








































Gerard Sans | Axiom 🇬🇧 PRO
Founder of Axiom Masterclass, professional trainings // Forging skills for the new era of AI. GDE in AI, Cloud & Angular. Building London's tech & art nexus @nextai_london. Speaker | MC | Trainer.
Spoken 213 times in 44 countries
x10
7
10
7
10
10:10
9:15
Messi
Ronaldo
Lisbon
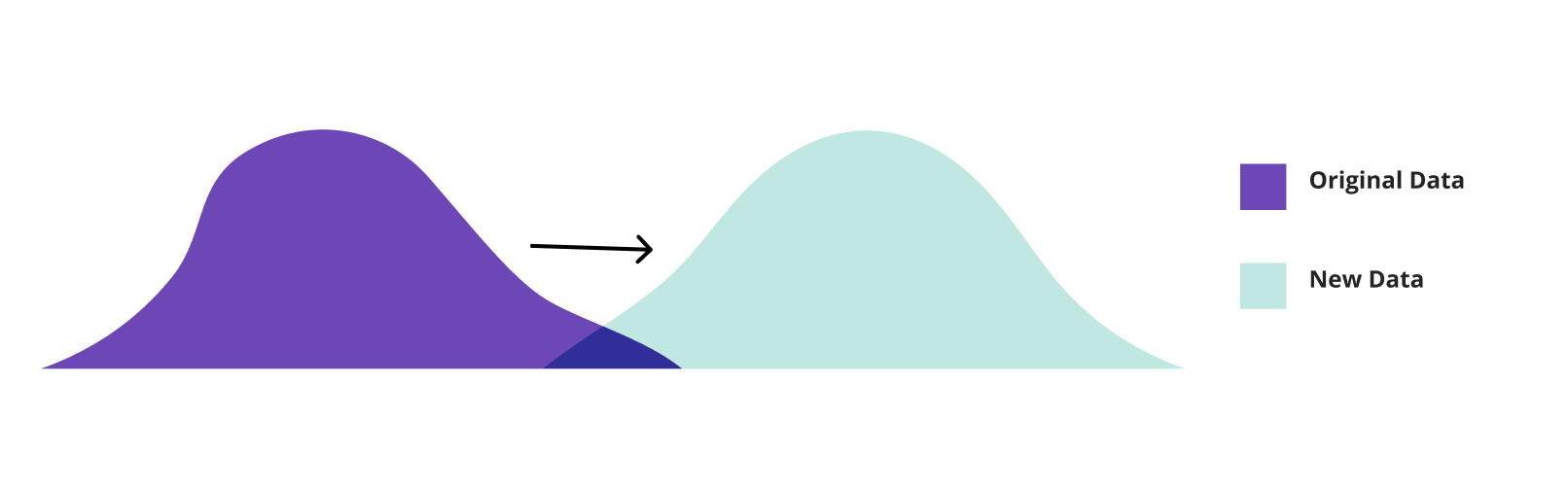
Distribution Drift
Original Prompt
New Prompt
1h
video
11h
audio
30K
LOC
800
pages
1 Million tokens
Vertex AI
Complexity
Features
1
2
Vertex AI
Complexity
Features
30 Natural Voices
+24 Languages
2-15min
Video
Attachments
Code Execution
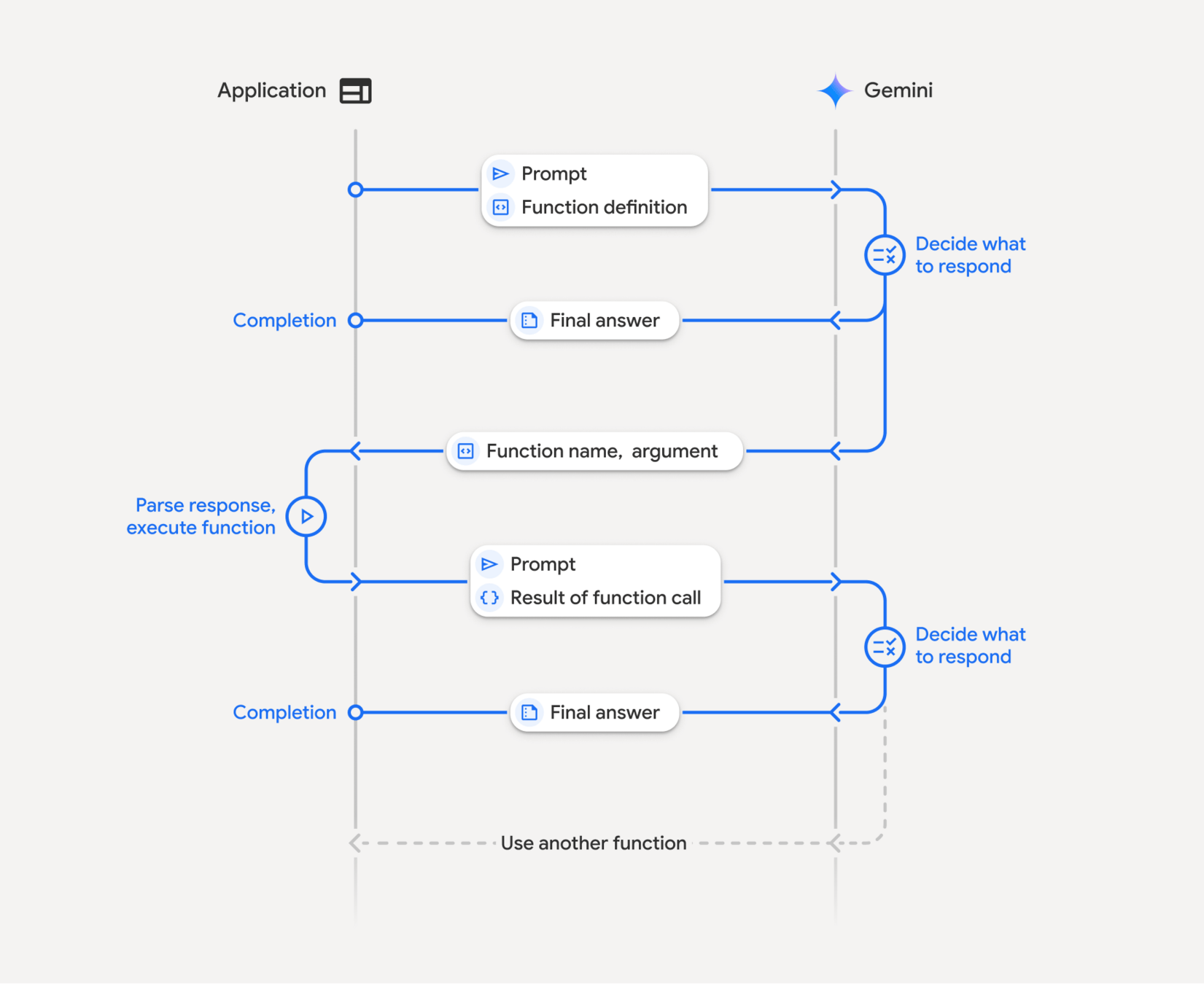
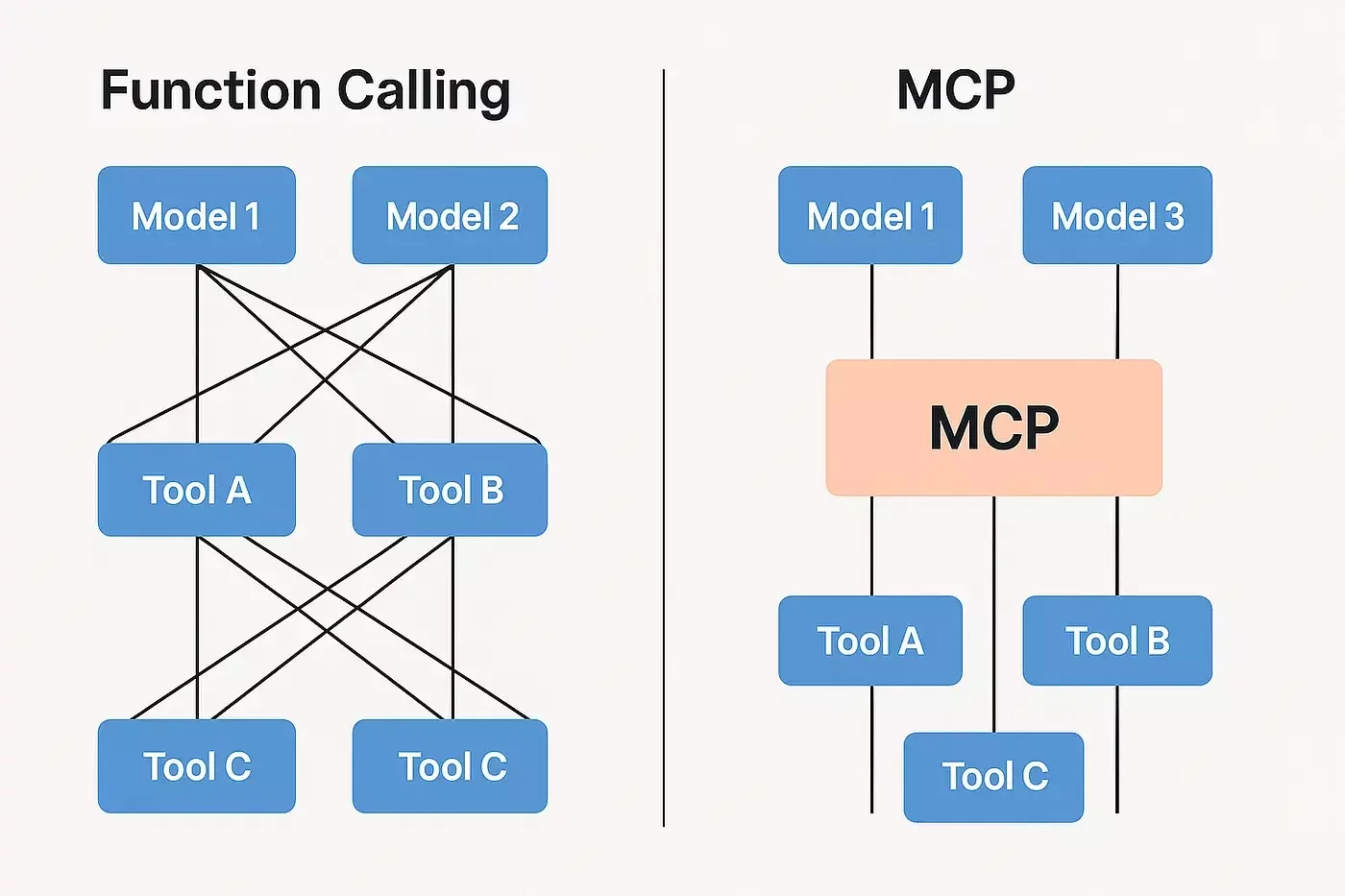
Function Calling
Web Search
Vertex AI
Complexity
Features
Python Sandbox
Google Search
Function
Calling
Context Agent
Priorisation
Agent
Execution Agent
User
Goal/Rules
Task Queue
Task
Task creation Agent
1. Provide objective
4. Complete task
6. Update tasks
2. Add new tasks
3. Query context
Memory
5. Store task/result
Tools
Real Time
Native Audio
200-600 ms
30 Voices
Interactive
Half-Cascade
500-800 ms
8 Voices
On Demand
Text-To-Speech
few seconds
30 Voices
Google Search
Run query in
Google Search
Model 2
Model 1
Model 2
Model 1
Scan to access Slides.
By Gerard Sans | Axiom 🇬🇧
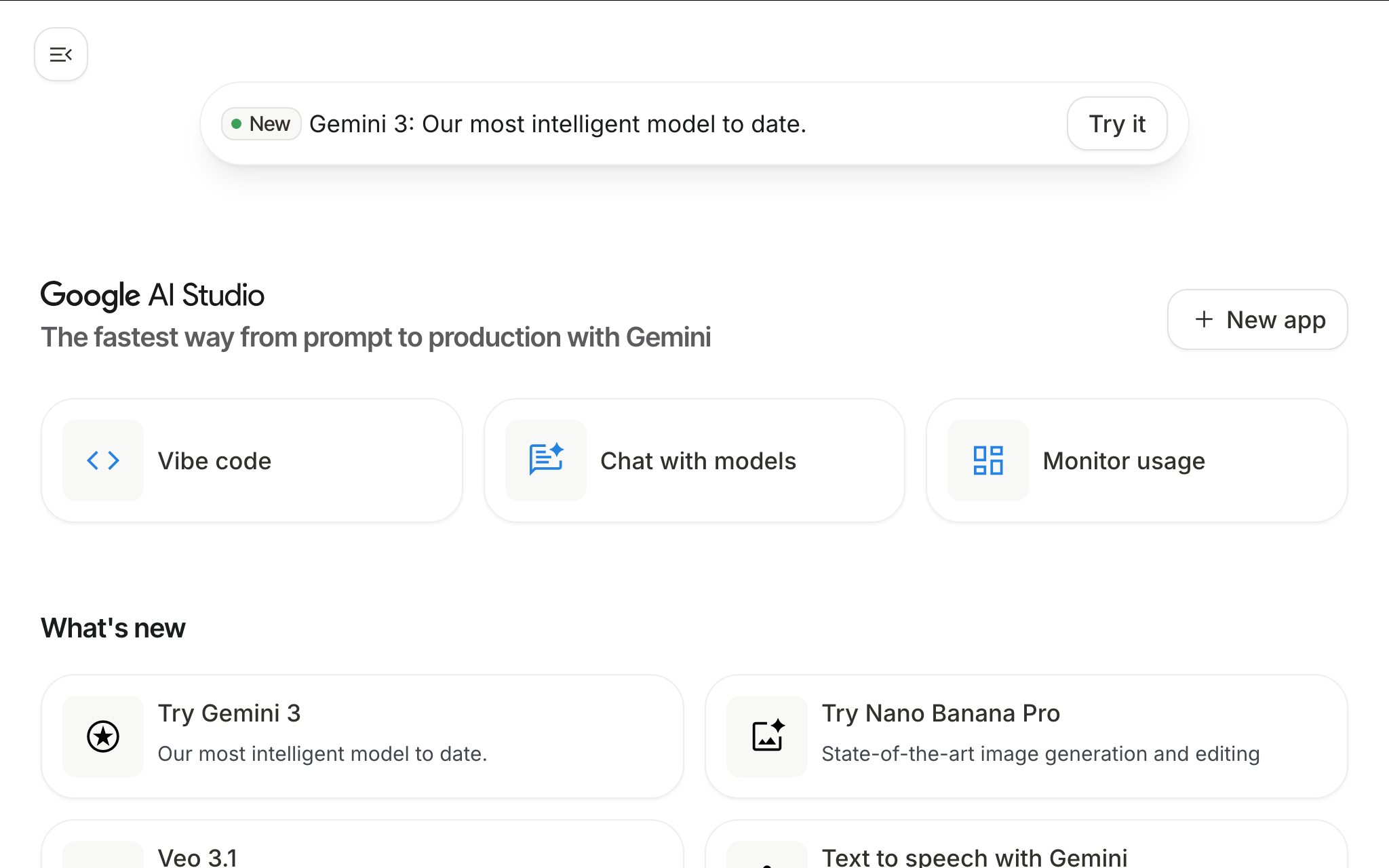
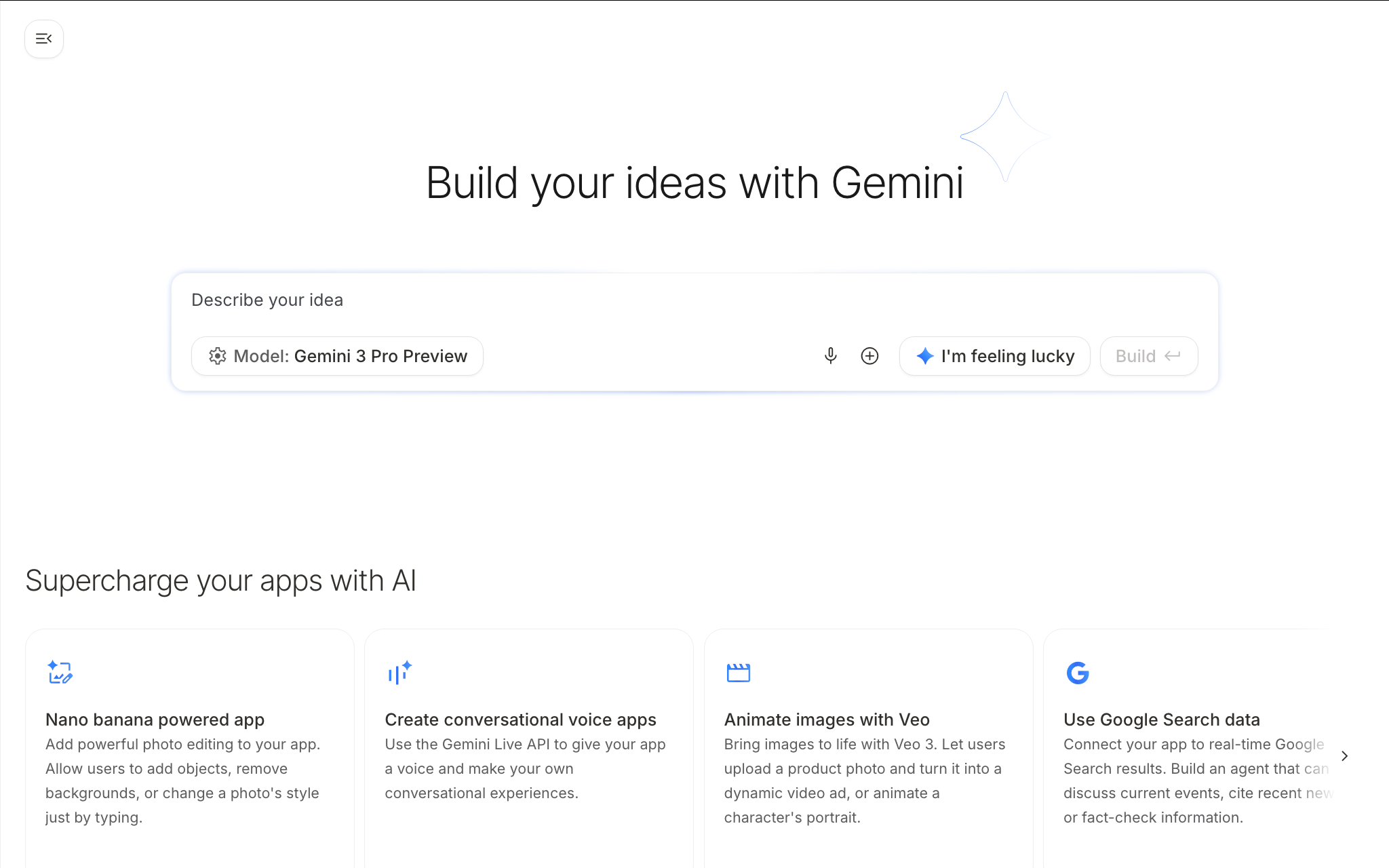
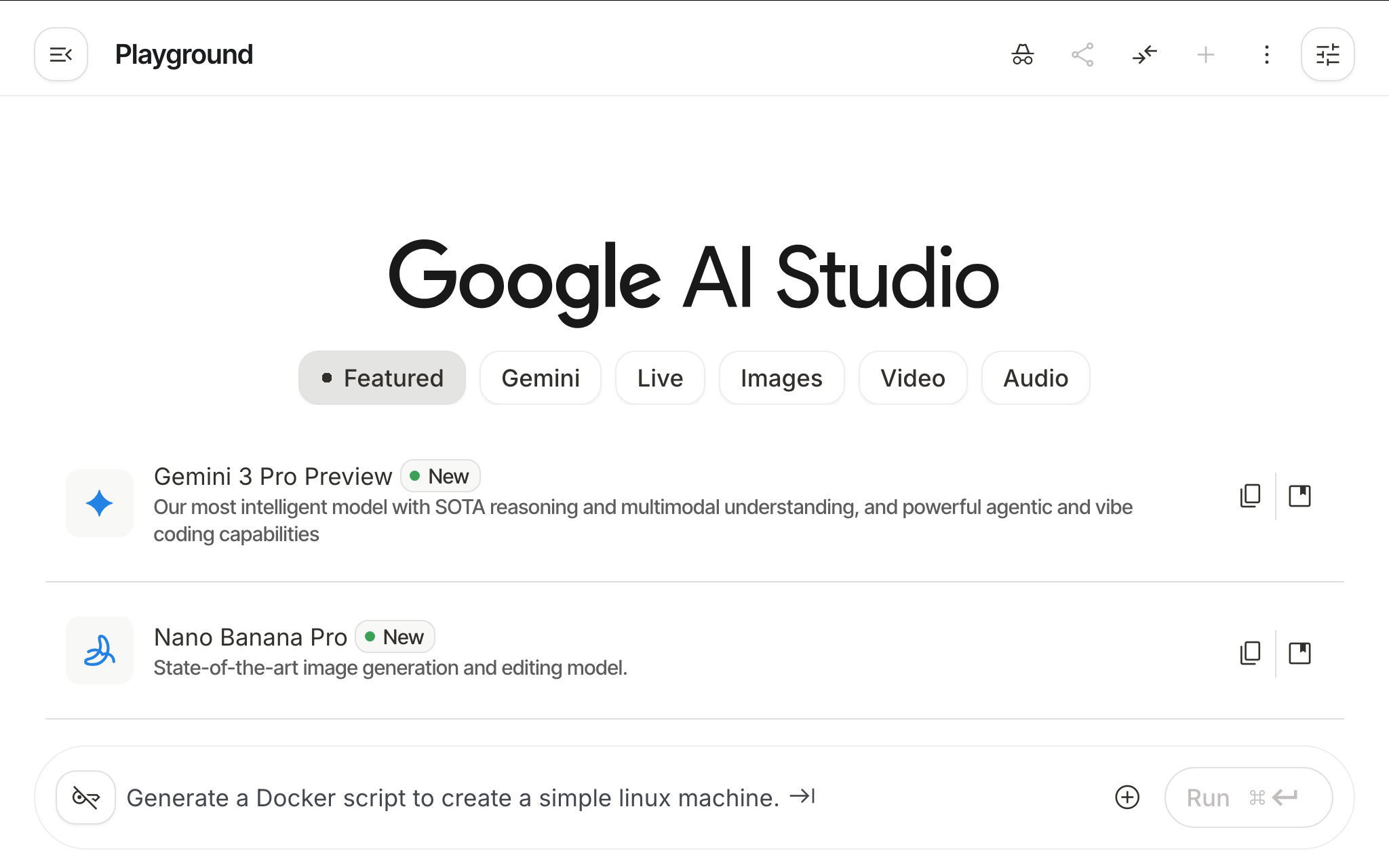
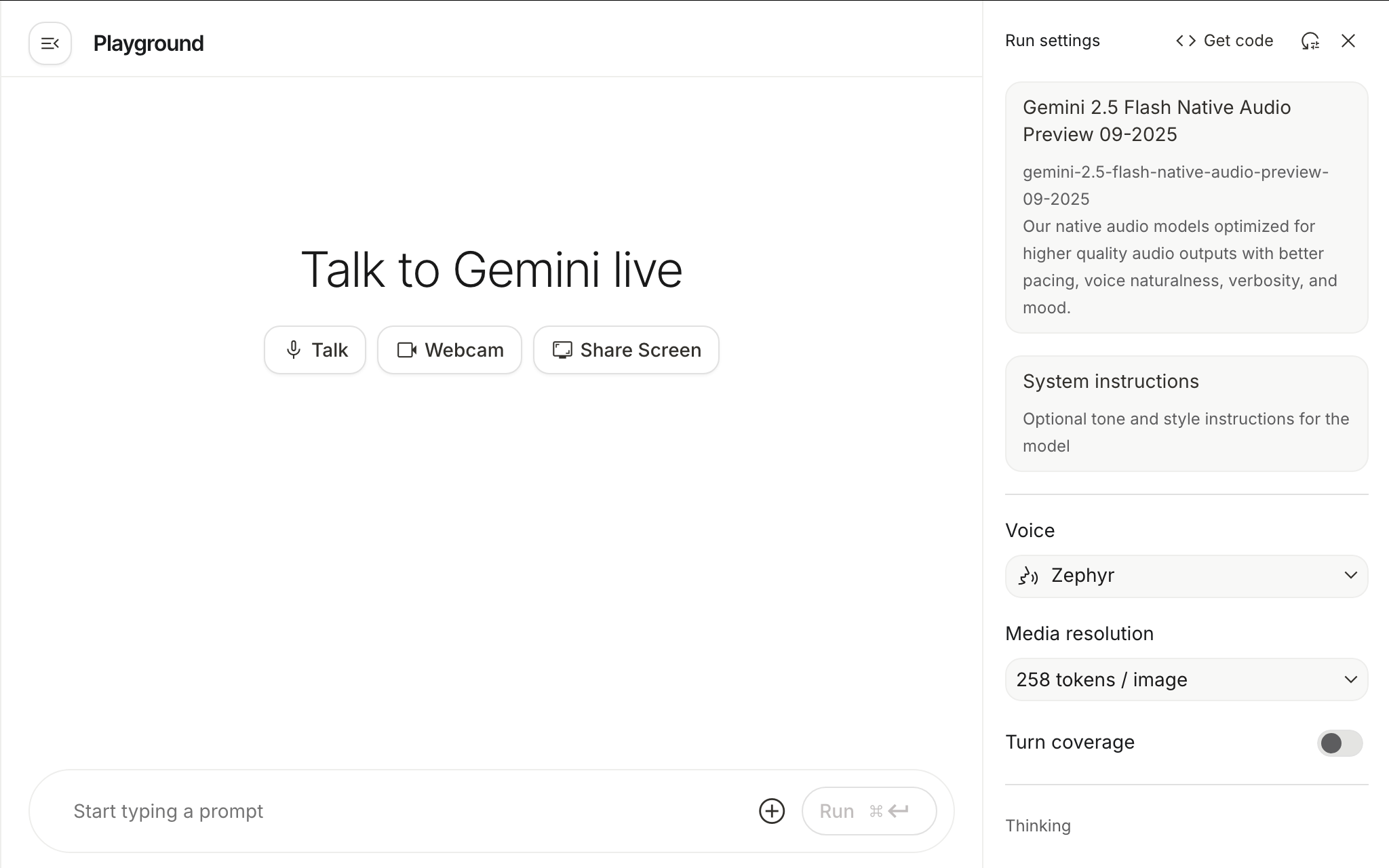
Generative AI has shifted gears. In this talk we explore how Gemini 3 Pro now supports multimodal generation (text, image, audio, video) and real-time agents. You’ll see how Google AI Studio connects the latest model families into a unified workflow of “vibe coding” rather than writing boilerplate. We’ll also dive into the voice-first capabilities made possible via the Gemini Live API: real-time, bidirectional voice and video conversations, tone-aware responses, tool-integration and session memory. Together we’ll look at prompt-to-code flows, media generation, voice-first use cases and the next generation of MCP-driven agentic AI.



