



Vidhi Lalchand
Postdoctoral Fellow, Broad and MIT
Recurrent VAE with Gaussian Process Decoders for De Novo Molecular Generation
Vidhi Lalchand\(^{1}\), Dave Lines\(^{2}\), Anna Perdrix Rosell\(^{2}\), Neil D. Lawrence\(^{3}\)
Motivation
Eric and Wendy Schmidt Center, Broad Institute of MIT and Harvard\(^{1}\),Sixfold Bioscience\(^{2}\), University of Cambridge\(^{3}\)
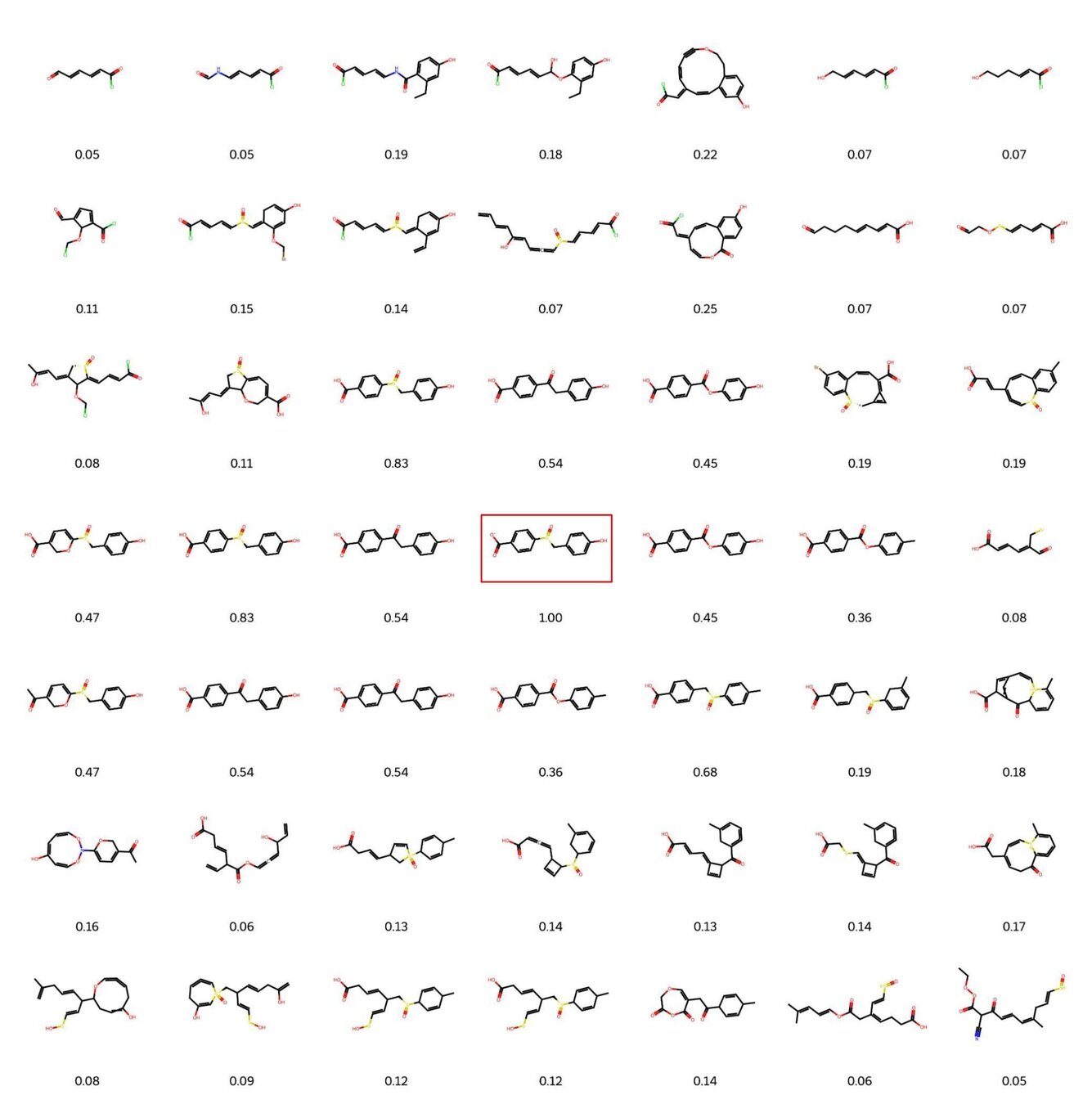
Visualisation of decoded molecules reconstructed from a small neighbourhood around a fixed molecule. The immediate neighbourhood of a known molecule (highlighted in red) yields molecules which share structural similarity – this similarity weakens with increasing Euclidean distance. This underscores the utility of a smooth latent space.
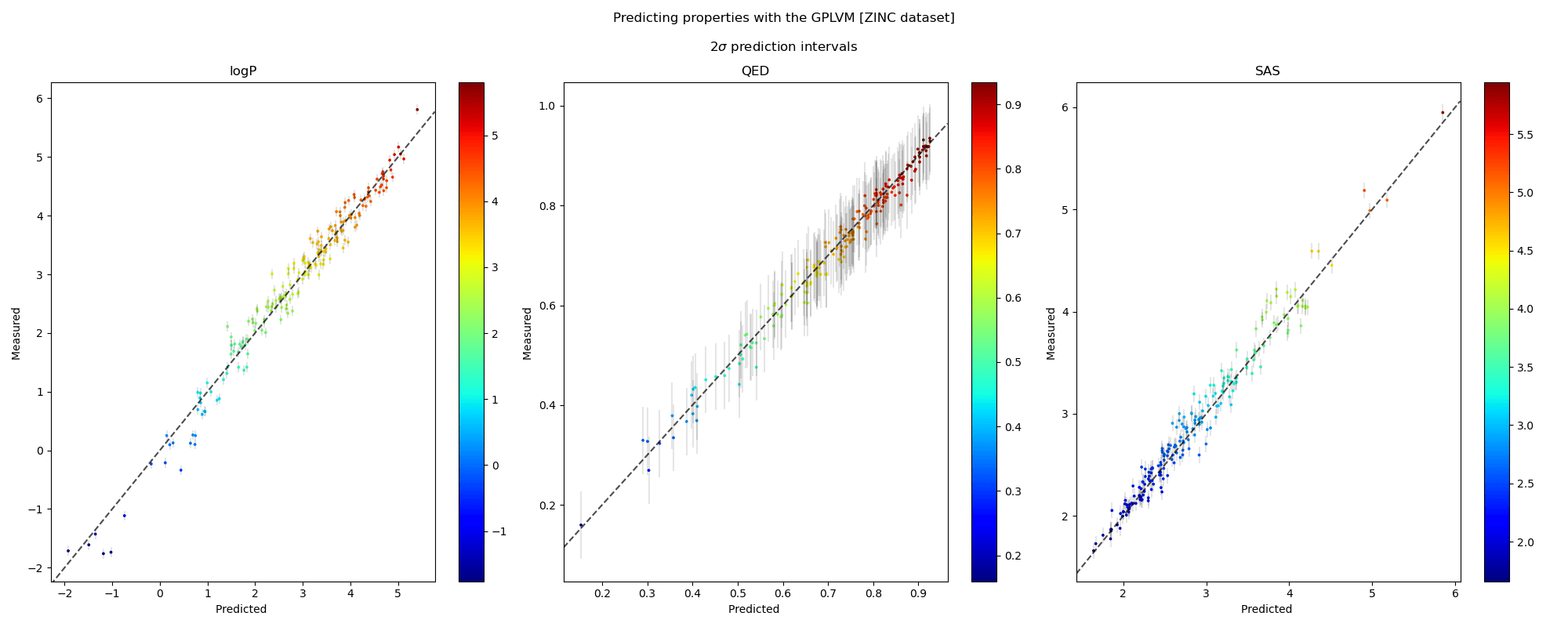
We visualise the predicted and measured property values for each property individually in the plots along a 45° line. The points in the scatter are shaded by the ground truth value of the properties. The grey bars denote 95% confidence intervals approximately corresponding to a \(2\sigma\) interval around the mean prediction. We also note the robustness of the prediction intervals as inaccurate predictions are accompanied by wider error bars.
Model Architecture [V-RNN]
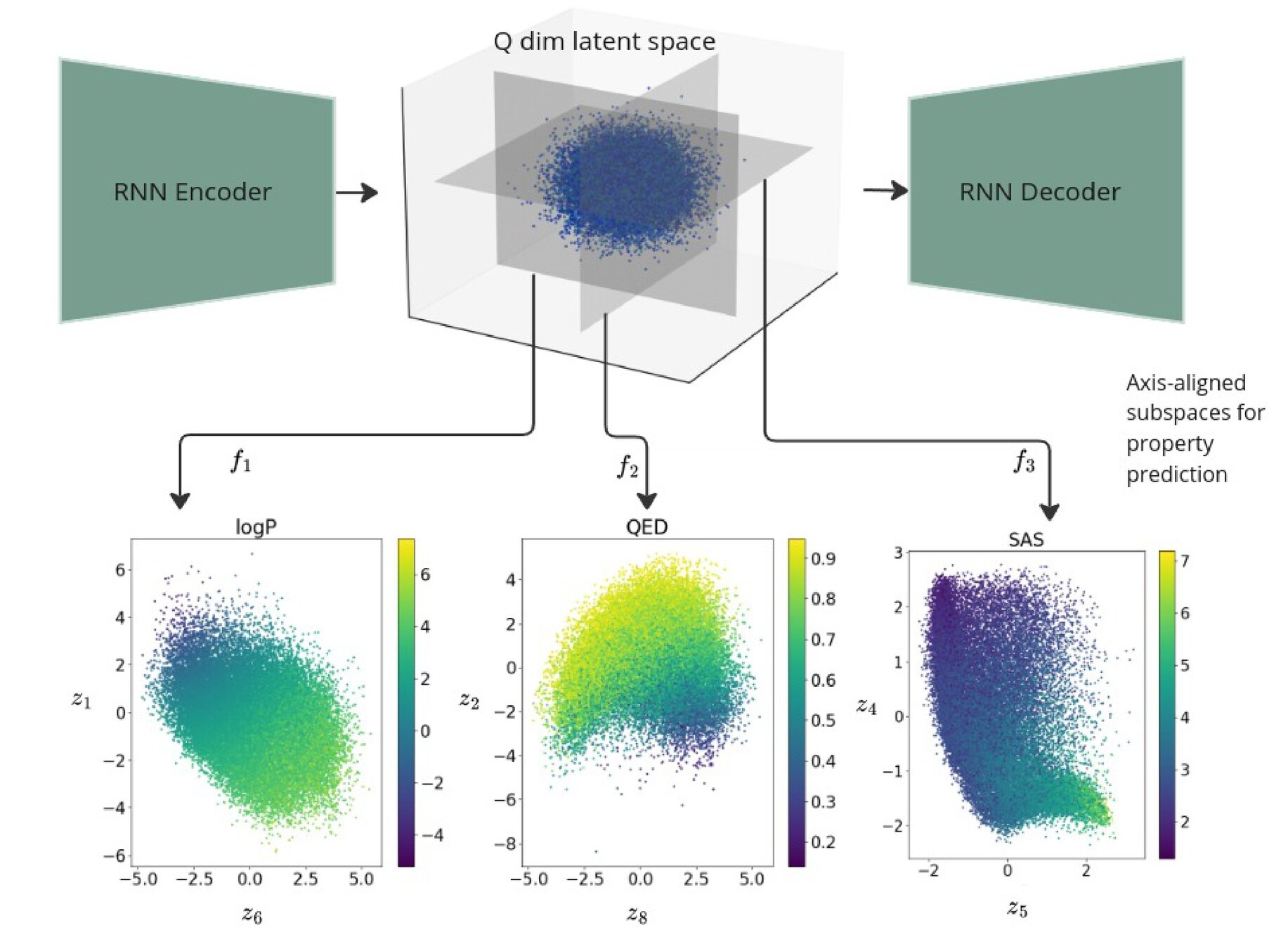
Regularised 2d subspaces per property prediction task. The latent points in each plot are shaded by the ground truth value of the property being modelled by the GP.
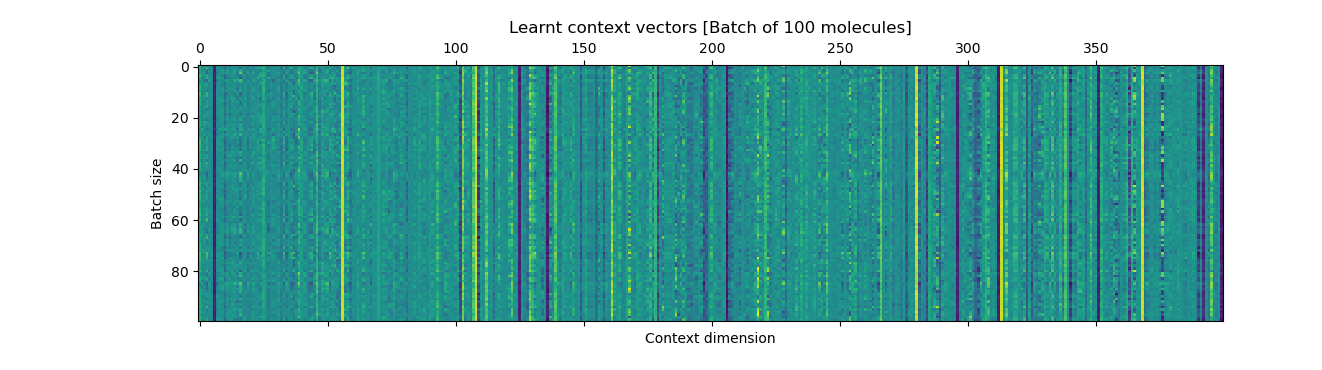
The plots show the ground-truth (right) context vector per data point (row) and the learnt context vector (left) which is learnt during training using an auxilliary fully connected layer which inputs the mean of the latents.
Gaussian Process Decoders for property prediction
1) We learn independent GPs which map from latent space to the property target vector.
3) The GPs are trained jointly with the recurrent VAE to yield smooth subspaces (as a function of target properties) which can be used for gradient based optimisation.
Recurrent VAE with learnt context
2) We use independent SE-ARD kernels inducing automatic pruning of dimensions in latent space.
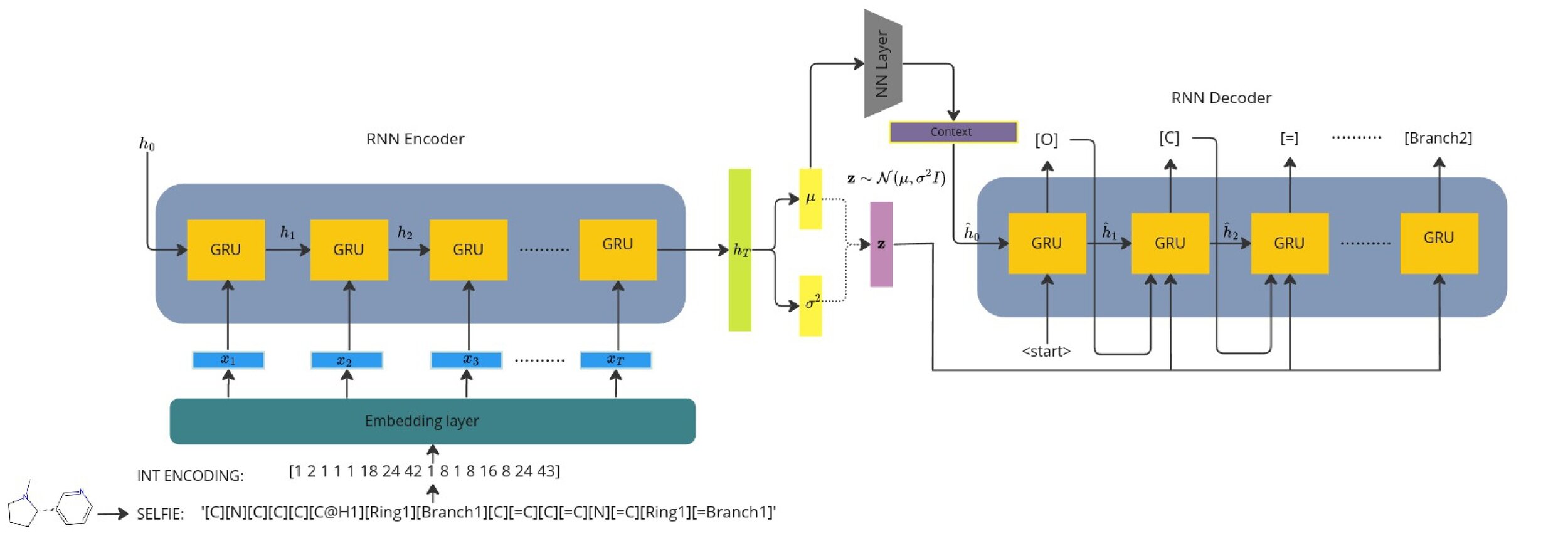
1) Seq2Seq models typically need a context vector which encodes the context of the whole sequence.
2) This is usually the terminal hidden state of the encoder but we wish to sample and optimise from the continuous latent space.
3) We learn a context vector during training which minimises the error between the terminal encoder hidden state.
| Datasets | Structure accuracy [VRNN] | Structure accuracy w. property prediction [VRNN + GPs] |
|---|---|---|
| QM9 | 96.7 (0.11) | 94.2 (0.26) |
| ZINC [250K] | 93.8 (0.41) | 91.7 (0.55) |
Model & Goals
Recurrent VAE + Learnt Context + Gaussian process decoders
Learn a continuous latent manifold encoding small molecules which admits the ability to sample (novel molecules) and optimise using gradient based techniques.
Encode similarities in latent space, for instance, molecules with similar properties to cluster closely in latent space.
Overall loss =
By Vidhi Lalchand



