc, from CAS, Baidu and BAAI. Unified Structure Generation for Universal Information Extraction., ACL 2022.
Knowledge Graph Hierarchical Clustering
🧱 3. Hierarchical Clustering(Leiden 演算法)
✅ 是什麼?
用圖論演算法把「相關的實體」分群,例如:
- 一群實體都跟「台灣科技」相關
- 一群都跟「人物:張忠謀、劉德音」相關
🔍 Leiden 是什麼?
Leiden 是一種用來找出社群(community)結構的演算法,它會依據節點間的連結密度把圖分成幾個「群組」,每個群就是一個主題社群。
Knowledge Graph Hierarchical Clustering
🧾 4. Community Summary Generation(社群摘要生成)
✅ 是什麼?
系統會自動為每一個社群生成摘要,描述這個社群內的內容:
例如:
「這個社群包含多個與台灣半導體產業有關的實體,如台積電、聯發科,與其關聯人物張忠謀與蔡明介。」
🧠 目的?
- 幫助使用者快速理解圖的區塊內容
- 作為後續回答「整體性問題」的上下文材料(global search)
GraphRAG Pipeline: Querying
Two types:
- Global Search - broad queries
- Local Search - focused on specific entities
🔍 1️⃣ Global Search(全域搜尋)
✅ 用途:
處理整體性、總結型問題,例如:
- 「這份文件的主要主題是什麼?」
- 「有哪些人物對衝突有重大影響?」
- 「請列出這份資料集的前五大趨勢」
🧠 怎麼做?
- 利用 社群摘要(Community Summary)
- 把這些摘要分批 → 生成多個中間回應(intermediate responses)
- 經過評分、排序、過濾 → 彙整成一個完整答覆
📦 適合場景:
主題分類/趨勢分析/資料集統整
Internal Knowledge Search Global vs Local
🧭 2️⃣ Local Search(在地搜尋)
✅ 用途:
處理特定實體相關問題,例如:
- 「Leonardo da Vinci 做過哪些作品?」
- 「張忠謀與台積電之間的關係?」
- 「Apple 被誰創辦?」
🧠 怎麼做?
- 找出與問題相關的實體
- 透過向量資料庫(如 Milvus)做語意相似搜尋
- 從圖譜中找出與該實體有關的所有資料(關係、屬性、社群)
- 組合這些資訊給 LLM 回答
📦 適合場景:
實體查詢/關係追蹤/資料導覽式問答
Internal Knowledge Search Global vs Local
功能 Global Search Local Search
| 問題範例 | 「前五大主題是什麼?」 | 「A 和 B 的關係是什麼?」 |
| 對象 | 整份資料(跨社群) | 特定人/物(局部) |
| 使用資料 | 社群摘要 + 子回答 + 聚合生成 | 實體相似度 + 知識圖譜鄰接節點 |
| 回答類型 | 總結式、彙整式 | 精準描述、深度解釋 |
| 用途 | 概觀、摘要、多角度分析 | 查詢某實體、追溯某事件或關聯 |
Internal Knowledge Search Global vs Local
Global Search Workflow
- User query + history
- Community report batching
- Rated intermediate responses (RIR)
- Ranking → Aggregated response → Final answer
回答「整體性、多層次」的問題
1️⃣ User Query + Conversation History(使用者提問+對話歷史)
使用者輸入的問題,與之前的對話內容(如果有)會一起作為查詢依據
例如:
使用者問:「這份報告的主要主題有哪些?」
系統會連同先前的上下文來理解「這份報告」是指什麼資料集。
Global Search Workflow
2️⃣ Community Report Batching(社群摘要分批)
GraphRAG 先把知識圖譜中的實體分成社群(例如:「人物群」、「事件群」、「組織群」),再為每個社群產生摘要報告(community report)。
然後這些摘要會被打亂(shuffle)並分批(batch)處理。
為什麼要分批?
- LLM 無法一次處理全部社群資料(太長)
- 分批可以讓系統「多角度思考」
Global Search Workflow
3️⃣ Rated Intermediate Responses(中繼回應 + 打分)
每一批社群摘要會丟給 LLM 問一次問題,產生一份「中間答案(intermediate response)」。
每份中間答案裡會有:
- 多個「重點 point」
- 每個 point 都有重要性分數
📌 這些稱為 RIR (Rated Intermediate Responses)
Global Search Workflow
4️⃣ Ranking & Filtering(排序與過濾)
系統會將所有中間回應整合,並依照「分數」來:
- 排序:找出哪些 point 最重要
- 過濾:移除重複、不相關、不重要的內容
Global Search Workflow
5️⃣ Aggregated Response → Final Answer(聚合 → 最終回覆)
將最重要的資訊聚合成新的提示(prompt context),交給 LLM 最後生成一個完整且具上下文的答案。
[使用者問題 + 歷史]
↓
[多個社群摘要分批]
↓
[每批 → 中繼回應(RIR)+ 打分]
↓
[整合所有中繼點 → 排序、過濾]
↓
[最終聚合 → 一次回答]
Global Search Workflow
簡化流程圖
📌 為什麼這樣做?
複雜問題往往牽涉很多面向,Global Search 就像「組織多個專家小組報告」,再請 LLM 統整成一篇高品質的回答。
Local Search Workflow
- Entity matching
- Entity-text mapping
- Relationship + covariate extraction
- Use of community reports + context history
回答聚焦在特定人物、事件或概念的問題。這種搜尋更精準、針對性強,適合處理「某某是誰」、「他做過什麼」這類問題。
Local Search Workflow
1️⃣ Entity Matching(實體匹配)
從使用者的問題中找出關鍵實體(人名、地名、事件名等),並去圖譜中比對相關的節點。
🧠 使用什麼?
用語意向量相似度來判斷,比如使用 Milvus 或 FAISS 等向量資料庫。
例子:
問題:「請介紹 Leonardo da Vinci 的作品」
系統會從圖譜中找出「Leonardo da Vinci」這個實體節點
Local Search Workflow
2️⃣ Entity-Text Mapping(實體對應原始文字)
找到跟這個實體有關的文字來源(text units),例如:
- 哪些段落曾提到他?
- 哪些文件描述了他的關鍵事蹟?
用途?
- 這些原始段落可以提供更完整的語境,幫助回答問題。
Local Search Workflow
3️⃣ Relationship + Covariate Extraction(關係與屬性萃取)
從知識圖譜中取出這個實體的:
- 關係(relationships):例如「創作了《最後的晚餐》」、「是達文西學派的成員」
- 屬性(covariates):例如「出生年份:1452」、「職業:藝術家、工程師」
🧠 「Covariates」這個詞在統計學中是「協變數」,在這裡可理解為「附屬資料」或「屬性資訊」。
Local Search Workflow
4️⃣ Use of Community Reports + Context History(加上社群摘要與對話歷史)
除了實體本身的資訊,還會引用:
- 該實體所屬社群的摘要(如:文藝復興藝術家群組)
- 使用者對話歷史(如前面問過「他有參與哪些工程?」)
這些上下文資料提供更準確的背景給 LLM,避免答非所問。
Local Search Workflow

Comparison Example
Dataset: VIINA
- Question: Top 5 themes?
- Baseline RAG: irrelevant results
- GraphRAG: accurate, thematically aligned output
GraphRAG 與傳統 RAG 在真實案例下的對比實驗
Experiments
📚 比較範例(Comparison Example)
🔎 資料集:VIINA
VIINA = Violent Incident Information from News Articles
👉 它是一個包含大量暴力事件新聞報導的資料集,內容複雜、資訊片段、事件多樣,適合測試 AI 是否能處理多樣敘事與多重觀點。
Experiments
❓ 問題:What are the top 5 themes?
「這份資料集的五大主題是什麼?」
這是一個高層次、需要整體理解的問題,屬於典型的 Global Search 問題。
Experiments
🔁 結果比較:

Experiments
🧠 為什麼 GraphRAG 表現好?
-
✅ Baseline RAG 只能找「語意相近」的句子
- 它可能檢索到的是一些新聞段落,但這些段落無法構成整體主題
- 缺乏整合與推理,導致回答不集中、不正確
-
✅ GraphRAG 可以:
- 利用社群摘要(從知識圖譜結構萃取)
- 彙整多個主題點(Rated Intermediate Responses)
- 聚合出有組織、有依據的主題清單
GraphRAG Benefits
- Better comprehensiveness
- Greater diversity of perspectives
- Improved factual grounding
✅ 1. Better Comprehensiveness(更全面的回答)
GraphRAG 可以整合來自多個來源或角度的資訊,不會只依賴一或兩段資料
因為:
- 會用全域社群摘要(global community reports)
- 會進行多輪資訊聚合(multi-hop aggregation)
- 會結合 claim 與關聯關係 建構上下文
例如:
問題:「Leonardo da Vinci 的貢獻有哪些?」
- 傳統 RAG 可能只講到畫作(如《最後的晚餐》)
-
GraphRAG 可以同時涵蓋:
- 藝術成就/解剖學貢獻/工程設計/科學觀察/當時社會影響力
Benefits
🎨 2. Greater Diversity of Perspectives(更多元的觀點)
GraphRAG 能呈現資料中不同來源、立場或角度,不只是一種敘事。
因為它會根據不同社群(例如新聞來源、人物陣營)生成摘要,並用圖譜方式保留多種聲音。
舉例:
問題:「VIINA 資料集中的暴力事件怎麼發生的?」
- 傳統 RAG 可能只提到政府方說法
-
GraphRAG 會呈現:
- 政府說是「反恐行動」
- 當地民眾認為是「國家暴力」
- NGO 說是「人道危機」
- 媒體報導出現矛盾與模糊
Benefits
📏 3. Improved Factual Grounding(更強的事實依據)
GraphRAG 提供的答案有更明確的資料來源、實體關係與上下文根據,比較不會產生幻覺(hallucination)。
因為
- 它會引用知識圖譜的實體與關係
- 支援引用社群摘要與原始段落
- 可以標註回答來自哪些 claim 或資料點
舉例:
問題:「誰創辦了 Apple?」
- 傳統 RAG 可能會因為語意模糊說成「Steve Wozniak」
- GraphRAG 會確認圖譜中「Steve Jobs — 創辦了 → Apple」關係,給出明確正確答案
Benefits
Benefits

Implementing GraphRAG
GraphRAG implementation, please refer to the GraphRAG paper
GraphRAG Local Ollama - Knowledge Graph
- 建立並進入python虛擬環境
- 安裝ollama
-
下載ollama model: (llm, embedding model)
-
-
複製儲存庫, 安裝套件等
- 建立知識庫內容
GraphRAG Local Ollama - Knowledge Graph
ollama pull llama3.2:1b #llm
ollama pull nomic-embed-text #embeddinggit clone https://github.com/TheAiSingularity/graphrag-local-ollama.git
cd graphrag-local-ollama/
pip install -e .mkdir -p ./ragtest/input
cp input/* ./ragtest/input- 初始化檔案結構
-
- 編修設定檔內容
GraphRAG Local Ollama - Knowledge Graph
python -m graphrag.index --init --root ./ragtestcp settings.yaml ./ragtest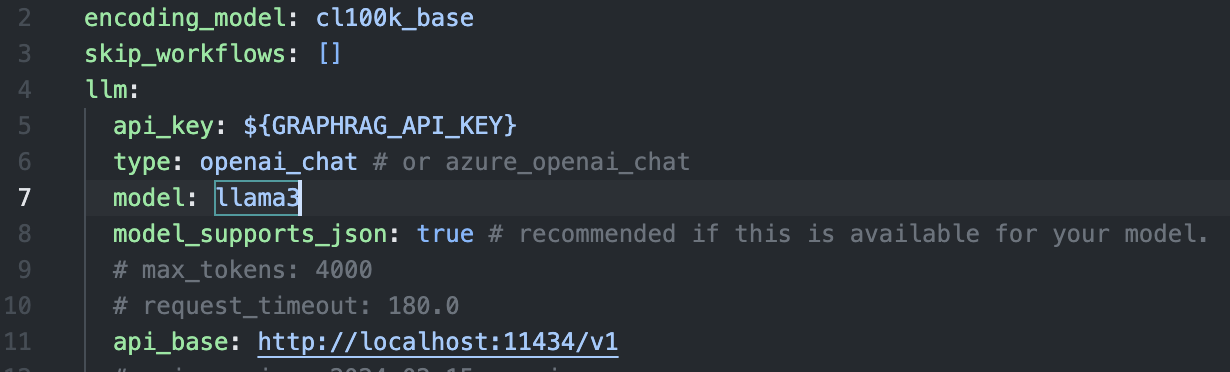
語言模型設定
GraphRAG Local Ollama - Knowledge Graph
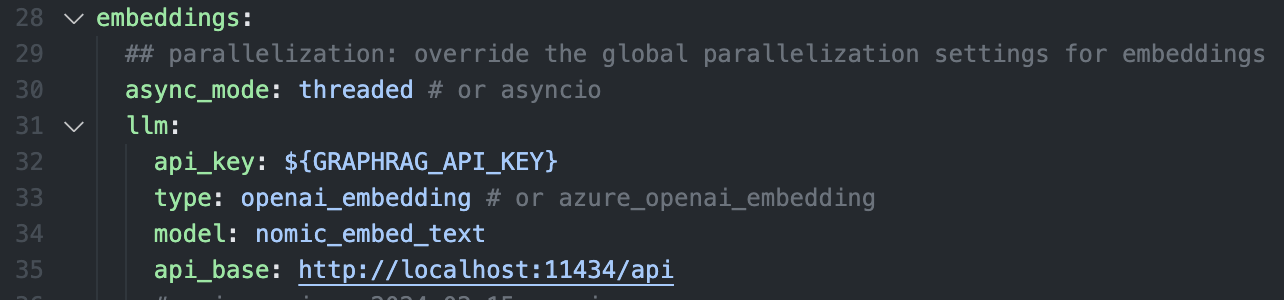
embedding模型設定
GRAPHRAG_API_KEY=-
清除.env檔的API_KEY設定(local server不需要)
- 執行indexing程序,建立graph
python -m graphrag.index --root ./ragtestGraphRAG Local Ollama - Knowledge Graph
embedding模型設定
GRAPHRAG_API_KEY=-
清除.env檔的API_KEY設定(local server不需要)
- 執行indexing程序,建立graph
python -m graphrag.index --root ./ragtest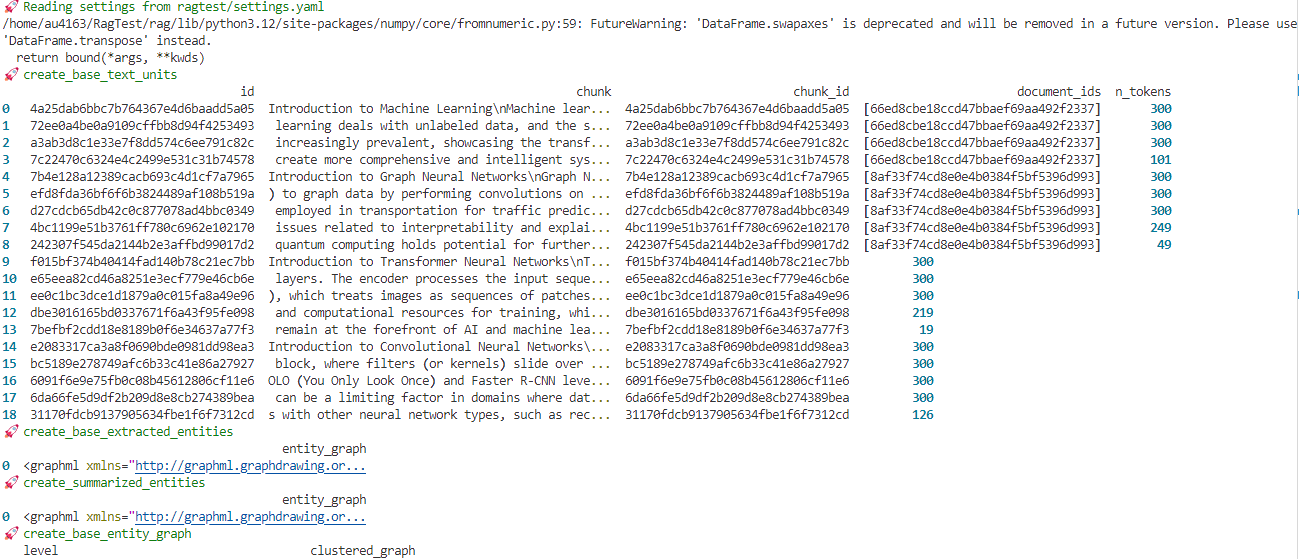
indexing process
indexing process

indexing process
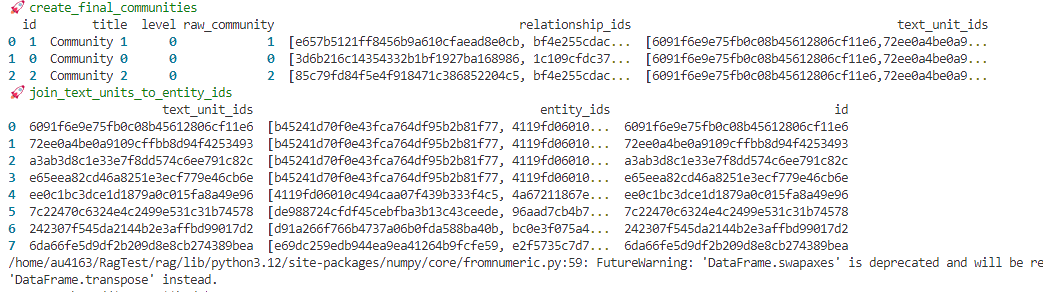
indexing process
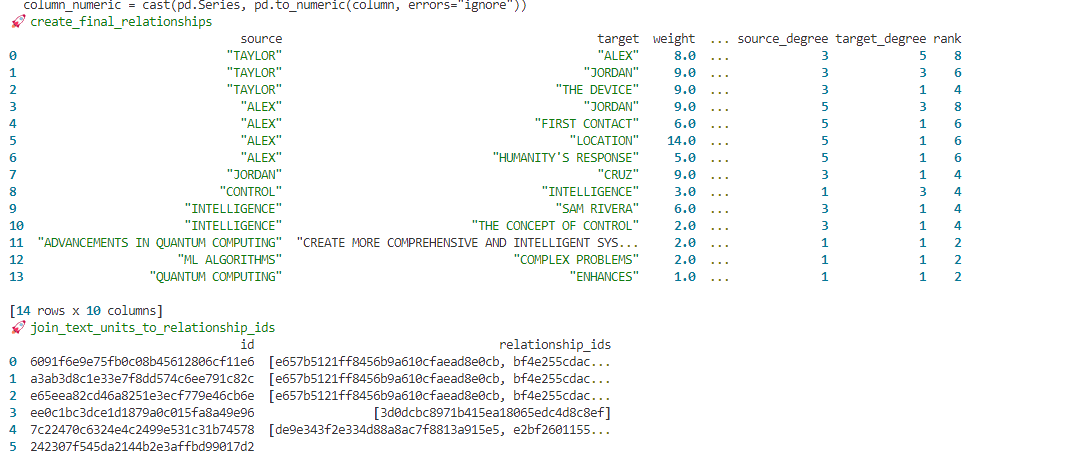
indexing process
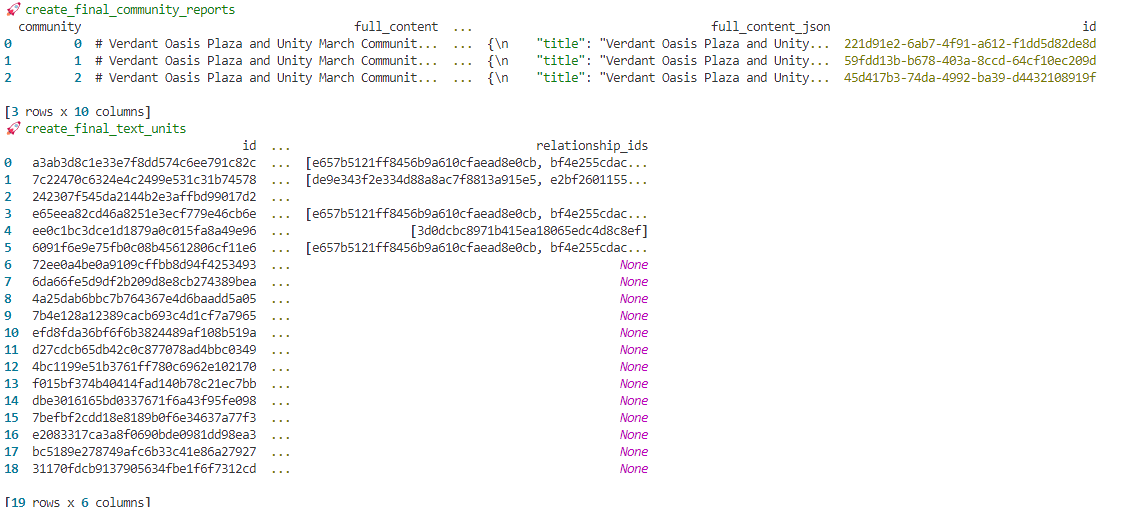
indexing process
Implementing GraphRAG
Vector store: Milvus
- Install graphrag and pymilvus
- Prepare dataset (e.g., Da Vinci text)
- Indexing + querying code pipelines available
Example: Leonardo Da Vinci
- GraphRAG builds KG from Gutenberg text
- Search powered by Milvus + GPT-4 Turbo
- Results: structured, contextual, citeable
Advanced Features
- Question generation from history
- Covariate mapping support
- Customizable vectorstore backends
Use Cases
- Enterprise QA systems
- Summarization & analysis tools
- Chatbots with historical memory
Resources
Summary
- GraphRAG = RAG + Knowledge Graphs
- Better for complex, contextual tasks
- Milvus is an ideal vector backend
Graph RAG
By Leuo-Hong Wang



