



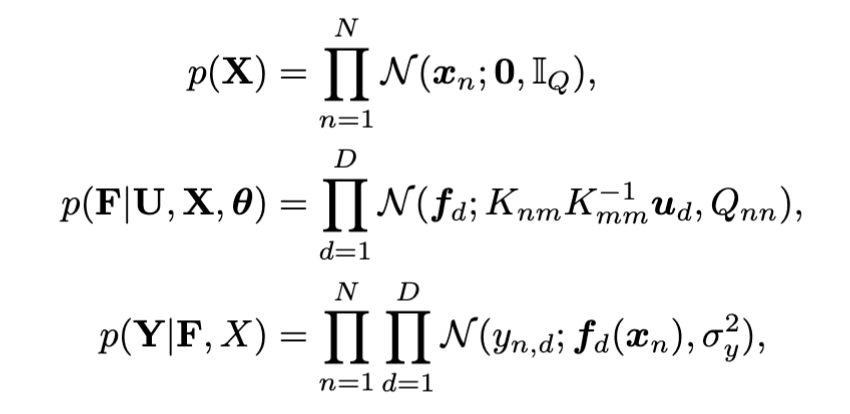




Vidhi Lalchand
Postdoctoral Fellow, Broad and MIT
Vidhi Lalchand, Aditya Ravuri, Neil D. Lawrence
Bayesian GPLVM
Given: High dimensional training data \( Y \equiv \{\bm{y}_{n}\}_{n=1}^{N}, Y \in \mathbb{R}^{N \times D}\)
Learn: Low dimensional latent space \( X \equiv \{\bm{x}_{n}\}_{n=1}^{N}, X \in \mathbb{R}^{N \times Q}\)
Titsias & Lawrence (2010), Lawrence (2005)
Primer:
N x D
D - independent Gaussian processes
low dimensional latent space
High-dimensional data space
Primer: Bayesian GPLVM
where,
Generative Model
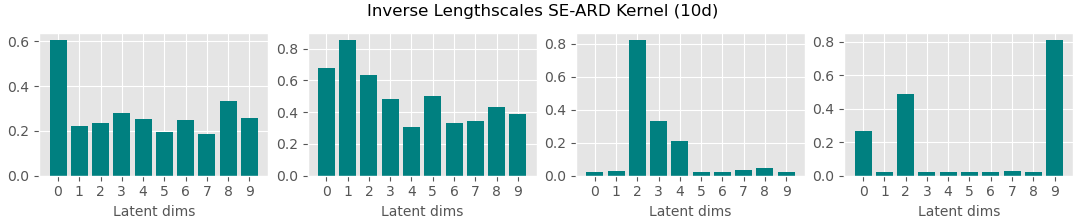
Scalable Bayesian GPLVM
Stochastic variational inference for GP regression was introduced in Hensman et al (2013). In this work we use the SVI bound in the latent variable setting with unknown \(X\) and multi-output \(Y\).
ELBO:
Final factorised form:
Non-Gaussian likelihoods Flexible variational families Amortised Inference Interdomain inducing variables Missing data problems
Non-Gaussian likelihoods Flexible variational families Amortised Inference Interdomain inducing variables Missing data problems
Algorithm
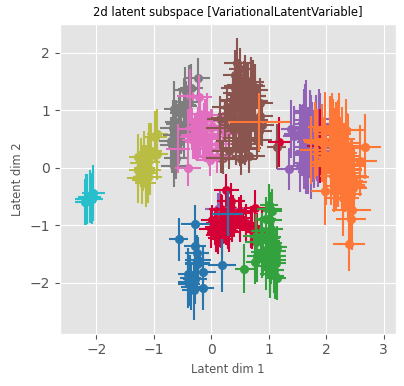
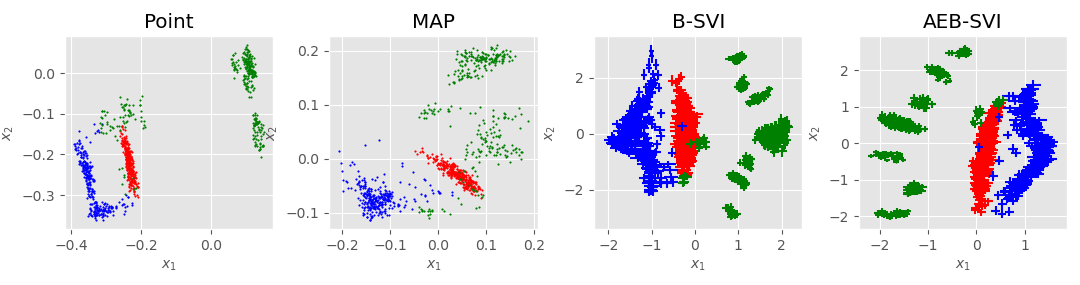
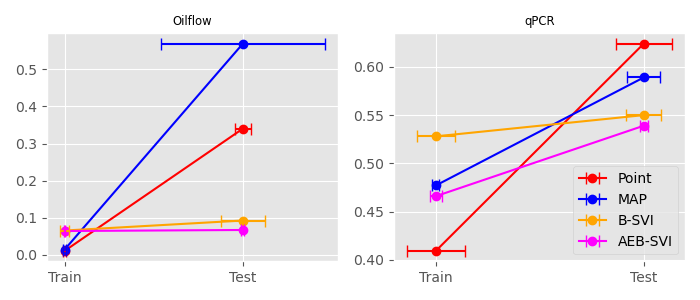
Oilflow (12d)
| Point | MAP | Bayesian-SVI | AEB-SVI | |
|---|---|---|---|---|
| RMSE | 0.341 (0.008) | 0.569 (0.092) | 0.0925 (0.025) | 0.067 (0.0016) |
| NLPD | 4.104 (3.223) | 8.16 (1.224) | -11.3105 (0.243) | -11.392 (0.147) |
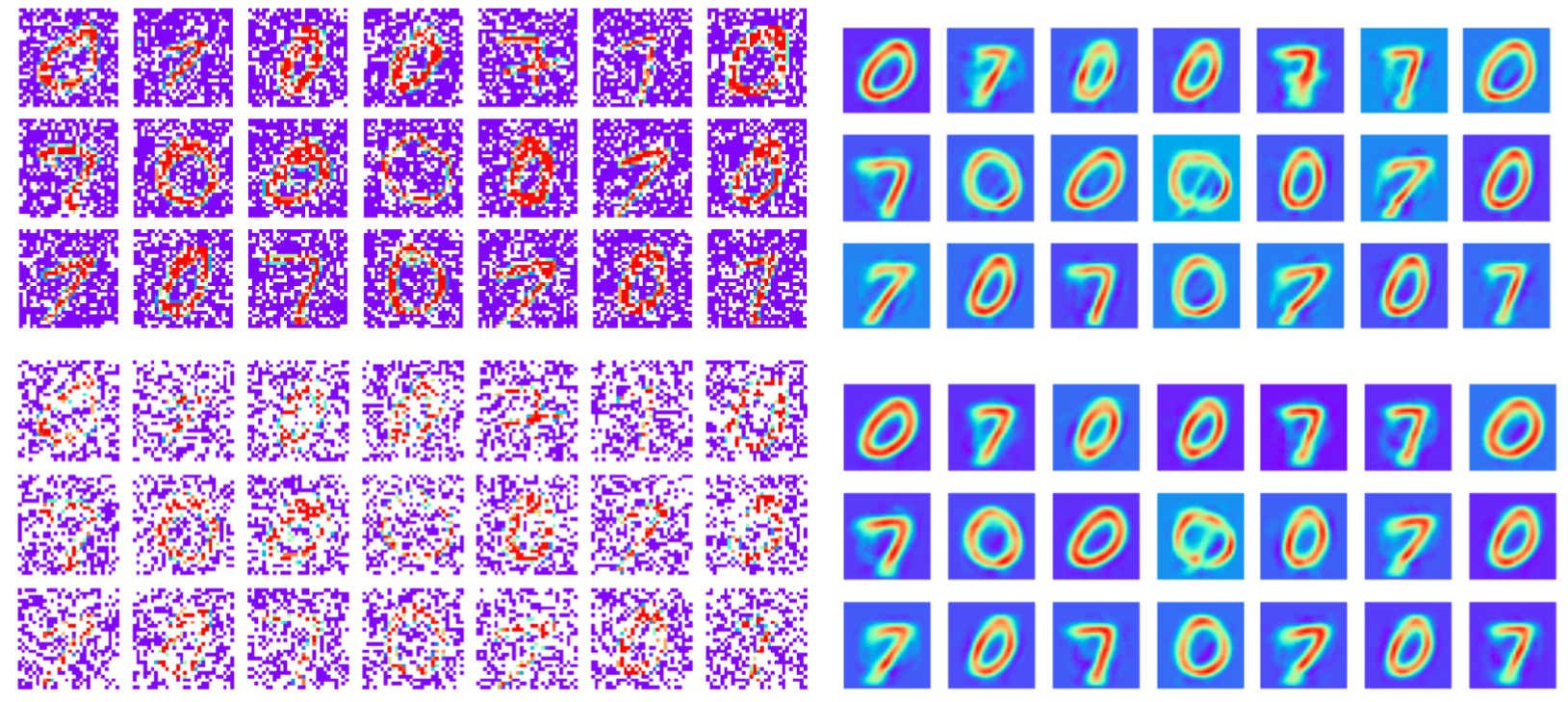
Robust to Missing Data: MNIST Reconstruction
30%
60%
Robust to Missing Data: Motion Capture
Summary
Thank you!
By Vidhi Lalchand



