
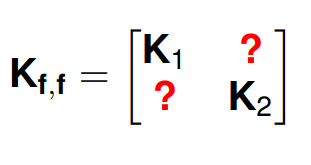


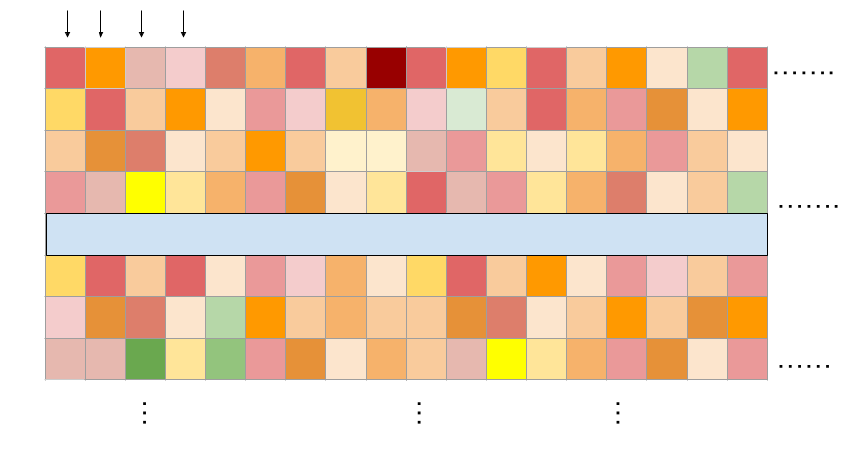
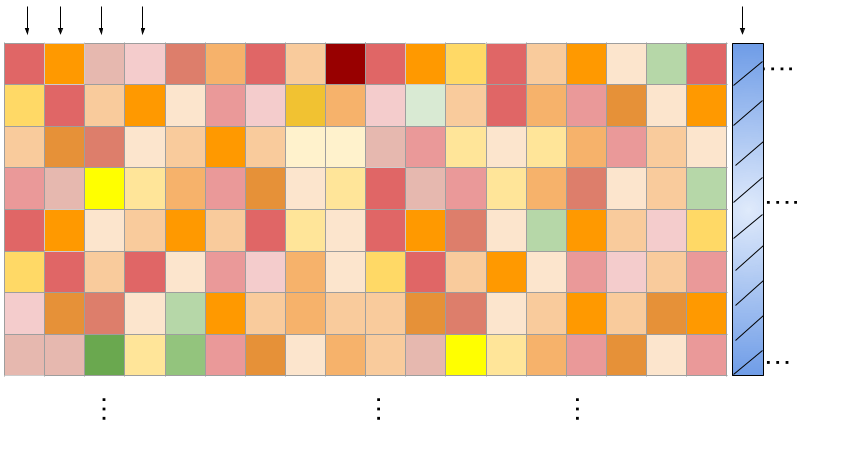



Vidhi Lalchand
Postdoctoral Fellow, Broad and MIT
Permutation Invariant Multi-Output Gaussian processes
Vidhi Lalchand
22nd November 2024
for Cancer Dose Response Surface Modelling
The multi-output setting
Predicting two or more output variables \(\mathbf{y} = [y_1, y_2, \dots, y_k]\) simultaneously from some high-dimensional input \(\mathbf{x}\).
These outputs are typically interdependent and correspond to the same overarching task. For instance, predicting multiple attributes of a car (e.g., make, model, and year) given an image of the car.
Formally, you can write down the model:
\(f(\mathbf{x}; \theta) = \hat{\mathbf{y}} = [\hat{y}_1, \hat{y}_2, \dots, \hat{y}_k]\)
Where:
- \(\mathbf{x}\) is the input.
- \(\theta\) are the parameters of the model.
- \(\hat{\mathbf{y}} = [\hat{y}_1, \hat{y}_2, \dots, \hat{y}_k]\) are the predicted outputs.
\(N\)
\(N\)
\(D\)
\(K\)
Outputs depend on the input and each other:
Joint data likelihood doesn't admit this factorisation:
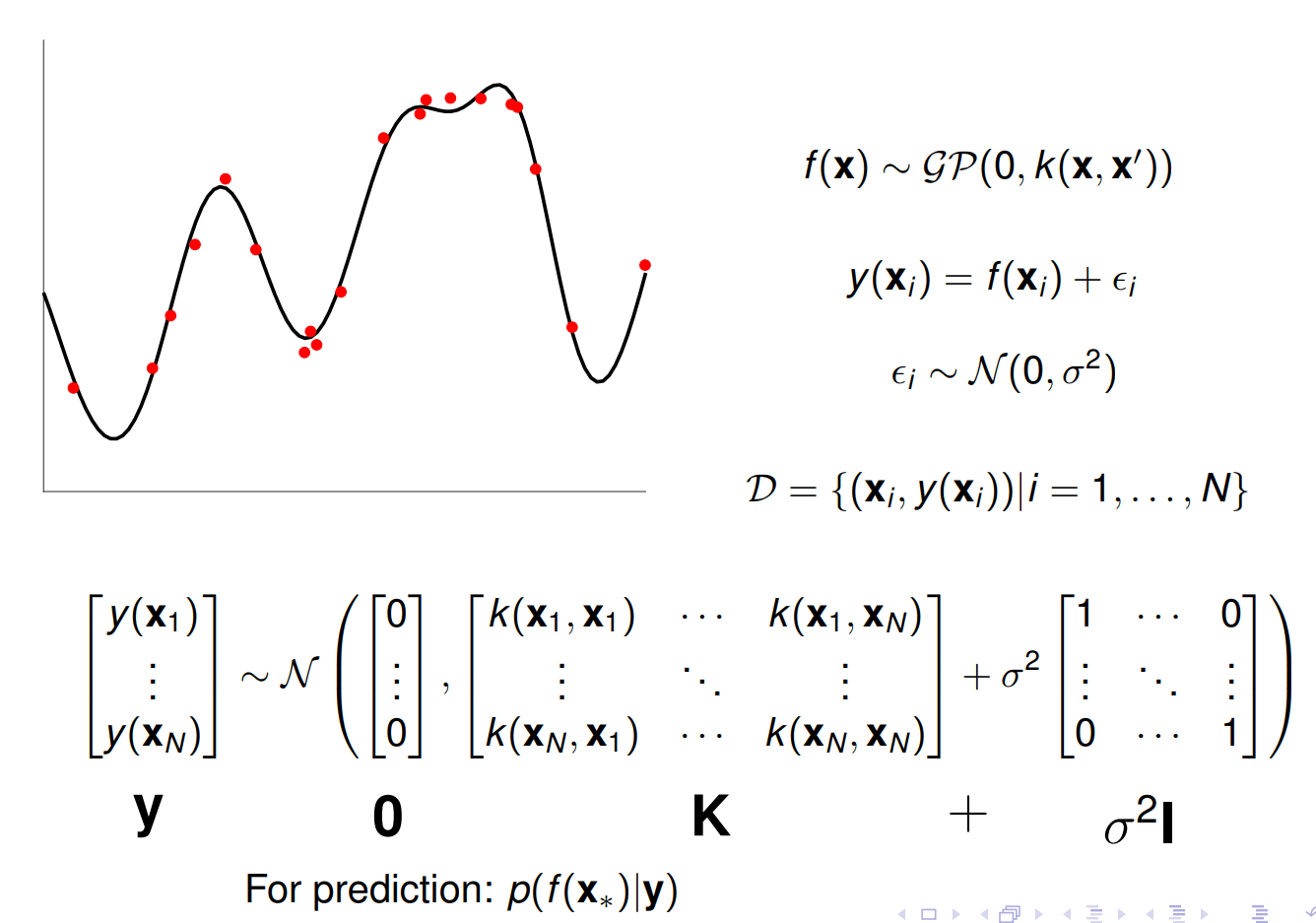
Single-output Gaussian processes
GPs are flexible prior over functions parameterised by a kernel function.
Single-output Gaussian processes \(\rightarrow\) Multi-output Gaussian processes
Main challenge:
Introduce dependencies between the outputs. Tantamount to learning the cross-covariance blocks.
Parametrising Multi-output Gaussian processes
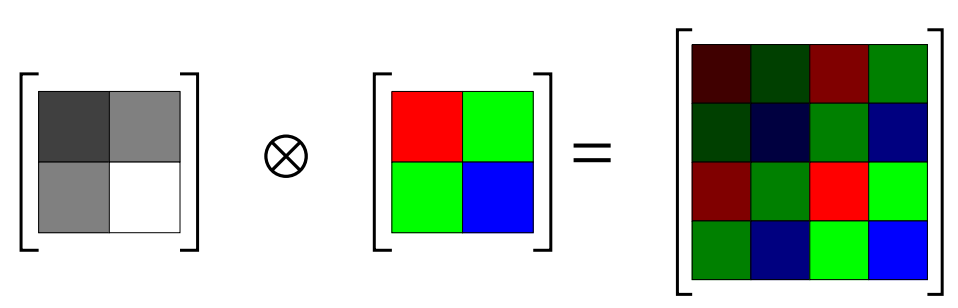
Intrinsic model of coregionalisation (IMC)
You can model the interaction between the outputs using a coregionalisation matrix \(\mathbf{B}\) and use a shared covariance \(\mathbf{K}\) that drives both outputs \(f_{1}(\mathbf{x})\) and \(f_{2}(\mathbf{x})\).
The interaction between the outputs is given by a positive semi-definite matrix \(\mathbf{B}\). In the two output case, it is give by,
(to ensure psd)
Another way to think about \( \mathbf{B}\) is as capturing inter-output covariance through an output based kernel function.
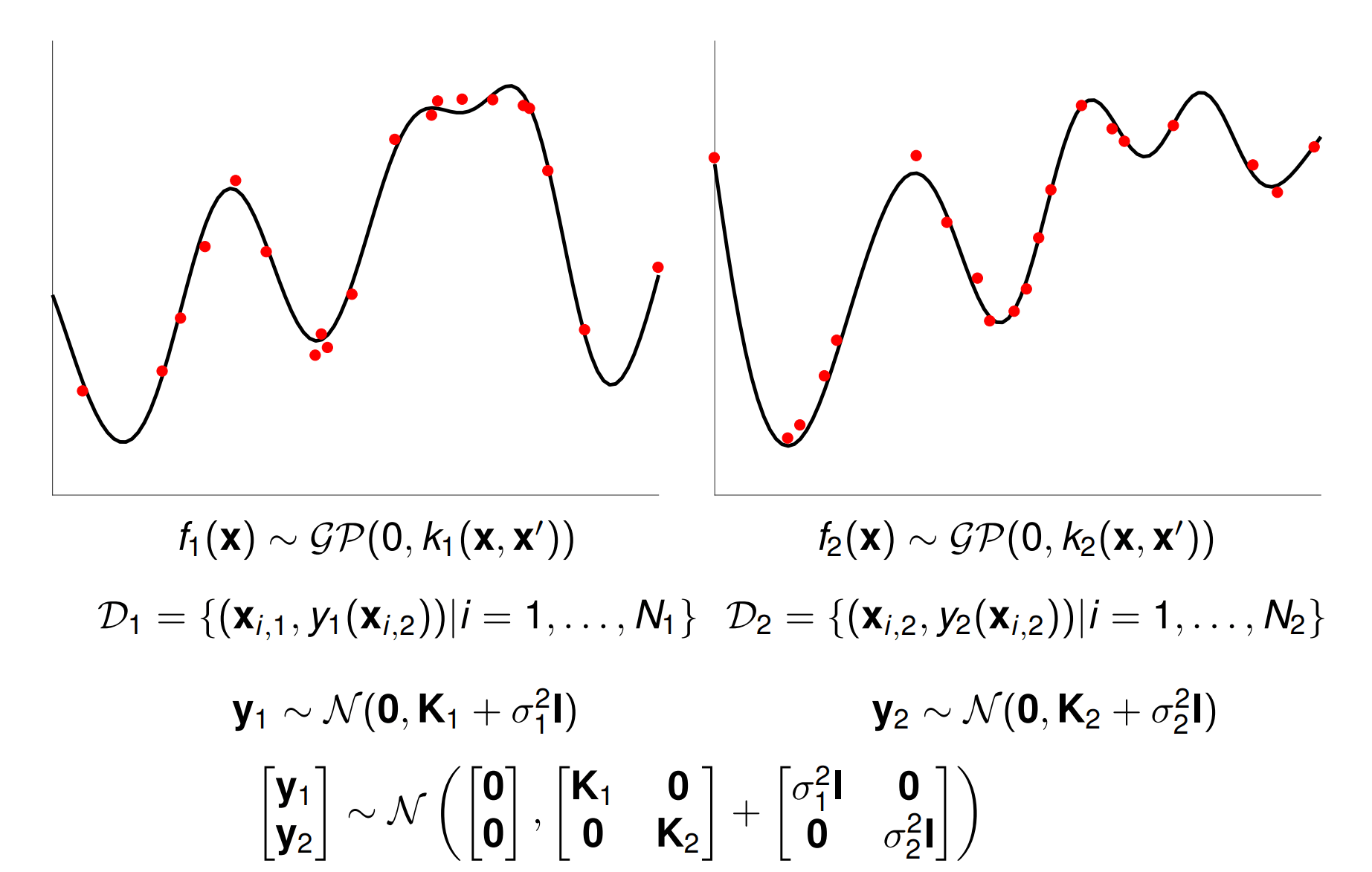
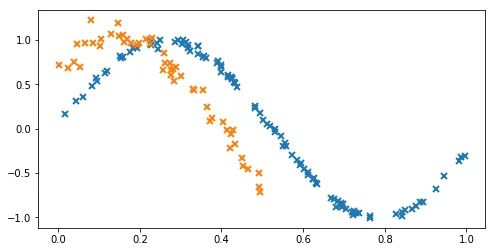
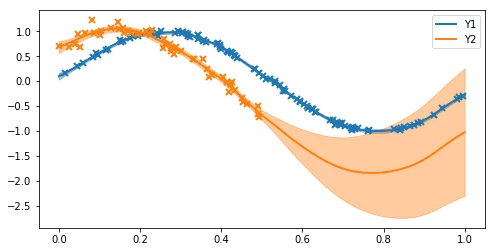
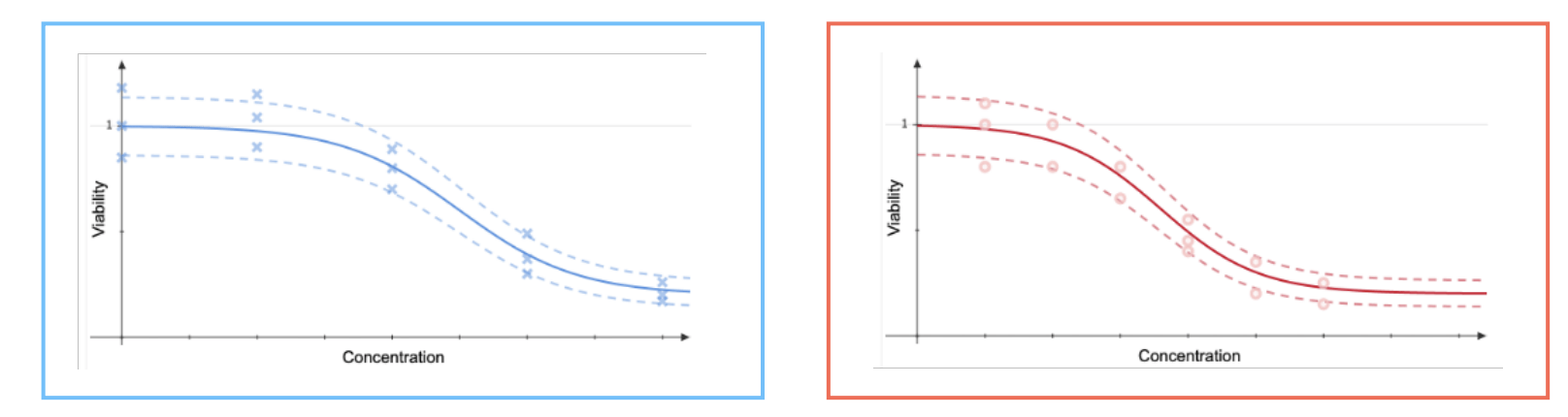
Intrinsic model of coregionalisation: Synthetic example
The model does a reasonable job of estimating the noise variance and the lengthscale. The posterior variance is higher on the second output where there is no training data.
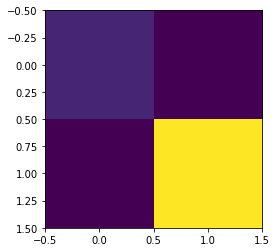
Diagonal Elements B[i,i]B[i, i]B[i,i]: Represent the variance of the iii-th output. Larger values indicate higher variability in that output.
Off-Diagonal Elements B[i,j]B[i, j]B[i,j]: Represent the covariance between the iii-th and jjj-th outputs. Positive values indicate that the outputs tend to increase or decrease together.
Parametrising Multi-output Gaussian processes
"Intrinsic" model of coregionalisation:
"Linear" model of coregionalisation:
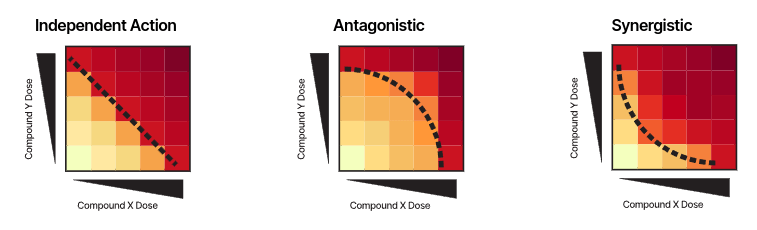
Drug-synergy modelling through dose-response surfaces
The nature of a drug combination, as synergistic, antagonistic or non-interacting, is usually studied by in-vitro dose–response experiments on cancer cell lines, through e.g. a cell viability assay.
https://theprismlab.org/white-papers/multiplexed-cancer-cell-line-combination-screening-using-prism
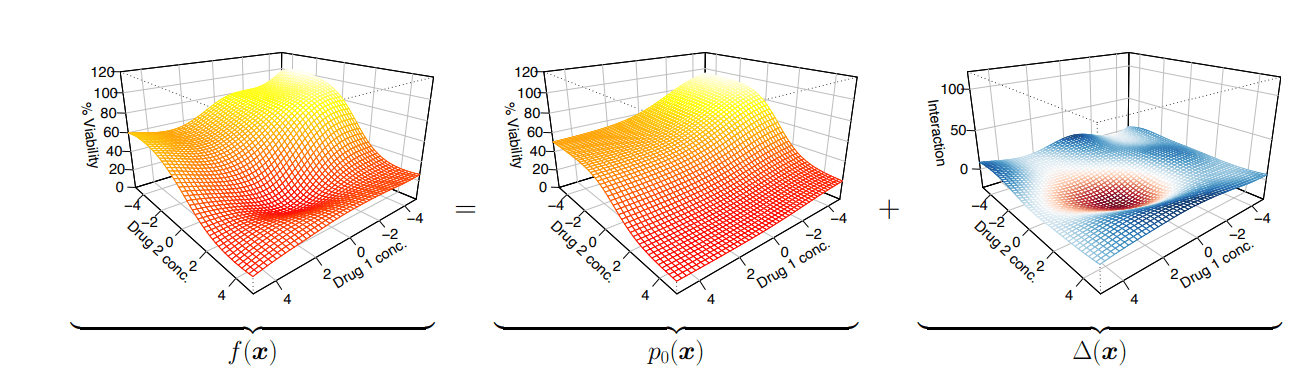
Drug-synergy modelling: Bliss model of independence
https://theprismlab.org/white-papers/multiplexed-cancer-cell-line-combination-screening-using-prism
The Bliss model assumes that the two drugs AAX and Y act independently to achieve their effects.
EAE_AEX: The probability of drug AAA killing a cell.
EBE_BEY: The probability of drug BBB killing a cell.
The probability of neither drug killing a cell is:
(1−EA)⋅(1−EB).(1 - E_A) \cdot (1 - E_B).(1−EX)⋅(1−EY)Therefore, the expected viability \(V_{XY}\) is,VABV_{ABVunder independence is:
\(V_{X} = 0.5\) and \(V_{Y} =0.6\)
\(V_{XY} = 0.3\)
Drug-synergy modelling through dose-response surfaces
Bliss independence
Multi-output Gaussian process
Understanding the training dataset
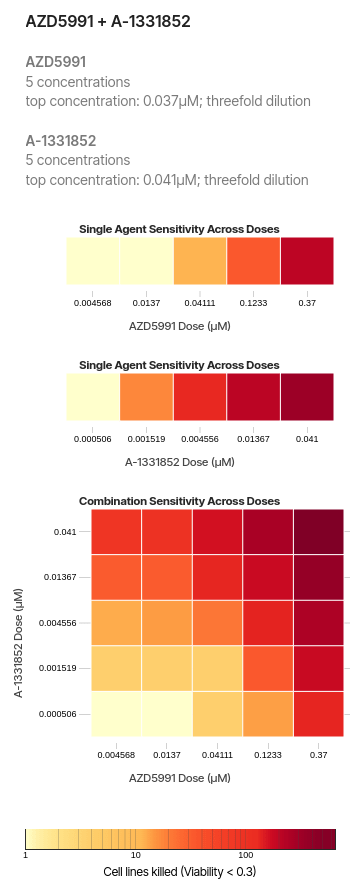
Built a model for the O'Neil (2016) dataset released by Merck Laboratories, Boston.
(c1, A, B)
(c2, A, B)
(c3, A, B)
(0, 0.11)
(0,0.22)
(0,0.33)
In this dataset, 38 drugs were combined in a pairwise manner into 583 distinct combinations that were screened on 39 cancer cell lines across 6 different tissues of origin (Lung, 8; Ovarian, 9; Melanoma, 6; Colon, 8; Breast, 6; Prostate, 2)
........
\(N_{d}\) = 583
\(N_{c}\) = 39
\(N_{}\) = 100
No. of drug concentrations
No. of cancer cell lines
No. of drug pairs.
(1,1)
Caveat:
-In reality, the experiments are performed on different grids of concentrations,
- we scale the concentration ranges of each experiment to the [0,1]×[0,1] unit box and constructed a common 10×10 grid of concentrations.
O'Neil et al. (2016). An An Unbiased Oncology Compound Screen to Identify Novel Combination Strategies. Mol Cancer Ther. 2016 Jun;15(6):1155-62
\(N_{}\)
\(N_{c} \times N_{d} = \) 22,737
Each output column (experiment) corresponds to some measurements on a dose-response surface of a triplet \((c, A,B)\)
Let \(\mathbf{x} = (x_{1}, x_{2})\) denote drug concentrations for an arbitrary pair of drugs, then the dose-response function:
(c1, A, B)
(c2, A, B)
(c3, A, B)
(0, 0.11)
(0,0.22)
(0,0.33)
........
(1,1)
\(N_{}\)
\(N_{c} \times N_{d} = \) 22,737
We are going to model each experiment/output with an underlying latent GP.
Let \( g_{i}\) model the output column \(i\) for some experiment given by a triplet \((c, A, B).\)
Model Design
(c1, A, B)
(c2, A, B)
(c3, A, B)
(0, 0.11)
(0,0.22)
(0,0.33)
........
(1,1)
\(N_{}\)
\(N_{c} \times N_{d} = \) 22,737
\(m\) denotes the number of outputs/experiments hence, \(m=22,737\) and \(N=100\) is the number of concentration pairs on the grid.
\( k_{g}\) captures covariance over outputs and \(k_{x}\) captures covariance over the inputs/drug concentrations
Covariance between any two latent function evaluations at any drug concentrations
is of dimension \(22,737 \times 22,737 \)
Kernel Design and Inference
We can impose further structure on the output covariance \(K_{\text{output}}\). If experiment \(i\) characterises a triplet \((c, A, B)\) and experiment \(j\) characterises a triplet \((c^{\prime}, A^{\prime}, B^{\prime})\), then one can break down the output covariance:
\(K_{c}\) is of dimension \( N_{c} \times N_{c}\)
\(K_{d}\) is of dimension \( N_{d} \times N_{d}\)
\(K_{x}\) is of dimension \( N \times N\)
Cell line covariance: \(K_{c} = L_{c}L_{c}^{T} + \text{diag}(\mathbf{v}_{c})\) (free-form low-rank)
Drug pair covariance: \(K_{d} = L_{d}L_{d}^{T} + \text{diag}(\mathbf{v}_{d})\) (free-form low-rank)
Drug concentration (input) covariance: \( k(\mathbf{x}, \mathbf{x}') = \sigma_f^2 \exp\left(-\frac{\|\mathbf{x} - \mathbf{x}'\|^2}{2\ell^2}\right) \)
Kernel Design and Inference
We leverage identities for inverse and determinants of Kronecker products of invertible square matrices.
Multi-output GP prior
Training objective:
Same structure as the single-output GP:
Dose-response functions need to exhibit built-in invariance
Let \(f(c, A, B, x_{A}, x_{B})\) denote the dose-response function for drug combination \((A,B)\) and cell-line \( c\), then,
is invariant by default.
We want that
because
leaves the function unchanged
Dose-response functions need to exhibit built-in invariance
We want that
because
leaves the function unchanged
Final permutation invariant kernel:
Prediction framework: what can we do with this model?
(c1, A, B)
(c2, A, B)
(c3, A, B)
(0, 0.11)
(0,0.22)
........
\(N_{c} \times N_{d} = \) 22,737
(x1*,x2*)
Predicting the outcome of all experiments at a new arbitrary concentration pair \((x_{1}^{*}, x_{2}^{*}) \)
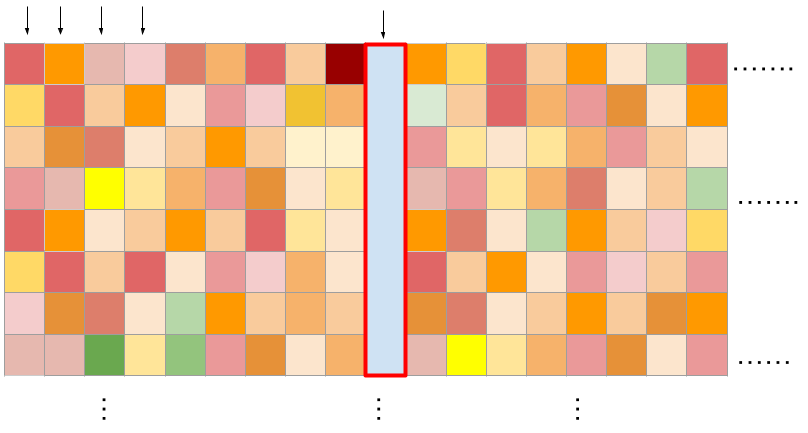
Predict across cell lines at a new concentration
Predicting a new output column at any unique triplet \( (c^{'},A^{'},B^{\prime})\) (a whole surface, across all concentrations).
(c1, A, B)
(c2, A, B)
(c', A, B)
(c18, A', B')
(0, 0.11)
(0,0.22)
........
(1,1)
(c', A', B')
Results
| RMSE | Pearsons's r | |
|---|---|---|
| PIICM (full) | 0.06802 (0.07741) | 0.9882 (0.9263) |
| PIICM (no invariance) | 0.07182 (0.07741) | 0.9368 (0.9263) |
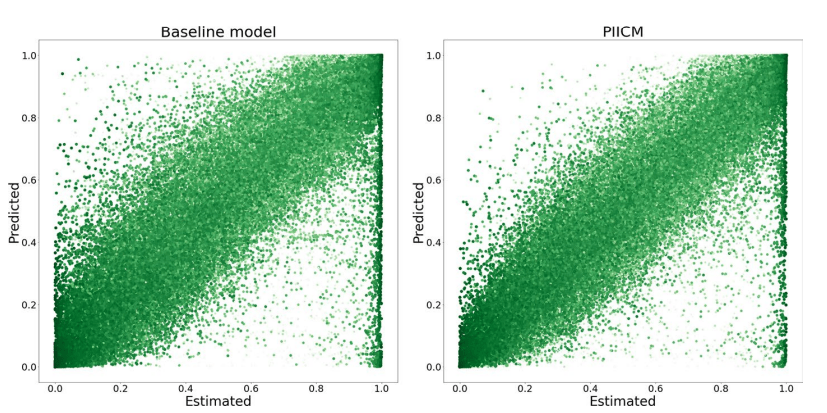
Pointwise actual vs. predicted viabilities on unseen experiments.
i.e. where the triplet (c,A,B) was not a part of the training data.
Actual
Actual
() shows baseline Bliss model
Results
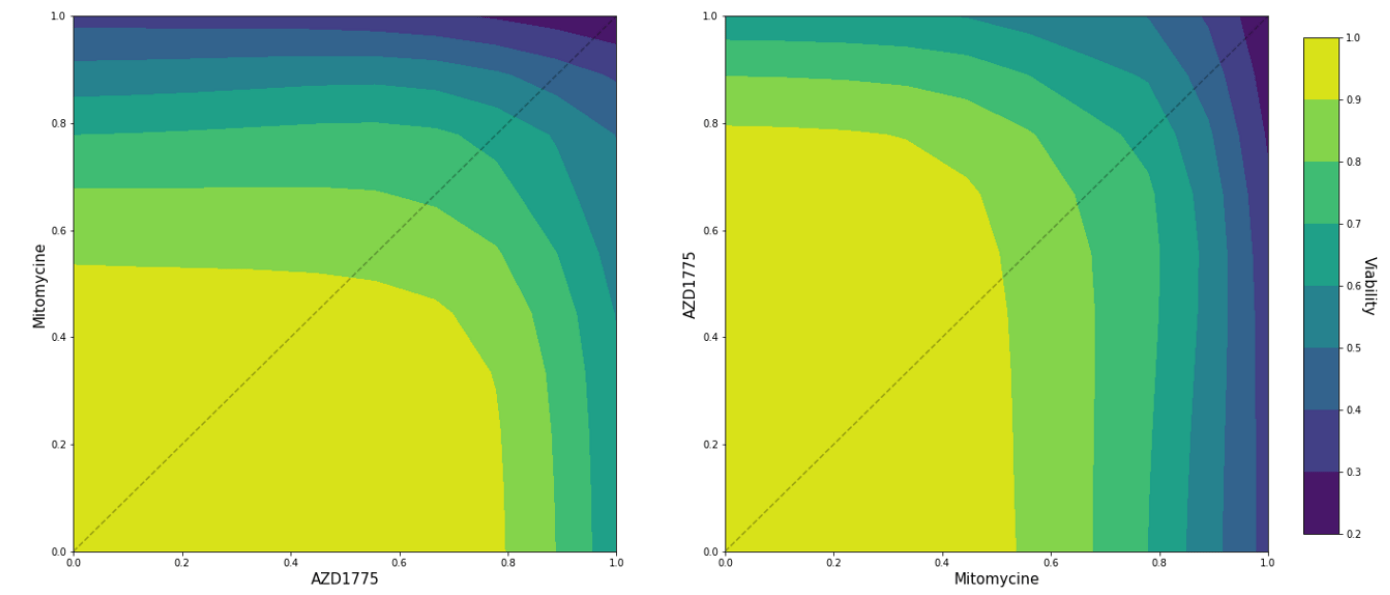
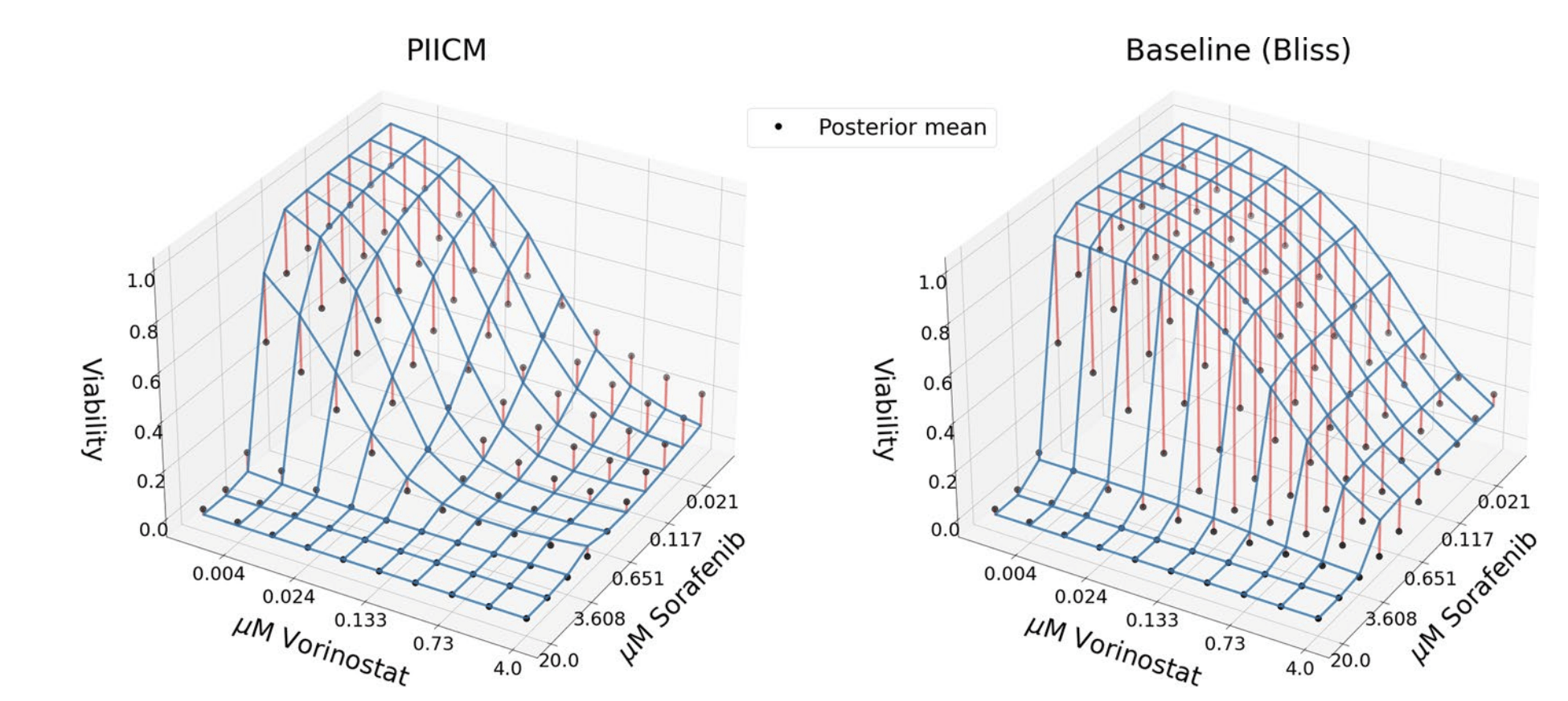
PIICM identifies drug pairs with synergestic interaction for the lung cancer cell line.
Actual viability
Predicted dose-response surface
Deviation from actual viability
RMSE
Baseline: 0.3227
PIICM: 0.1182
Future work
Currently, we cannot predict a dose-response surface for a completely unseen cell line or an unseen drug pair \( (c^{*}, A^{*}, B^{*})\) i.e. if neither \( c^{*}\) or \((A^{*}, B^{*})\) appear anywhere in the experiments.
(c1, A, B)
(c2, A, B)
(c3, A, B)
(c*, A*, B*)
Soln: Encode cell-lines with a cell embedding and encode drug pairs with a tuplet of drug embeddings.
Compute the cell kernel and drug kernel as \(k_{c}(\phi(c), \phi(c^{\prime}))\) and \( k_{d}([\zeta(A), \zeta(B)], [\zeta(A^{\prime}), \zeta(B^{\prime})])\).
Joint work with,
Leiv Ronninberg
Paul Kirk
A new version of this work titled "Scalable Permutation Invariant Multi-Output Gaussian Processes for Cancer Drug Response"
By Vidhi Lalchand



