
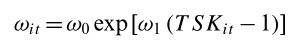







Carina Ines Hausladen PRO
I am a Senior Scientist at ETH Zurich working in the fields of Computational Social Science and Behavioral Economics.
Identifying Latent Intentions
via
Inverse Reinforcement Learning
in
Repeated Public Good Games
Carina I Hausladen, Marcel H Schubert, Christoph Engel
MAX PLANCK INSTITUTE
FOR RESEARCH ON COLLECTIVE GOODS
Initial contributions start positive but gradually decline over time.
Meta-Analysis
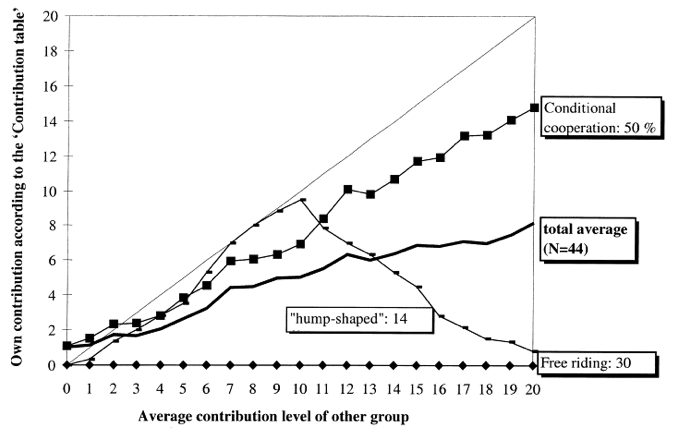
Thöni et al. (2018)
61.3%
19.2%
10.4%
Meta-Analysis
Thöni et al. (2018)
Conditional Cooperation
19.2 %
Hump-Shaped
Fischbacher et al. (2001)
61.3 %
Freeriding
10.4 %
Meta-Analysis
Thöni et al. (2018)
Conditional Cooperation
19.2 %
Hump-Shaped
Fischbacher et al. (2001)
61.3 %
Freeriding
10.4 %
Strategy Method Data
Game Play Data
Theory Driven
Data Driven
Theory Driven
Data Driven
Bardsely (2006)
Houser (2004)
Fallucchi (2021)
Fallucchi (2019)
Theory Driven
Data Driven
Theory Driven
Data Driven
Theory first: Use theory to find groups
Model first:
Specify a model, then find groups
Data first: Let the data decide groups, then theorize
Theory Driven
Data Driven
Bardsely (2006)| Tremble terms: 18.5%.
Houser (2004) | Confused: 24%
Fallucchi (2021) |Others: 22% – 32%
Fallucchi (2019) |Various: 16.5%
initial tremble
simulated
actual
Others
18.5%
24%
32%
16.5%
random / unexplained
Step 1
Clustering
→ uncover patterns
Step 2
Inverse Reinforcement Learning
→ interpret patterns
Can we build a model that explains both
the behavior types we know and the ones we don’t?
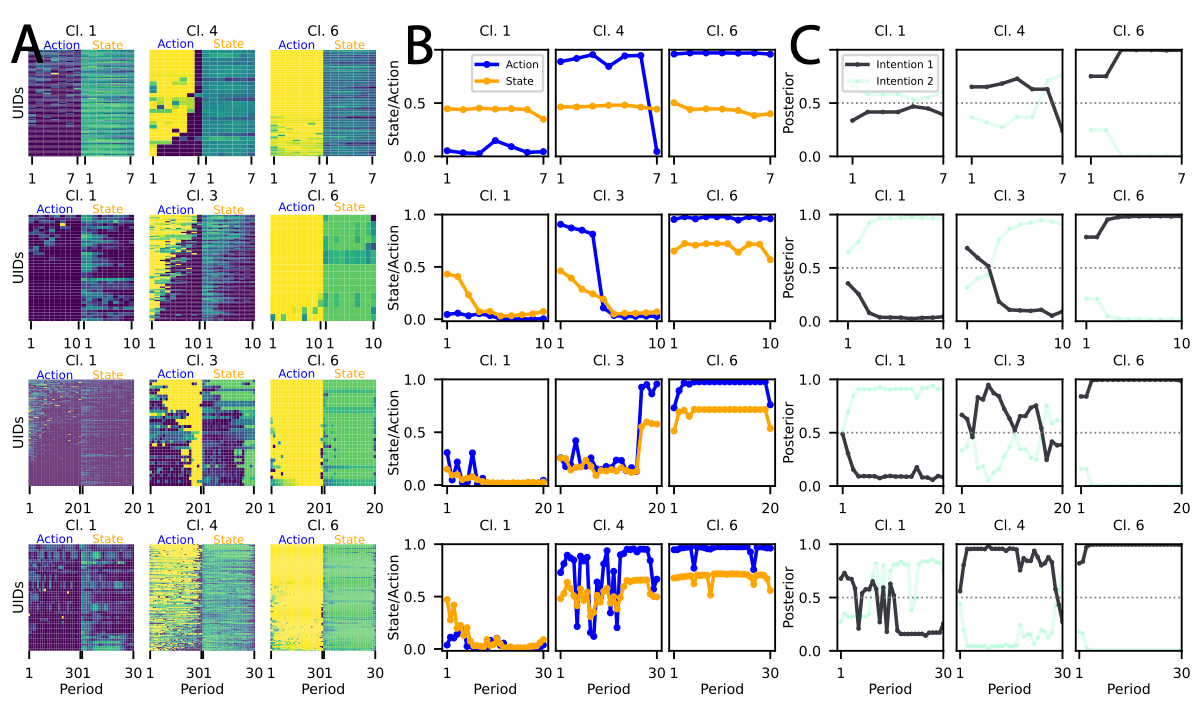
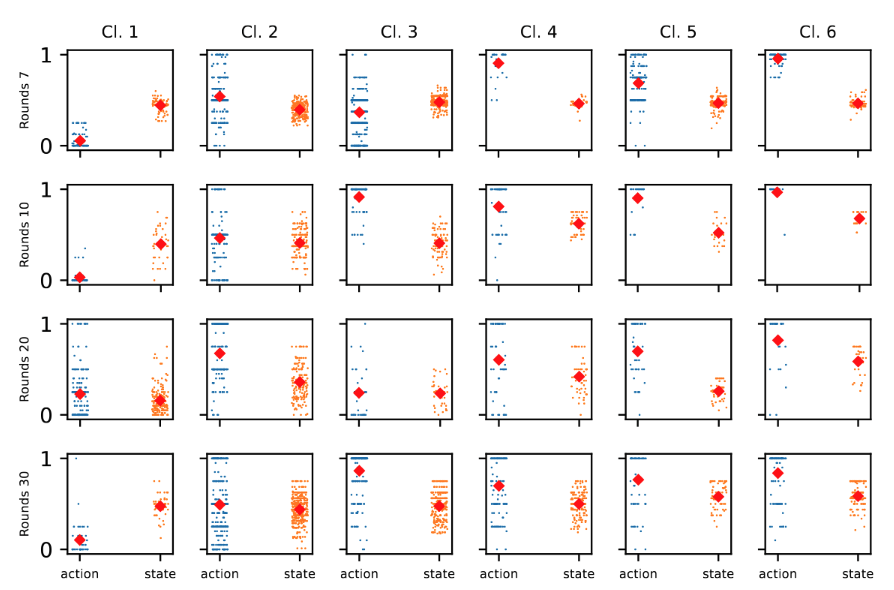
two-dimensional time series
per player
rounds
highest mean contribution
lowest mean contribution
Step 1
Clustering
→ uncover patterns
Step 2
Inverse Reinforcement Learning
→ interpret patterns
Data Driven
Our approach:
Unsupervised modeling to uncover structure
Then apply theory to interpret the clusters.
Bottom line:
Clustering is not a substitute for theory — it is a way to structure behavioral complexity before theorizing.
Minimum Wages and Employment
Cart & Krueger (2000)
rounds
20
contribution
1
0
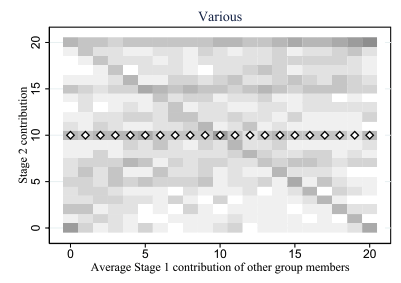
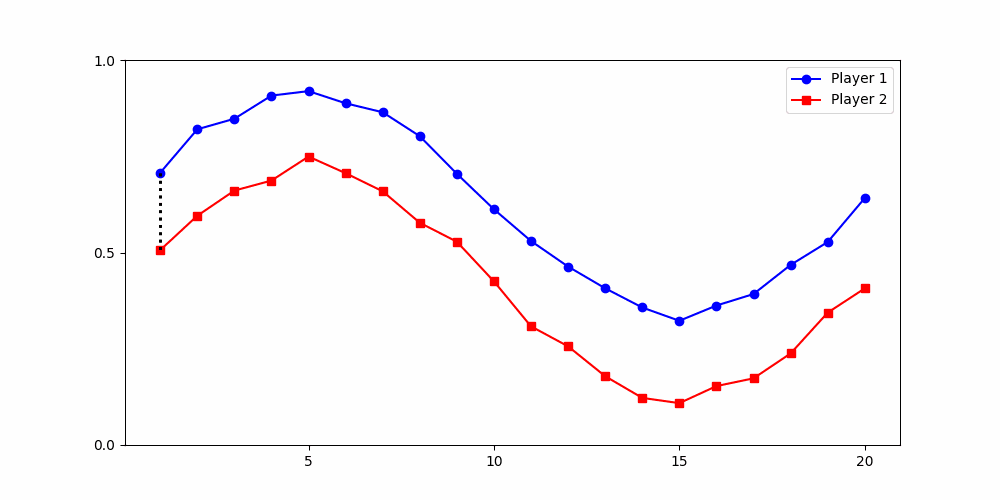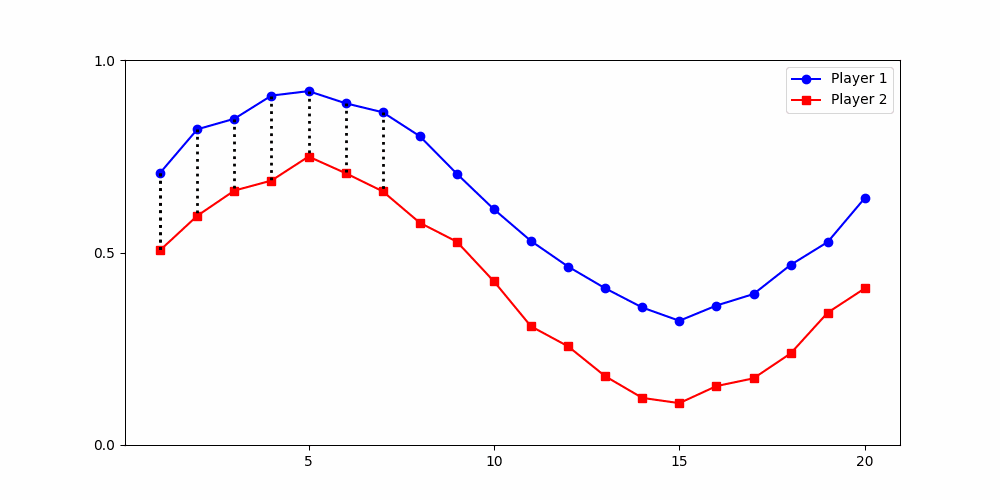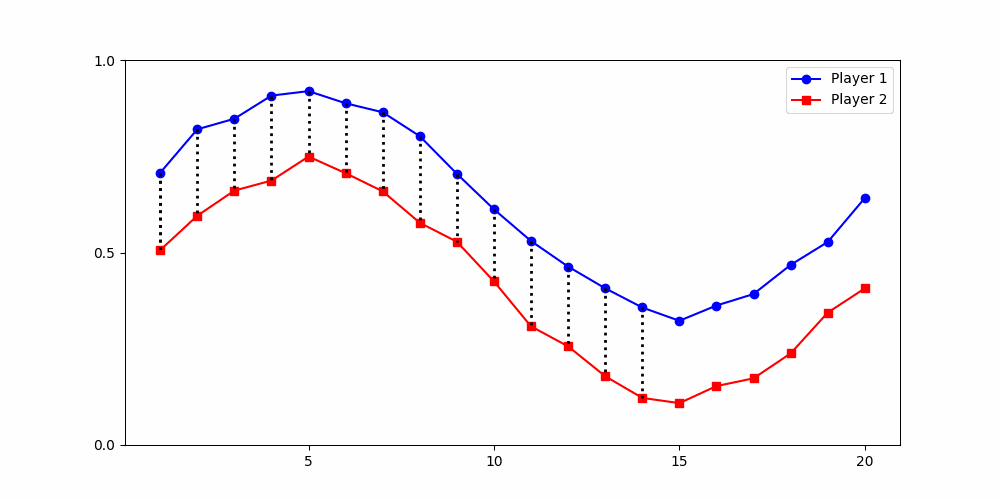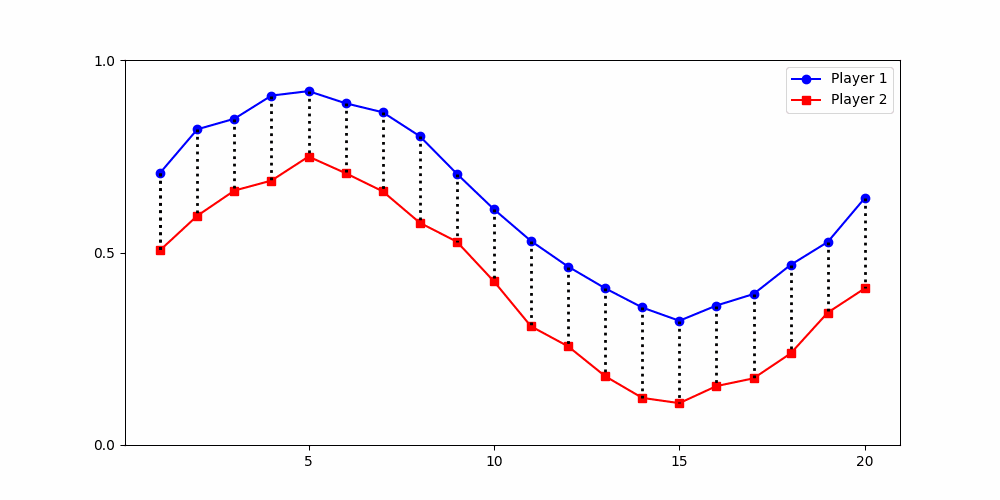
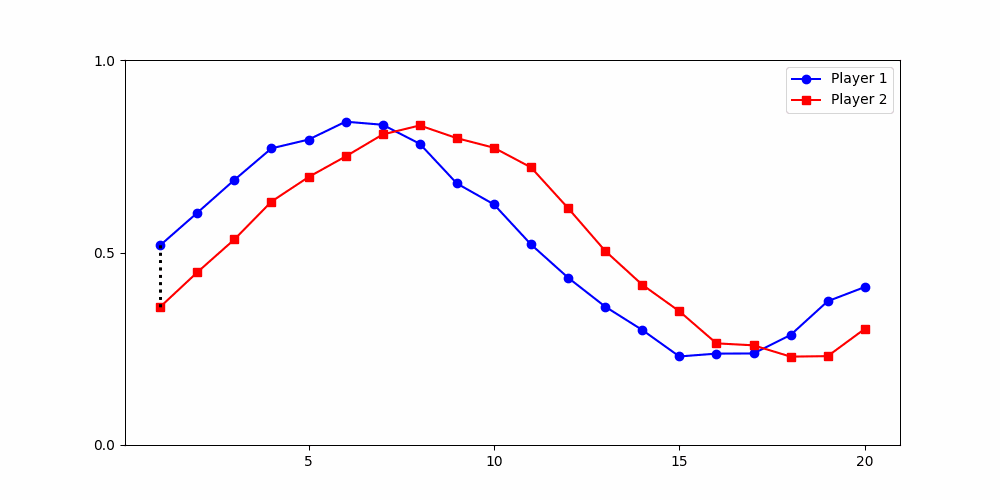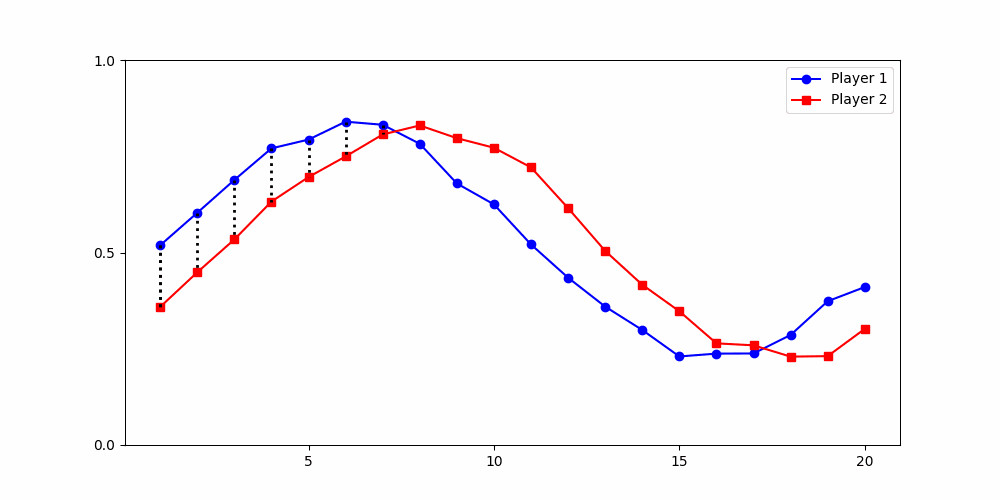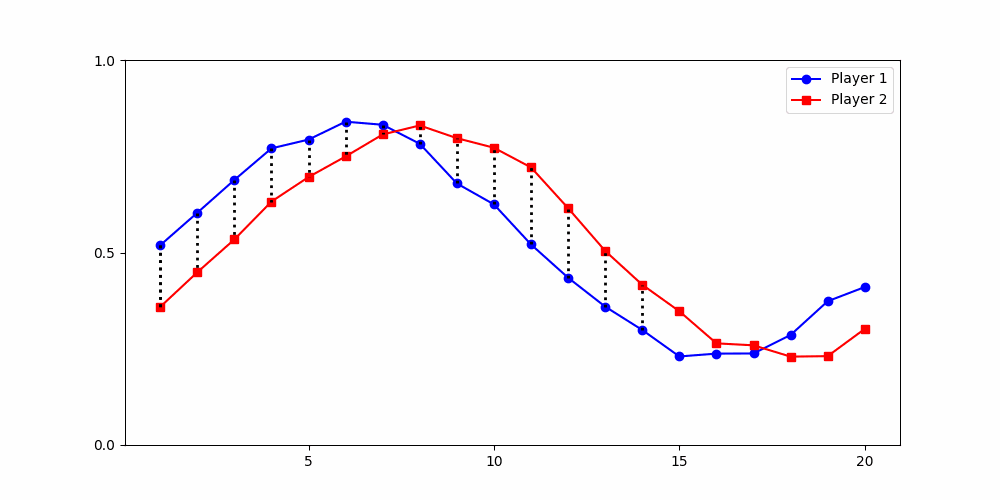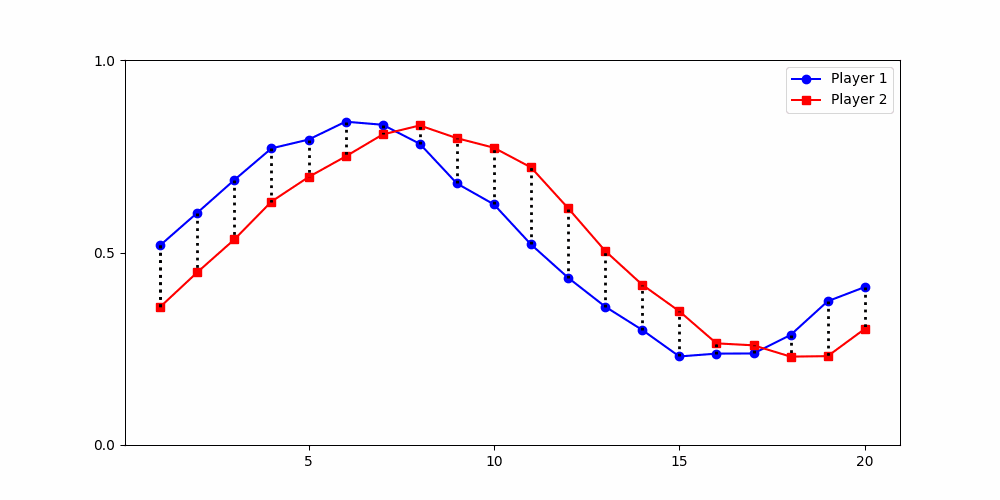
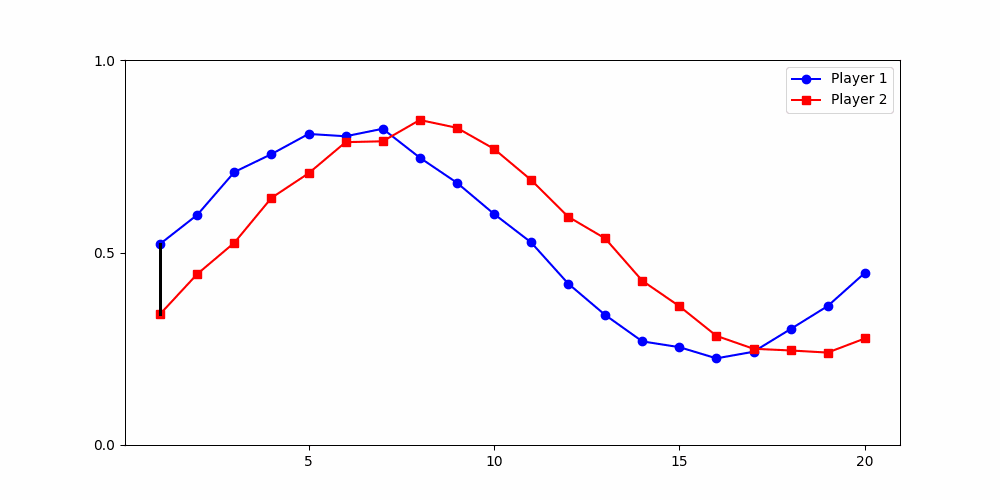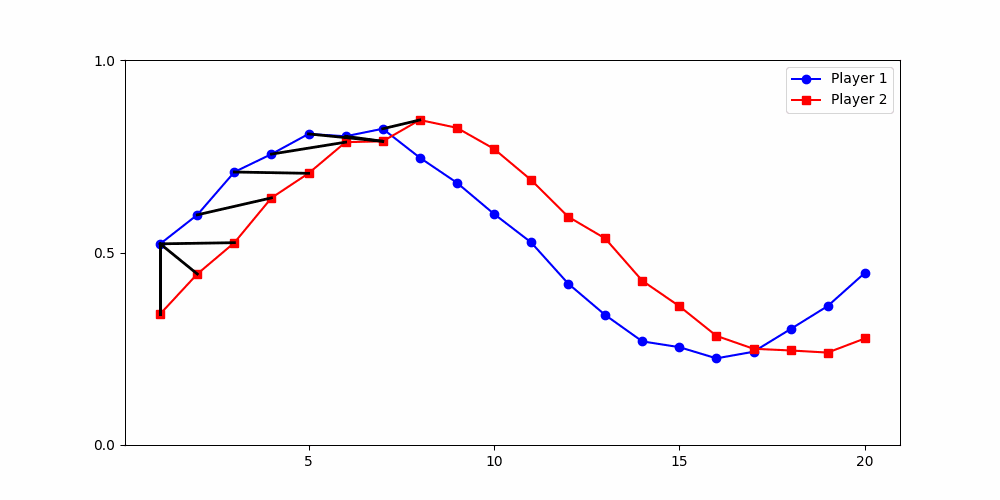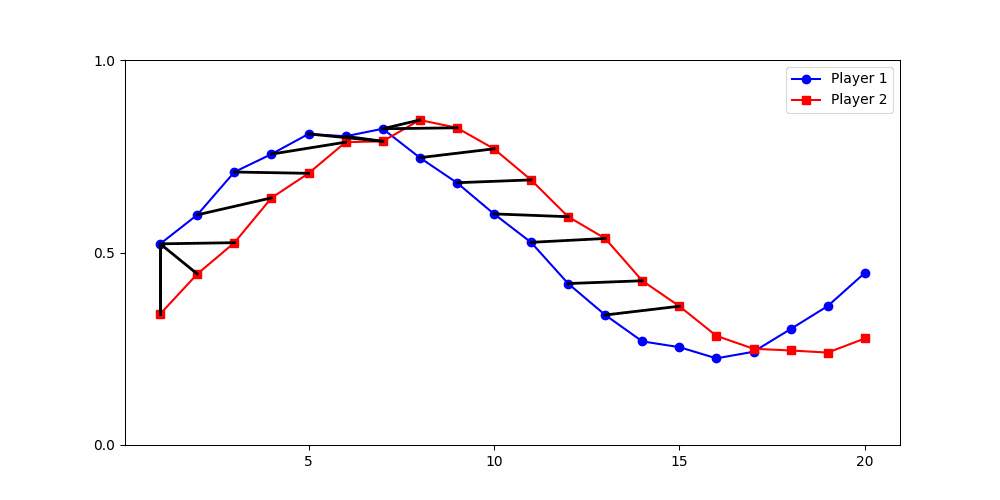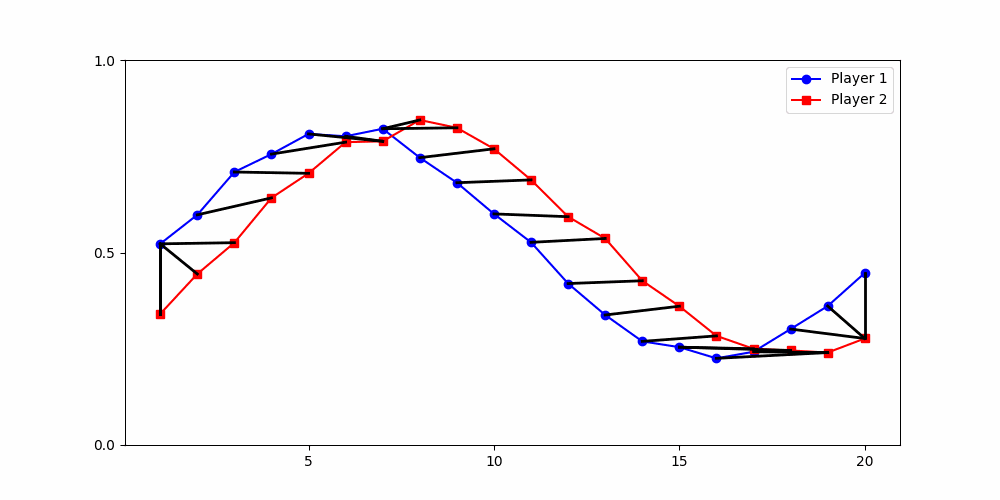
Finds the best match between similar patterns
Does not force strict x-alignment.
Local Similarity Measure
Global Similarity Measure
Dynamic Time Warping (DTW)
Euclidean Distance
Local Similarity Measure
Global Similarity Measure
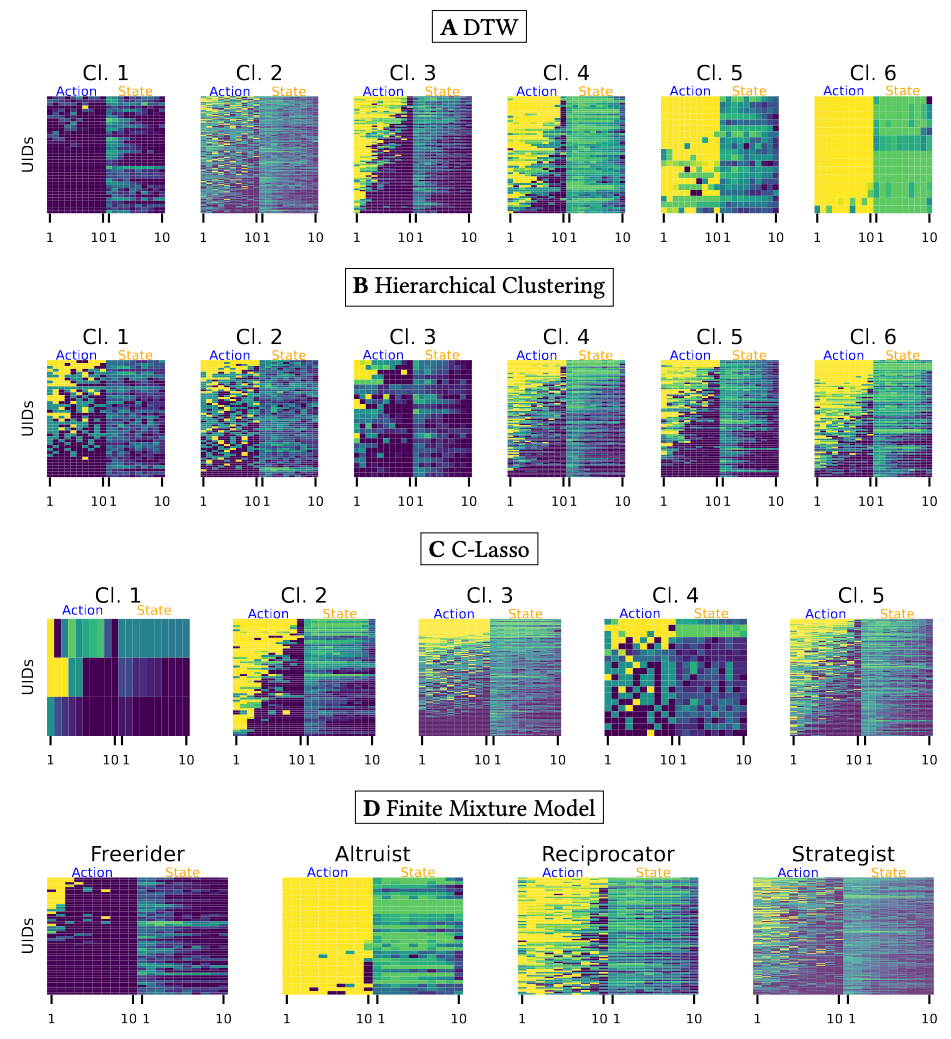
Results depend fundamentally on how similarity is defined
The way we measure differences between time series is not neutral — it encodes our theoretical assumptions about what counts as meaningful variation.
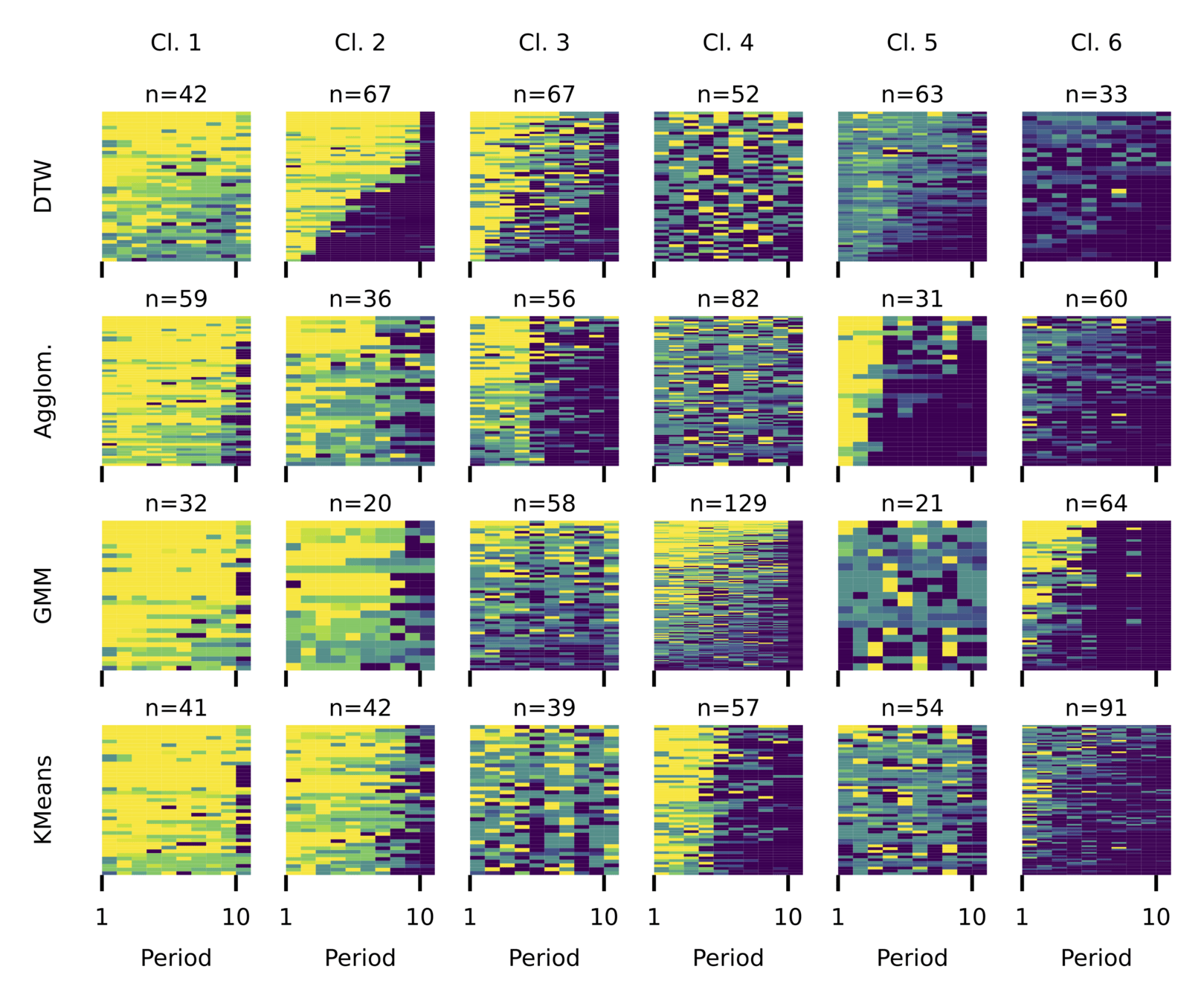
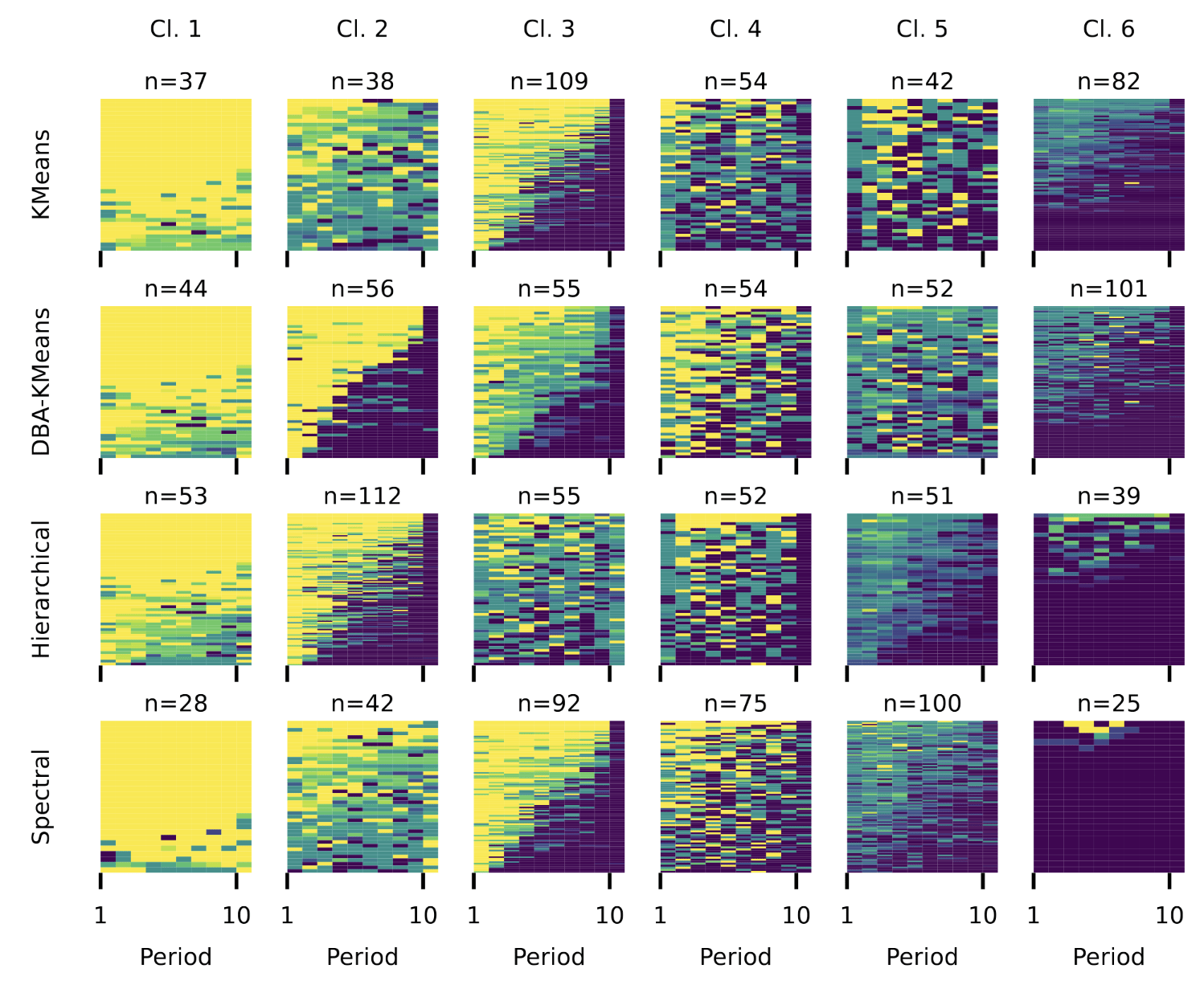
Agglom
GMM
k-means
Agglom
GMM
k-means
DTW
Euclidean
k-means
uids
round
global
local
Agglom
GMM
k-means
DTW
Euclidean
k-means
highest
mean contribution
lowest
mean contribution
DTW
Euclidean
DTW
Euclidean
Results depend fundamentally on how similarity is defined.
We focus on generalizable patterns that hold despite idiosyncratic group differences and varying game lengths.
→ Not “people switch in round 5”
→ But: a tipping point emerges after which contributions remain low.
DTW
Euclidean
Results depend fundamentally on how similarity is defined.
We focus on generalizable patterns that hold despite idiosyncratic group differences and varying game lengths.
→ Not “people switch in round 5”
→ But: a tipping point emerges after which contributions remain low.
Theory Driven
Data Driven
Manhattan +
Finite Mixture Model
Bayesian Model
C-Lasso
DTW +
Spectral Clustering
Hierarchical Clustering
Theory Driven
Data Driven
Finite Mixture Model
C-Lasso
DTW Distance
Manhattan Distance
Finite Mixture Model
C-Lasso
DTW
Local
Clustering
Step 1
Clustering
→ uncover patterns
Step 2
Inverse Reinforcement Learning
→ interpret patterns
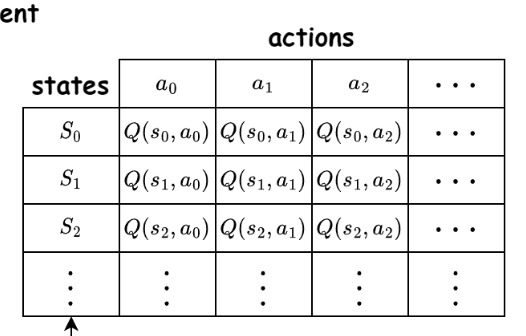
The key challenge is to define a reward function.
Inverse RL recovers reward functions from data.
Hierarchical Inverse Q-Learning
18.5%
24%
32%
16.5%
random / unexplained
Hierarchical Inverse Q-Learning
action
state
\( Q(s,a) = (1- \alpha) Q(s,a) + \alpha \left( r + \gamma \max Q(s', a') - Q(s,a) \right) \)
Expected best possible outcome from the next state
Compare to now
re-ward
Hierarchical Inverse Q-Learning
action
state
to act optimally over time without solving the full Bellman equation upfront
Very intuitive for modeling boundedly rational players in repeated games
\( Q(s,a) = (1- \alpha) Q(s,a) + \alpha \left( r + \gamma \max Q(s', a') - Q(s,a) \right) \)
Hierarchical Inverse Q-Learning
\( Q(s,a) = (1- \alpha) Q(s,a) + \alpha \left( r + \gamma \max Q(s', a') - Q(s,a) \right) \)
re-ward
action
state
Estimate the reward function by maximizing the likelihood of observed actions and states.
unknown
Hierarchical Inverse Q-Learning
action
state
Instead of learning Q-values from rewards, we observe actions and states and try to infer what reward function the agent must be optimizing.
Hierarchical Inverse Q-Learning
\( r_{t-1} \)
\( a_{t-1} \)
P
\( s \)
\( \Lambda \)
\( r_t \)
\( a_t \)
P
\( s_{t+1} \)
discrete transition
Hierarchical Inverse
Q-Learning
\( P(r_t \mid s_{0:t}, a_{0:t}) \)
action
state
\( r \)
\( r_{t-1} \)
\( \Lambda \)
\( r_t \)
1
2
3
4
→ 2
→ 3
→ 4
→ 5
0.6
0.4
0.2
0.2
75.2
88.6
101.5
114.4
\( \Delta \) Test LL
\( \Delta \) BIC
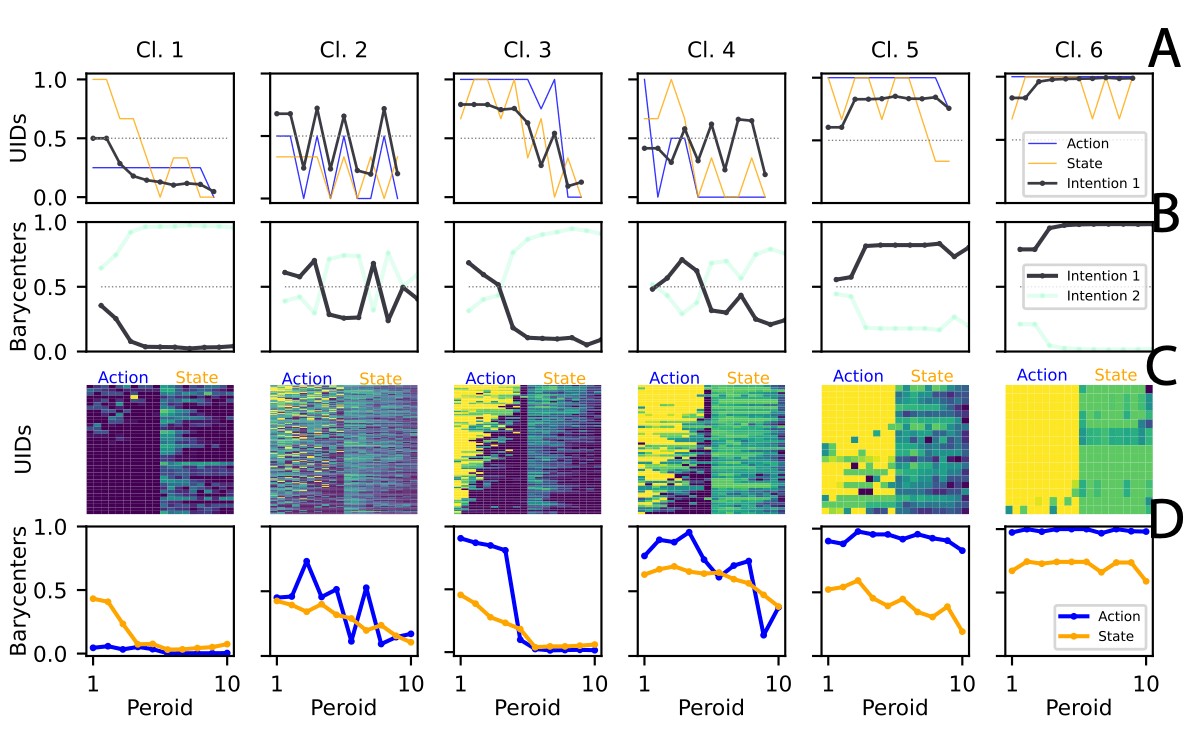
Choice of two intentions aligns with the fundamental RL principle of exploration vs. exploitation.
Unconditional
Cooperators
Consistent
Cooperators
Threshold
Switchers
Freeriders
Volatile
Explorers
Freeriders
Consistent Cooperators
carinah@ethz.ch
slides.com/carinah
S
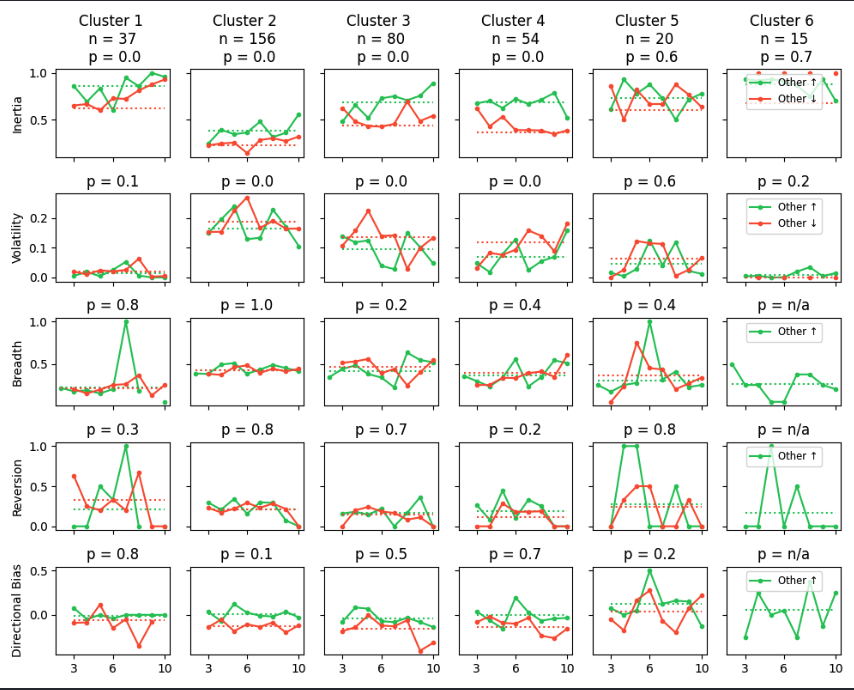
We find that partitioning the data using spectral clustering with DTW distance yields the cleanest and least noisy clusters.
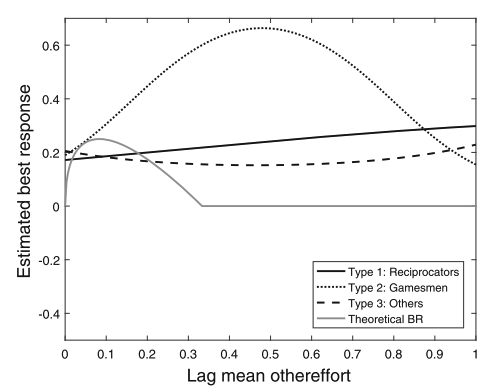
Individuals display higher inertia when others ↑ as opposed to other↓
Adjustments exhibit greater variability following other↓ as opposed to others ↑
Agglom
GMM
k-means
DTW
Euclidean
k-means
highest
mean contribution
lowest
mean contribution
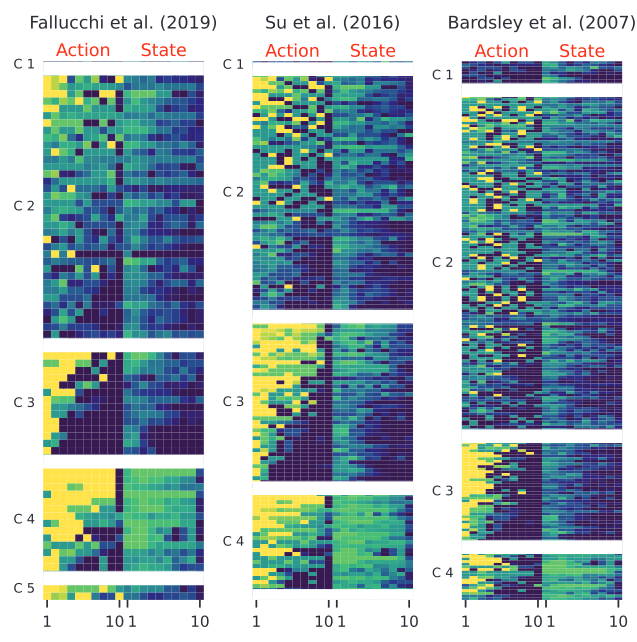
Data-Driven Approaches
Theory-driven classifications may not accurately capture the heterogeneity observed.
Theory-Based Approaches
Strategy-method types often align with actual gameplay data
(e.g. Muller 2008).
Strong assumptions on decision-making :
Detect behavioral patterns without assumptions.
Use RL to derive a policy that maximizes agents' intrinsic motivation for sustainable behavior.
Simulate an economy to study emergent dynamics.
Existing simulations lack grounding in behavioral types (e.g., research on cooperation).
Incorporating behavioral types could improve simulations.
Tailored policies—potentially even type-specific—may lead to better outcomes.
Hierarchical Inverse Q-Learning
action
state
\( Q(s,a) = (1- \alpha) Q(s,a) + \alpha \left( r + \gamma \max Q(s', a') - Q(s,a) \right) \)
Expected best possible outcome from the next state
Compare to now
re-ward
Theory Driven
Data Driven
Data-Driven Approaches
Theory-Based Approaches
Theory-Based Approaches
Data-Driven Approaches
Action
State
Strategy Table Data
\( 21^{21} \approx 5.8 \times 10^{27} \)
\( (21 \times 21) ^{10 rounds} \)
Explanations
Social preferences
Confusion
Unexplained behavior due to strict theoretical assumptions and limited techniques for interpretation.
Reliance on perfect point-wise alignment
Two comparative observations
Intentions integrate actions and states.
Theory Driven
Data Driven
Bardsely (2006)| Tremble terms:
Random deviations that decline with experience: 18.5%.
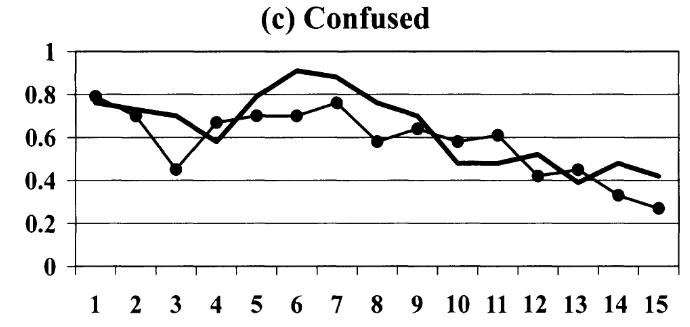
Houser (2004) | Confused:
High randomness and decision errors: 24%
Fallucchi (2021) |Others:
Neither reciprocation nor strategy: 22% – 32%
Fallucchi (2019) |Various:
Unpredictable contributions: 16.5%
By Carina Ines Hausladen

