

Vidhi Lalchand
Postdoctoral Fellow, Broad and MIT
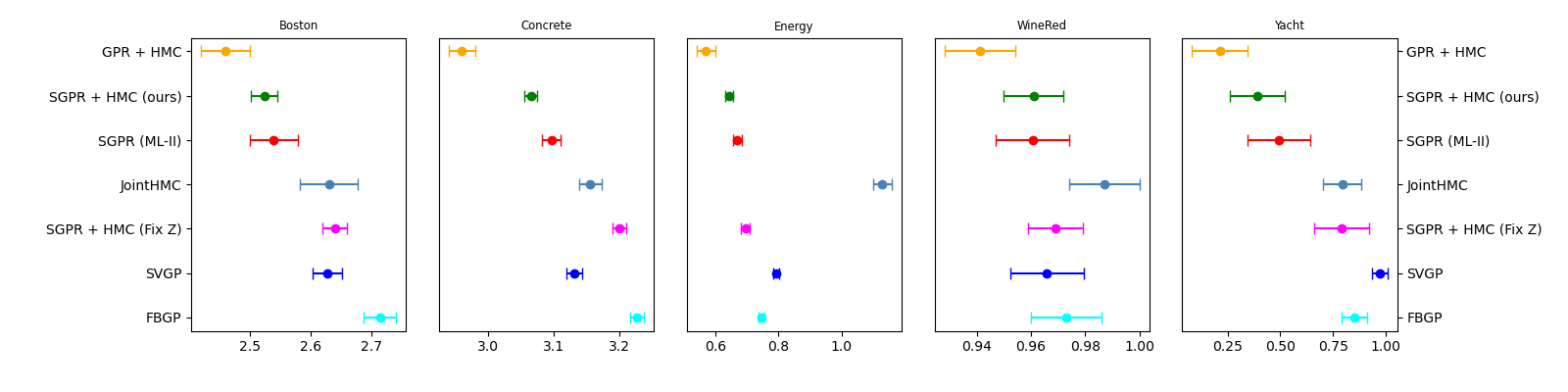
Sparse Gaussian Process Hyperparameters: Optimise or Integrate?
Vidhi Lalchand\(^{1}\), Wessel P. Bruinsma\(^{2}\), David R. Burt \(^{3}\), Carl E. Rasmussen\(^{1}\)
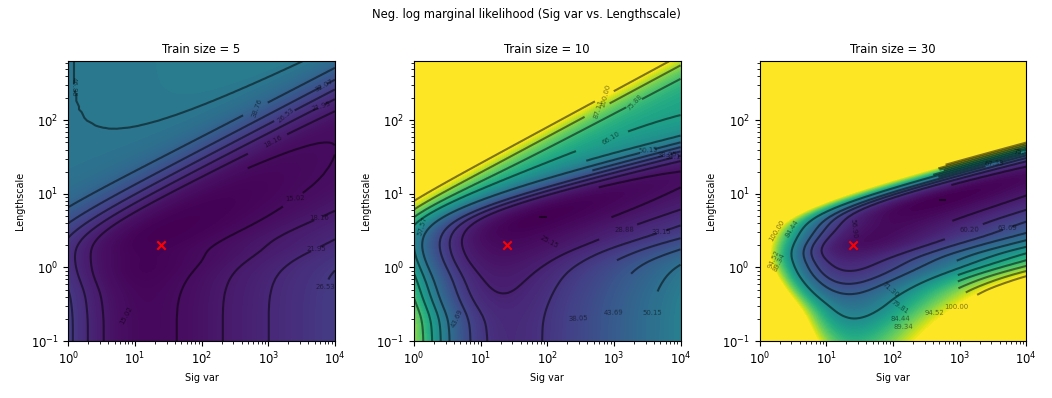
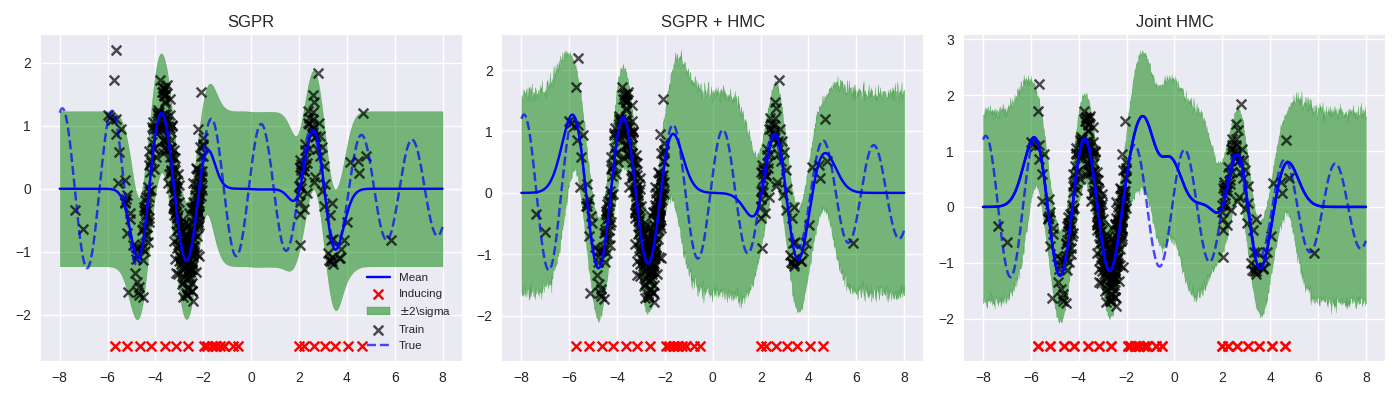
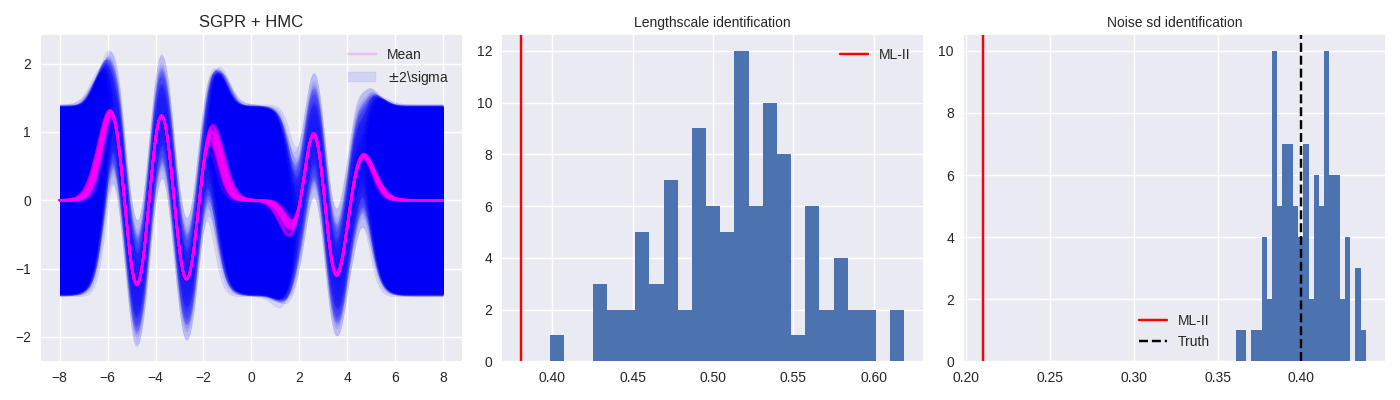
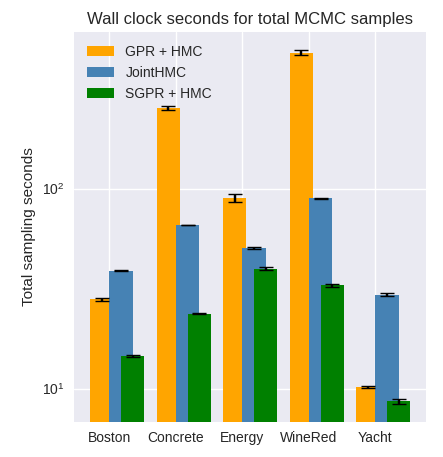
Motivation
University of Cambridge\(^{1}\), Microsoft Research A14 Science \(^{2}\), MIT LIDS \(^{3}\)
Inputs / Outputs
Latent function prior
Inducing locations
Inducing variables
Overall, the core training algorithm alternates between two steps:
By sampling from \( q^{*}(\bm{\theta})\), we side-step the need to sample from the joint \( (\bm{u},\bm{\theta})\)-space yielding a significantly more efficient algorithm in the case of regression with a Gaussian likelihood.
Hyperparameter inference:
Variational approximation:
Canonical Inference
"Doubly Collapsed" Inference
Variational approximation:
Gradients of the doubly collapsed ELBO
Mathematical set-up
/
By Vidhi Lalchand



