
















Content ITV PRO
This is Itvedant Content department
Learning Outcome
1
Understand the philosophy of "Density-Based" clustering over "Centroid-Based" clustering.
2
Understanding customer needs
3
Creating value for customers
4
Different marketing channels
5
Target audience and segmentation
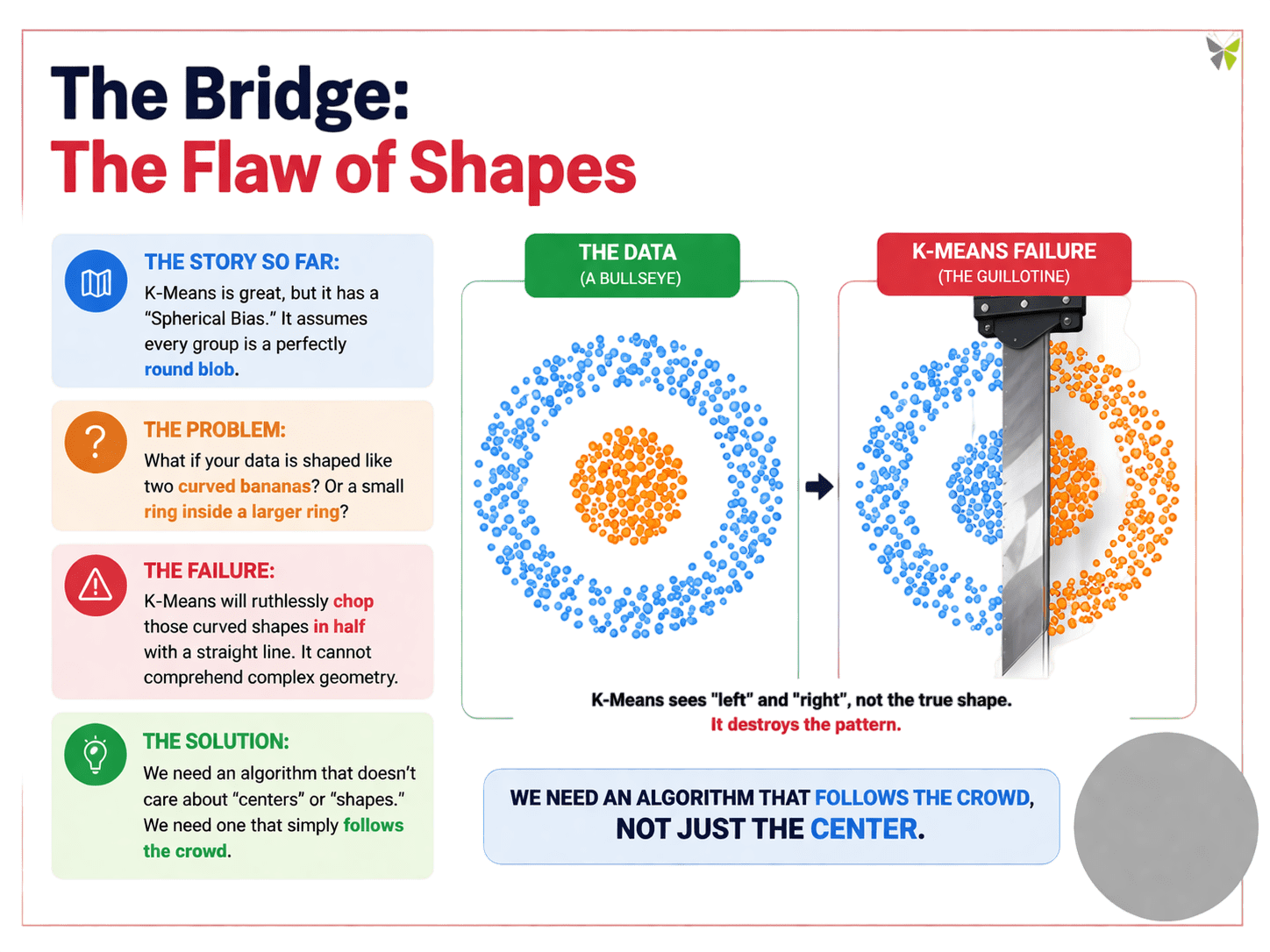
The Flaw of Shapes
The Story So Far
K-Means is great, but it has a "Spherical Bias." It assumes every group is a perfectly round blob.
The Problem
What if your data is shaped like two curved bananas? Or a small ring inside a larger ring?
The Failure
K-Means will ruthlessly chop those curved shapes in half with a straight line. It cannot comprehend complex geometry.
Data
K-mean Faliure
The Solution
We need an algorithm that doesn't care about "centers" or "shapes." We need one that simply follows the crowd.
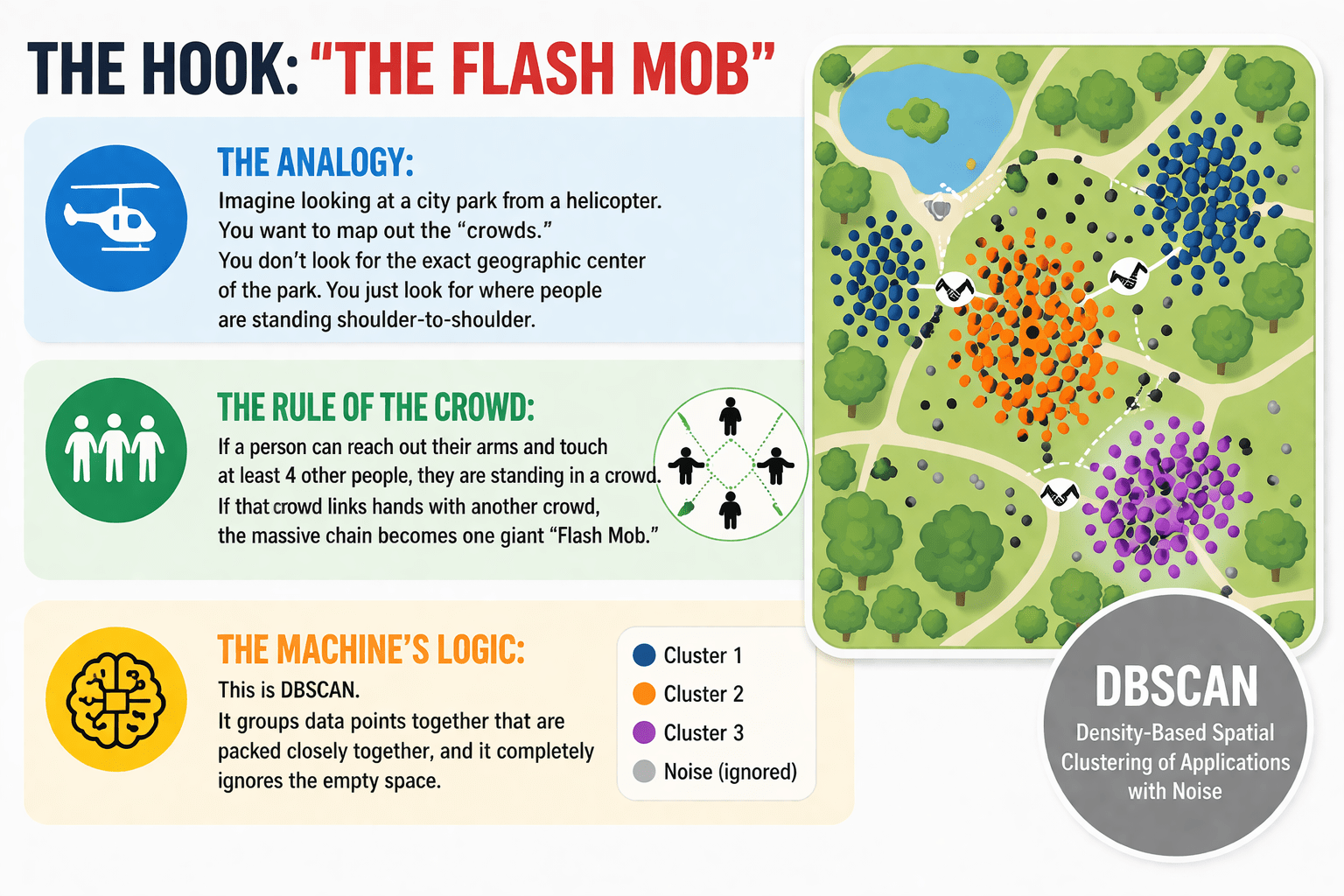
Imagine looking at a city park from a helicopter...
You want to map out the "crowds." You don't look for the exact geographic center of the park.
You just look for where people are standing shoulder-to-shoulder.
If a person can reach out their arms and touch at least 4 other people, they are standing in a crowd.
If that crowd links hands with another crowd, the massive chain becomes one giant "Flash Mob."
This is DBSCAN. It groups data points together that are packed closely together, and it completely ignores the empty space.
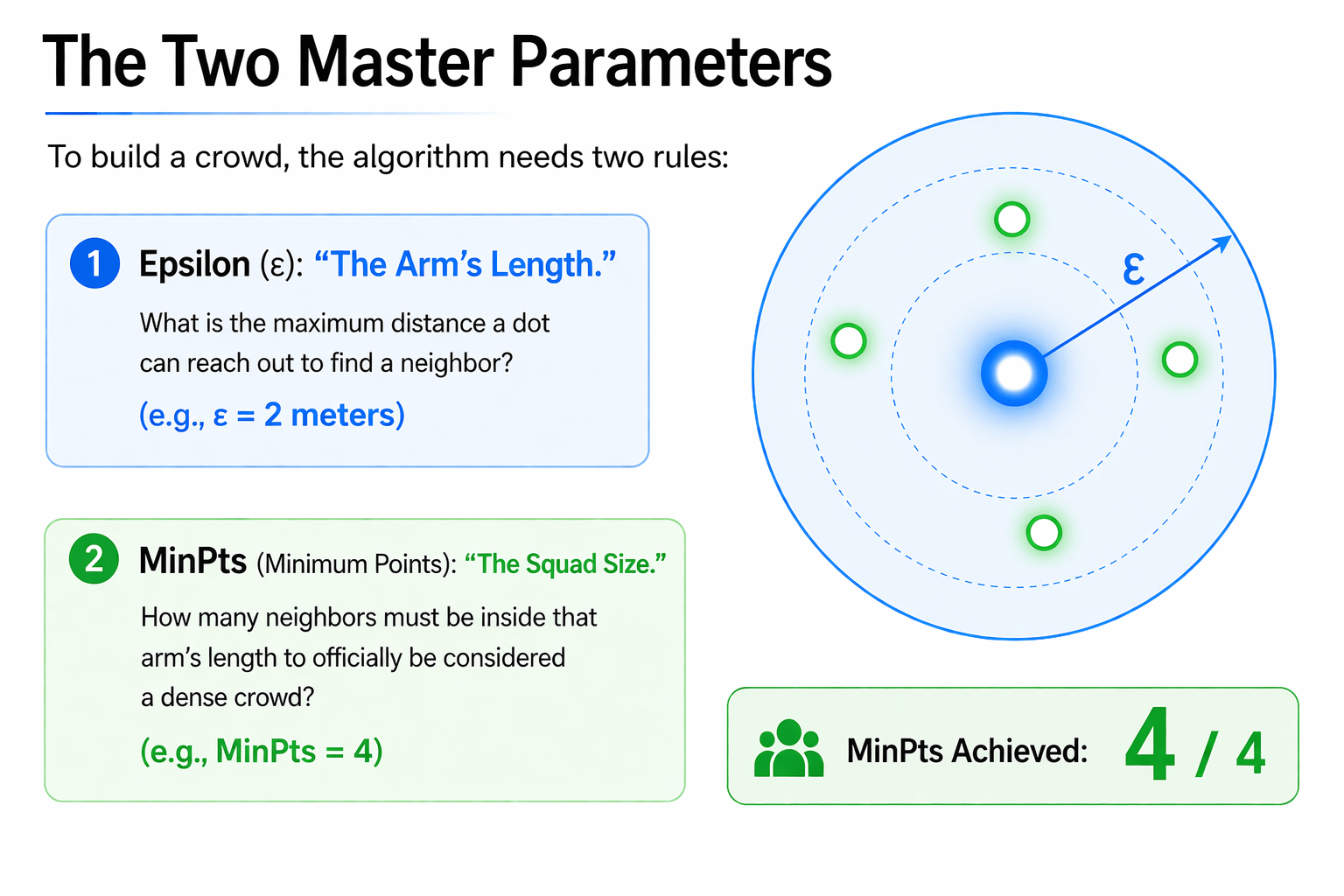
The Two Master Parameters
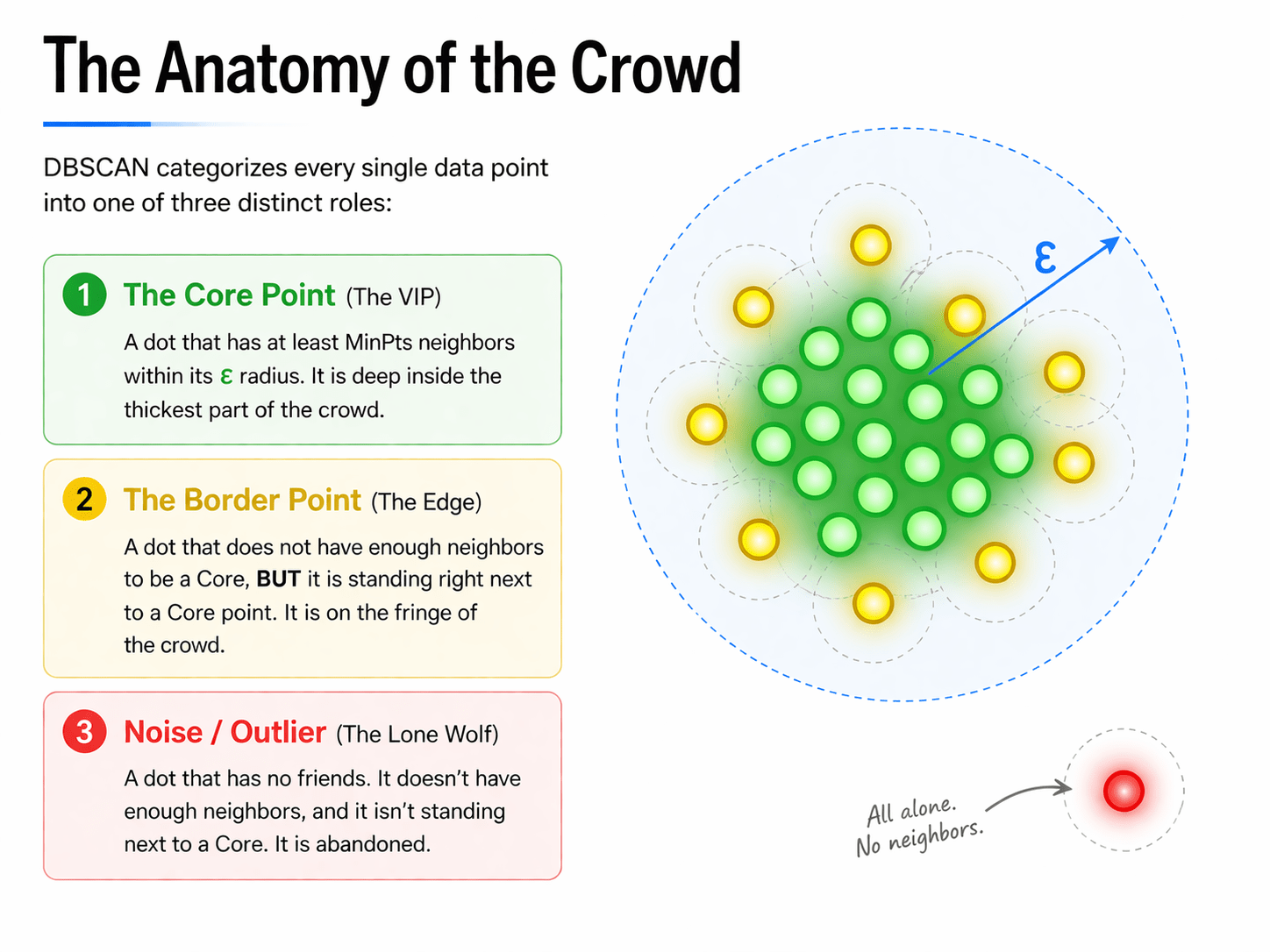
The Anatomy of the Crowd
DBSCAN categorizes every single data point into one of three distinct roles:
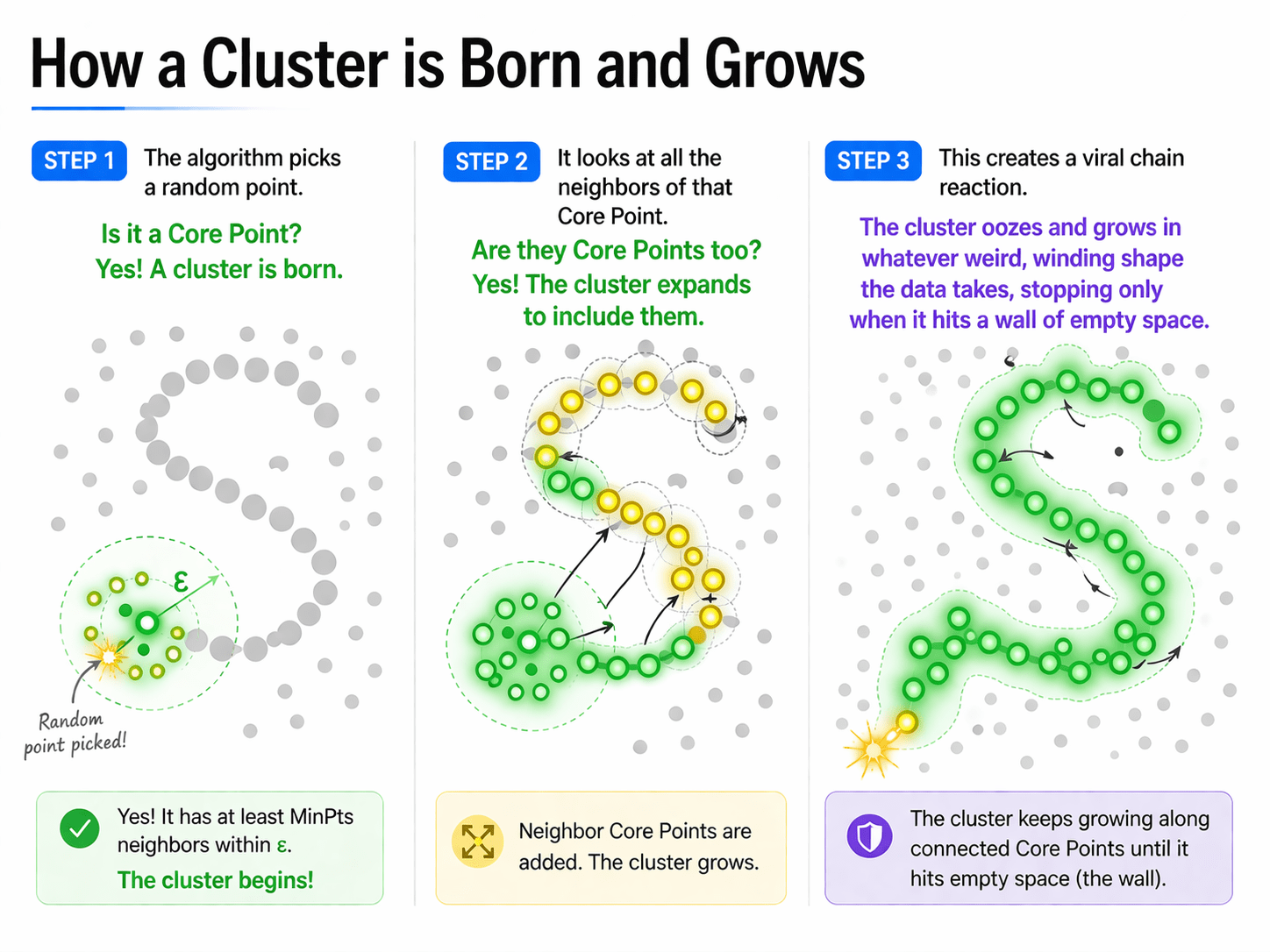
How the Cluster Grows
Step 1
The algorithm picks a random point.
Is it a Core Point?
Yes! A cluster is born.
Step 2
It looks at all the neighbors of that Core Point.
Are they Core Points too?
Yes! The cluster expands to include them.
Step 3
This creates a viral chain reaction.
The cluster oozes and grows in whatever weird, winding shape the data takes, stopping only when it hits a wall of empty space.
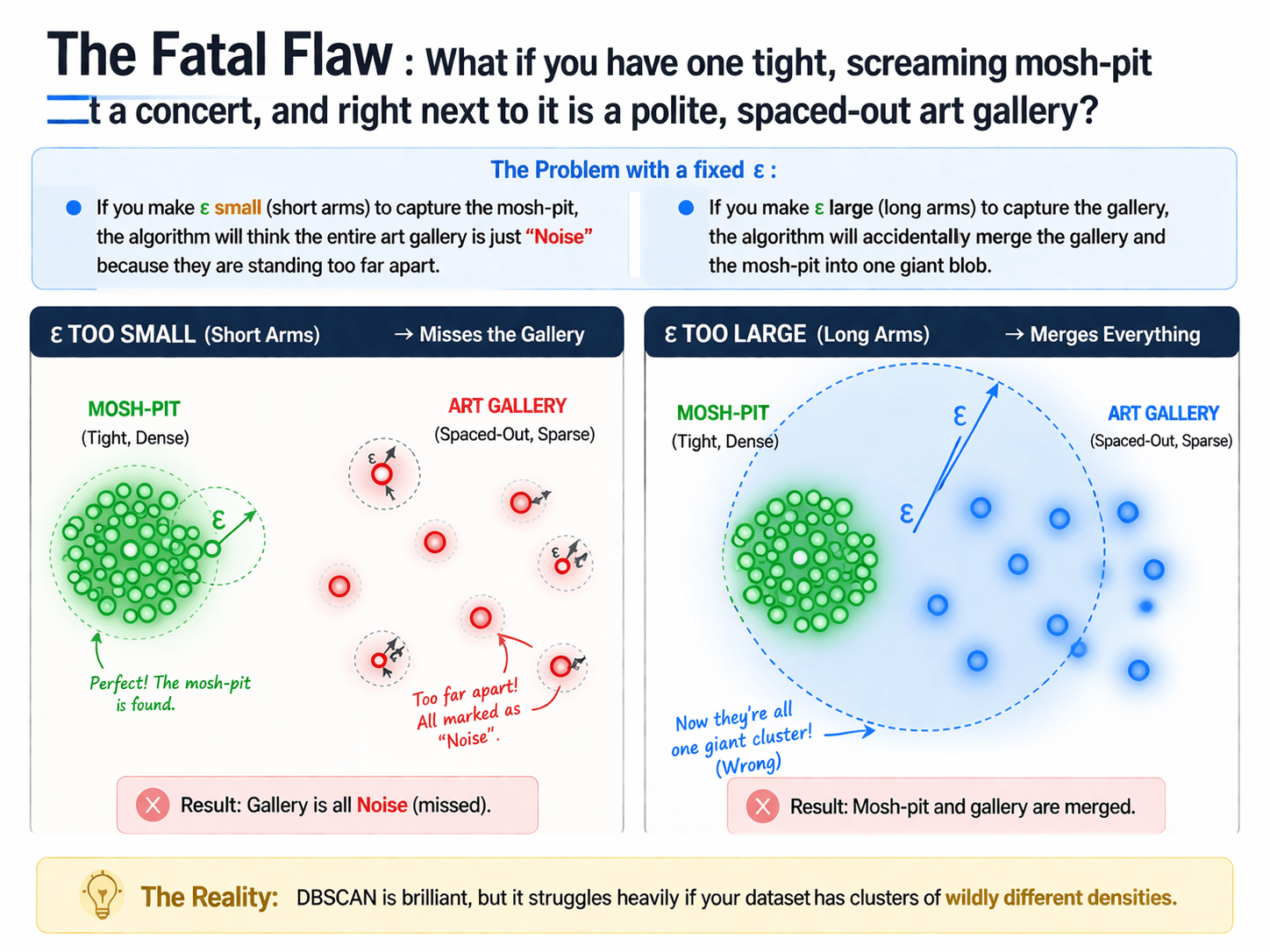
Varying Densities
What if you have one tight, screaming mosh-pit at a concert, and right next to it is a polite, spaced-out art gallery?
DBSCAN is brilliant, but it struggles heavily if your dataset has clusters of wildly different densities.
Pros & Cons
THE CONS
Varying Densities
Fails if clusters are not equally packed together.
Parameter Sensitivity
Choosing the exact right $\epsilon$ and MinPts is tedious.
Curse of Dimensionality
Distance metrics break down with too many features.
THE PROS
No 'K' Required
No need to guess the number of clusters in advance.
Shape Master
Can find clusters of any arbitrary shape (curves, rings).
Built-in Outlier Detection
Automatically identifies and isolates "Noise" points.
Summary
4
It easily conquers complex, non-circular shapes but struggles when clusters have wildly different densities
3
It classifies points as Core, Border, or Noise, naturally filtering out extreme outliers.
2
It requires two parameters: $\epsilon$ (reach radius) and MinPts (minimum neighbors).
1
DBSCAN clusters data based on Density (how closely packed the points are).
Quiz
In DBSCAN with MinPts = 5, if Point A has only 2 neighbors within ε but lies within the ε-neighborhood of a core point, how is Point A classified?
A. A Core Point
B. A Border Point
C. Noise (An Outlier)
D. A Centroid
Quiz-Answer
In DBSCAN with MinPts = 5, if Point A has only 2 neighbors within ε but lies within the ε-neighborhood of a core point, how is Point A classified?
A. A Core Point
B. A Border Point
C. Noise (An Outlier)
D. A Centroid
By Content ITV



